
Router-R1: Teaching LLMs Multi-Round Routing and Aggregation via Reinforcement Learning
Authors: Haozhen Zhang, Tao Feng, Jiaxuan You
Paper: https://arxiv.org/abs/2506.09033
Code: https://github.com/ulab-uiuc/Router-R1
HF: https://huggingface.co/collections/ulab-ai/router-r1-6851bbe099c7a56914b5db03
TL;DR
WHAT? The paper introduces Router-R1, a reinforcement learning (RL) framework that trains an LLM to act as an intelligent "orchestrator." This orchestrator learns to solve complex tasks by coordinating a pool of other specialized LLMs through a sequential, multi-round process. It interleaves internal reasoning ("think" actions) with dynamic model invocation ("route" actions), iteratively building a solution by synthesizing information from multiple sources.
WHY? This work moves beyond the limitations of traditional single-shot LLM routers, which assign a query to only one model. By treating routing as a sequential decision problem, Router-R1 can tackle complex, multi-hop reasoning that requires the complementary strengths of diverse models. From a certain perspective, this elevates the routing concept from a low-level efficiency trick (like in Mixture-of-Experts) to a high-level cognitive strategy, akin to a "Mixture-of-Agents." Its novel, lightweight reward system, which includes a cost component, enables the optimization of both performance and computational expense. Furthermore, Router-R1 demonstrates strong generalization to new, unseen LLMs without retraining, making it a highly adaptable and practical solution for dynamic, real-world AI ecosystems.

Details
The proliferation of diverse Large Language Models (LLMs) has created a powerful, yet fragmented, ecosystem. To navigate this, LLM routers have emerged to dispatch user queries to the most suitable model. However, they have largely operated on a simple principle: one query, one model. To address the shortcomings of this single-shot approach, the authors of Router-R1 propose a significant paradigm shift from static dispatch to dynamic orchestration.
A New Paradigm: The LLM as the Orchestrator
The core innovation of Router-R1 is its architecture: the router is not a separate, simplistic algorithm but a capable LLM itself. This design choice transforms routing from a single decision into a sequential problem-solving process. The Router-R1 model learns to interleave two fundamental actions (Figure 1):
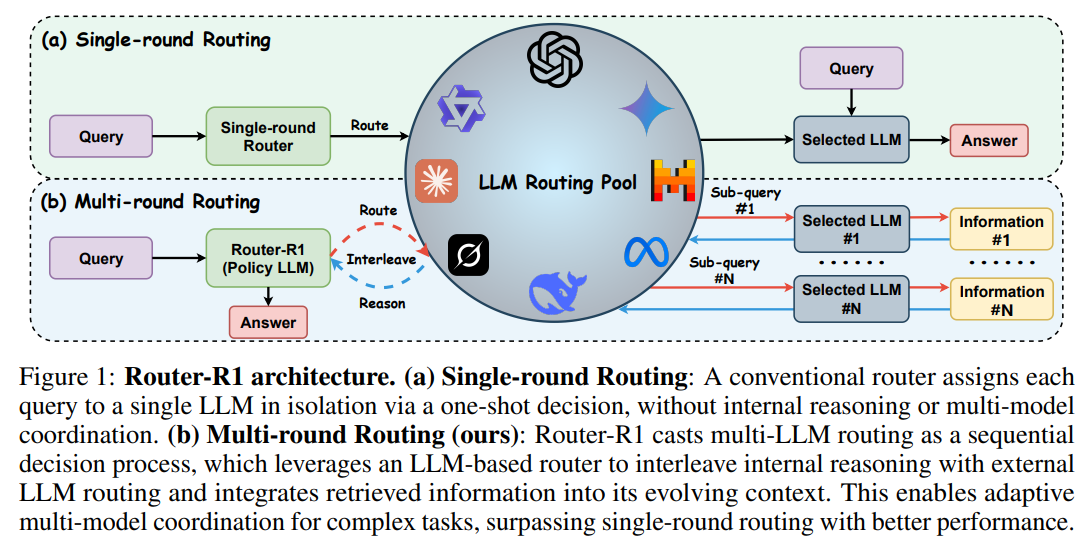
"Think": Internal deliberation where the router analyzes the current state of the problem, assesses what information is missing, and plans its next move.
"Route": Dynamic invocation of an external, specialized LLM from a predefined pool to gather specific information or perform a sub-task.
By formulating the task as a sequential decision process, Router-R1 can iteratively decompose a complex query, consult multiple "expert" LLMs, and integrate their responses into an evolving context to construct a final, comprehensive answer. This approach is a natural fit for multi-hop question answering and other intricate reasoning tasks where a single model's perspective is insufficient.
Methodology: Learning to Strategize with RL
To teach the router this complex behavior, the authors employ reinforcement learning (RL), a well-suited choice for optimizing the inherently non-differentiable decisions of which model to call at each step. The learning is guided by a simple yet highly effective rule-based reward function (Equation 5) whose true cleverness lies in its hierarchical structure. It is composed of three key elements:
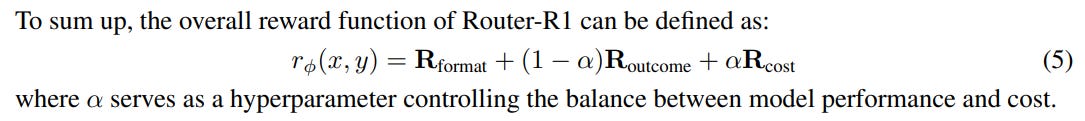
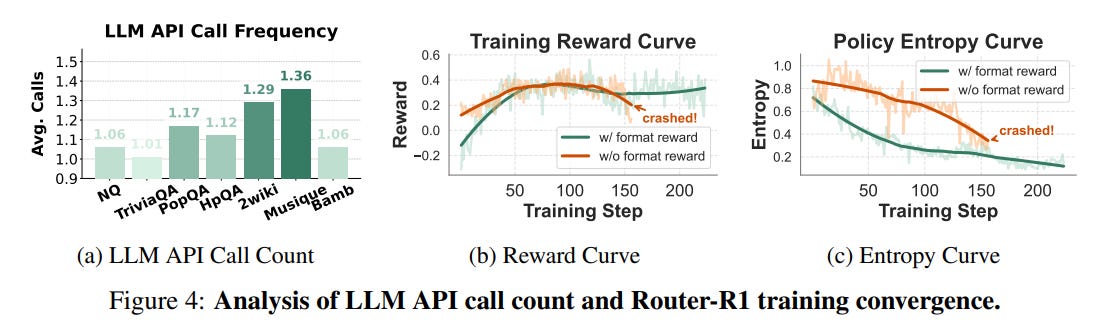
Format Reward: This acts as a critical gatekeeper. A strict structural reward ensures the model's output adheres to the required
think/route/info/answerformat. The authors implement a priority system: a negative reward for malformed output immediately zeroes out the other rewards for that step. This simple but critical design choice forces the model to first learn the correct action structure before it can optimize for correctness or cost, effectively stabilizing the entire learning process (Figure 4).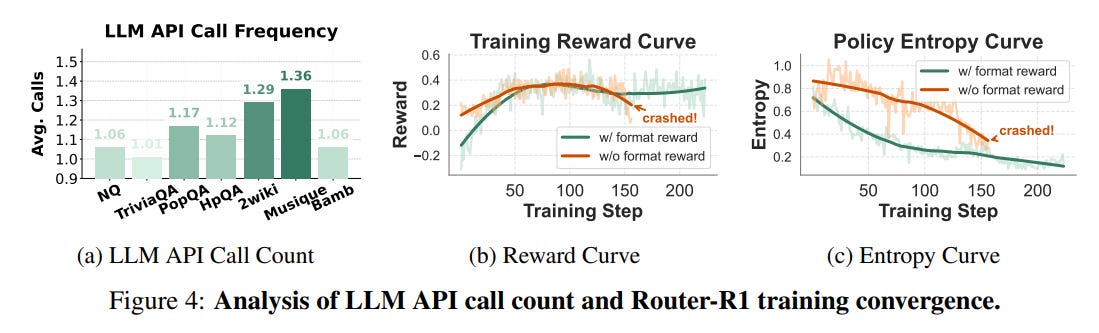
Outcome Reward: A standard reward based on the final answer's correctness, using Exact Match (EM) to guide the model toward accurate solutions.
Cost Reward: A novel and practical component that penalizes the use of computationally expensive LLMs. This reward is inversely proportional to the cost of the invoked model, encouraging the router to learn a resource-efficient policy.
Router-R1's ability to generalize to new models is more than just reading a label. While it starts with simple text descriptors (e.g., price, size, capabilities), the RL training process allows the router to learn the practical meaning of these descriptions through interaction and feedback. It runs experiments, observes the outcomes, and gradually builds an internal model of each LLM's true strengths and weaknesses, enabling it to make surprisingly effective use of new, unseen "experts" at inference time.
Experimental Results: Performance, Cost-Efficiency, and Generalization
The empirical evaluation demonstrates the effectiveness of the Router-R1 framework across seven diverse question-answering datasets.
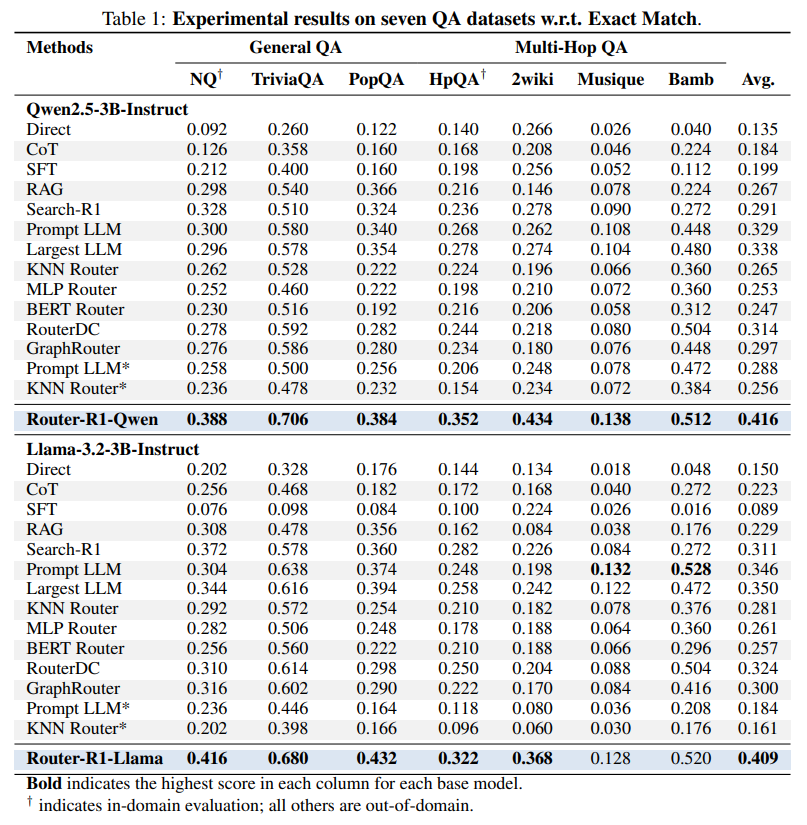
Superior Performance: Router-R1 consistently outperforms a wide range of baselines, including direct inference, Chain-of-Thought (https://arxiv.org/abs/2201.11903), RAG, and numerous single-shot LLM routers like GraphRouter (https://arxiv.org/abs/2410.03834) and RouterDC (https://arxiv.org/abs/2409.19886). For instance, the Router-R1-Qwen model achieved an average Exact Match score of 0.416, significantly higher than its competitors (Table 1). While the performance gains are impressive, the paper does not provide statistical significance tests or error bars, which would further strengthen these quantitative claims.
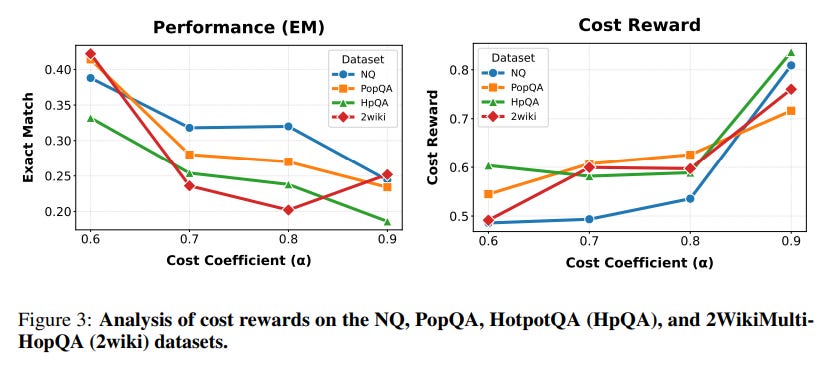
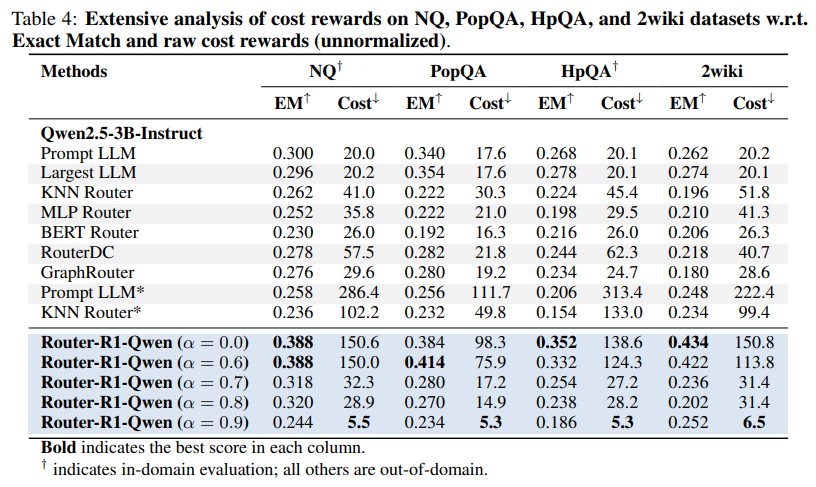
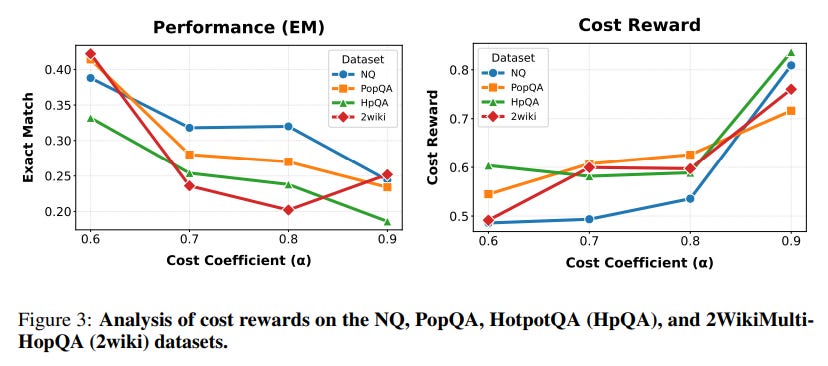
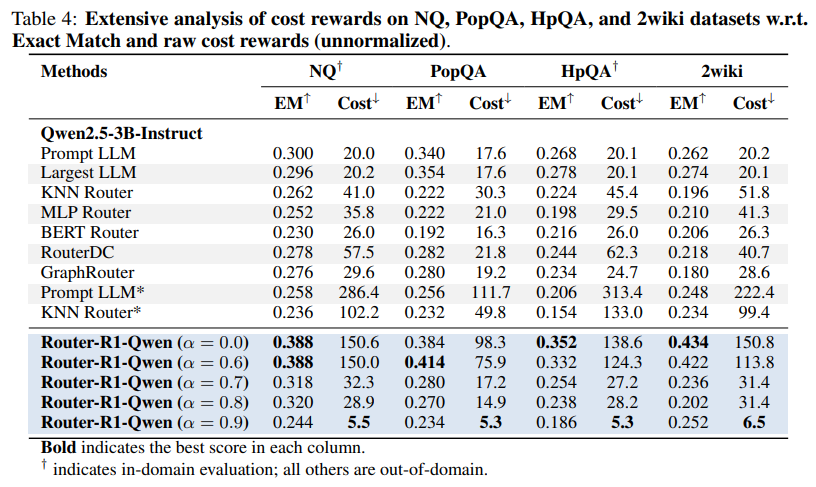
Cost-Aware Routing: The analysis of the cost reward reveals an emergent, intelligent routing strategy. When faced with a task, Router-R1 learns to first query smaller, more cost-effective models. It only escalates to larger, more expensive models if the initial attempts fail to yield a satisfactory answer (Figure 3, Table 4). This dynamic balancing act makes the system highly practical for real-world deployments where budget constraints are a major concern.
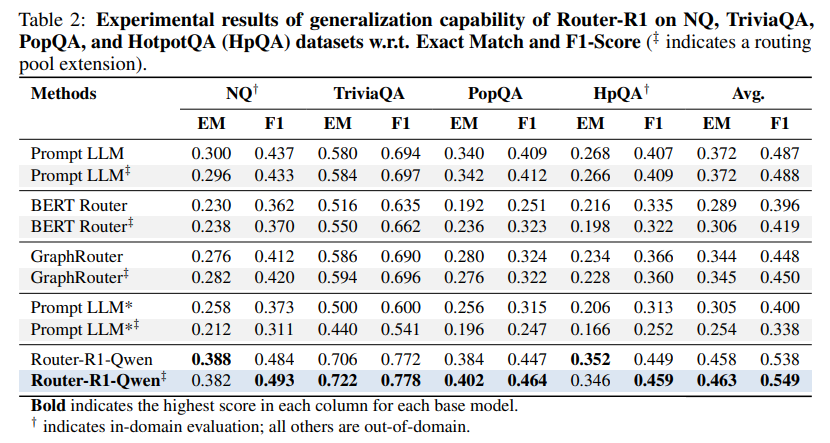
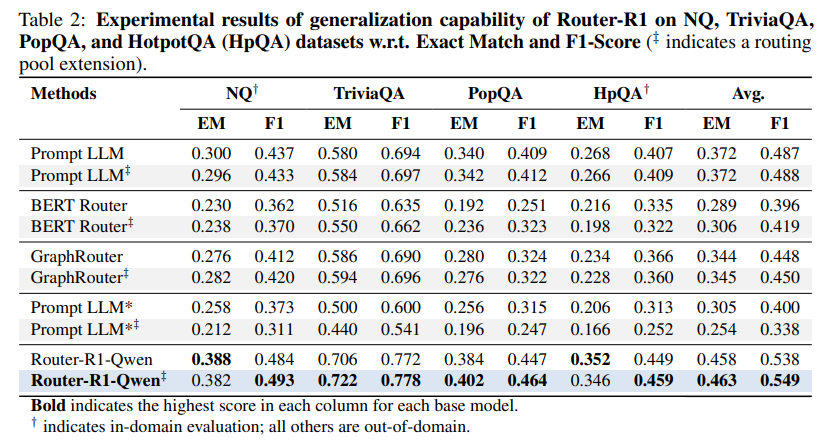
Robust Generalization: One of the most compelling findings is Router-R1's ability to generalize. When new, unseen LLMs were added to the routing pool at inference time, Router-R1 was able to effectively leverage their capabilities, maintaining and in some cases even improving its performance without any additional training (Table 2). This highlights the framework's robustness and future-readiness in a rapidly evolving model landscape.
Limitations and Future Impact
The authors acknowledge several limitations, including a primary evaluation focus on QA tasks, the simplicity of the current rule-based reward function, and potential inference latency. While the multi-round process introduces latency, this may be a necessary price for a new class of capabilities. For complex problems that are simply intractable for any single model, the 'cost' of latency is easily outweighed by the 'benefit' of arriving at a correct—or any—solution at all. The framework's true value may lie not in speeding up existing tasks, but in unlocking entirely new ones.
The potential impact of this work is substantial. Router-R1 represents a significant step towards more sophisticated, collaborative, and resource-aware AI systems. It provides a principled framework for building LLM agents that can intelligently orchestrate a team of specialized models, paving the way for AI that can tackle more complex, multi-faceted problems than ever before. This work moves the field closer to a future of composable AI, where systems are built from modular, reusable components that work together in a dynamic and intelligent symphony.
Conclusion
"Router-R1: Teaching LLMs Multi-Round Routing and Aggregation via Reinforcement Learning" offers a valuable and timely contribution to the field. By recasting LLM routing as a sequential decision problem and positioning an LLM as the orchestrator, the paper presents a novel and powerful approach to multi-model coordination. The strong empirical results, combined with a pragmatic focus on cost-efficiency and generalization, make this a compelling framework for building the next generation of intelligent and adaptive LLM applications. This paper is a clear demonstration of how we can teach LLMs not just to answer, but to strategize.