
Self-Adapting Language Models
When LLMs Generate Their Own Learning Process
Self-Adapting Language Models
Authors: Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, and Pulkit Agrawal
Paper: https://arxiv.org/abs/2506.10943
Code: https://jyopari.github.io/posts/seal
TL;DR
WHAT was done? The paper introduces Self-Adapting Language Models (SEAL), a framework enabling LLMs to self-adapt by generating their own finetuning data and update directives, termed "self-edits." This process is governed by a nested loop system: an inner loop updates the model's weights via supervised finetuning (SFT) based on a generated self-edit, while an outer reinforcement learning (RL) loop optimizes the model's ability to generate effective self-edits. The reward signal for the RL loop is the downstream performance of the model after the weight update, directly training the LLM to learn how to learn more efficiently.
WHY it matters? SEAL marks a conceptual shift from static, data-consuming LLMs to dynamic, self-improving agents. This approach offers a compelling path to address the "data wall"—the looming scarcity of human-generated training data—by enabling models to create their own high-utility training signals. The framework demonstrates that a model can learn to configure its own adaptation pipeline for new tasks and, crucially, can generate synthetic data for knowledge incorporation that is more effective than data produced by a much larger model (GPT-4.1). This moves the field closer to truly autonomous systems capable of continual, structured self-modification.

Details
The Challenge of Static Intelligence
Large Language Models (LLMs) have demonstrated remarkable capabilities, yet they largely operate as static entities. The authors frame the problem with a relatable analogy: a student preparing for an exam. Simply re-reading the textbook (the "raw data") is often less effective than actively processing it—rewriting notes, creating summaries, or drawing diagrams. This act of restructuring information makes it easier to understand and recall. Current LLMs are like the student who only re-reads; they consume data "as-is." This paper confronts this fundamental limitation by asking: can we teach an LLM to be the diligent student who actively rewrites its own "notes" to learn more effectively?
The authors introduce Self-Adapting Language Models (SEAL), a novel framework that reframes LLM adaptation from a passive process of data consumption to an active one of self-directed learning. The core narrative is a move towards greater autonomy, where models transition from being mere tools to becoming agents of their own improvement.
Methodology: Learning How to Learn
The SEAL framework is elegantly designed around a nested-loop architecture that facilitates self-modification (Figure 1).

The Inner Loop: Weight Adaptation: Given a new context—such as a passage of text to learn or a few-shot task to master—the LLM generates a "self-edit." This is a natural language directive that specifies how the model should adapt. For knowledge incorporation, the self-edit might be a set of synthesized "implications" derived from the passage (Figure 2).

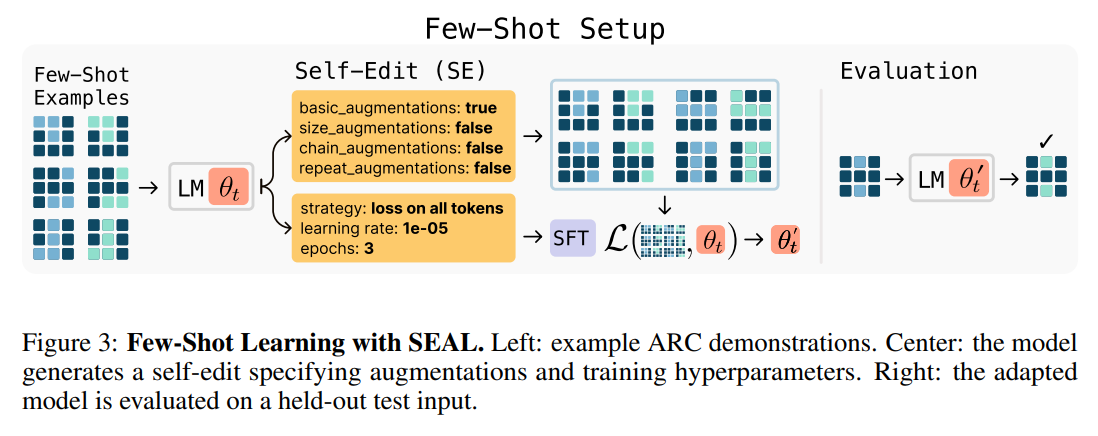
For few-shot learning, it could be a configuration specifying data augmentations and optimization hyperparameters like learning rate and training epochs (Figure 3).
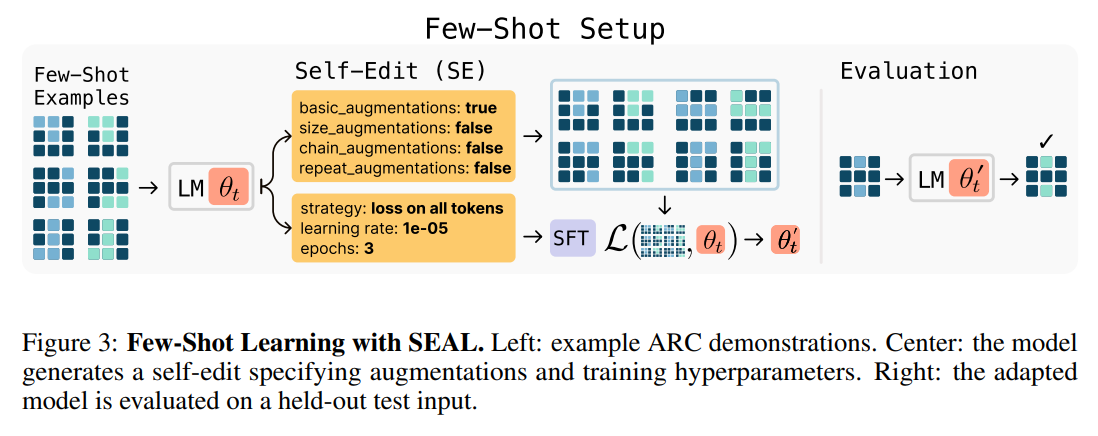
This self-edit is then used to update the model's weights through an efficient supervised finetuning (SFT) step, often using Low-Rank Adaptation (LoRA) for parameter efficiency..
The Outer Loop: Optimizing the Adaptation Policy: The key innovation lies in the outer reinforcement learning (RL) loop. After the inner loop updates the model, the new model's performance on a relevant downstream task is evaluated. This performance delta serves as a reward signal to train the self-edit generation policy. For this RL step, the authors prudently chose ReSTEM, a stable rejection-sampling-based method. Rather than using complex and sometimes unstable policy gradient algorithms, ReSTEM operates on a simple principle: the model generates several candidate self-edits, the system evaluates which ones lead to a performance boost, and then it reinforces the generation policy by finetuning only on these "winning" attempts.


Crucially, SEAL's approach to self-improvement differs from other paradigms like RLAIF. Those methods rely on the model's own judgment to create a reward signal, which can be limited by the model's existing knowledge and biases. In contrast, SEAL's reward is grounded in external reality—its actual performance on a downstream task. As the paper argues, this makes the improvement process more robust and scalable, as it's not trapped in a self-consistency loop.
This design directly leverages the model's own generative capabilities to control its learning process, embodying a powerful form of meta-learning where the outer loop learns an optimal adaptation strategy for the inner loop. The model isn't just learning facts; it's learning the optimal way to internalize those facts.
Experimental Validation: From Theory to Tangible Gains
The authors validate SEAL across two challenging domains: few-shot abstract reasoning and knowledge incorporation, with compelling results.
In a few-shot learning setup using a Llama-3.2-1B-Instruct model on a subset of the ARC-AGI benchmark, SEAL dramatically improved the adaptation success rate. While standard in-context learning (ICL) failed completely (0% success) and a non-optimized self-editing baseline achieved 20%, SEAL reached a 72.5% success rate (Table 1). This demonstrates that the model can learn to effectively configure its own learning pipeline for novel, complex tasks.

The knowledge incorporation experiments delivered perhaps the most striking finding. Using a 7B-parameter Qwen2.5 model, SEAL was tasked with integrating information from SQuAD passages. The model trained on its own self-generated "implications" achieved 47.0% accuracy on subsequent no-context questions. This not only surpassed baselines that finetuned on the raw passage (33.5%) but also exceeded the performance of a model finetuned on synthetic data generated by the much larger and more capable GPT-4.1 (46.3%) (Table 2).
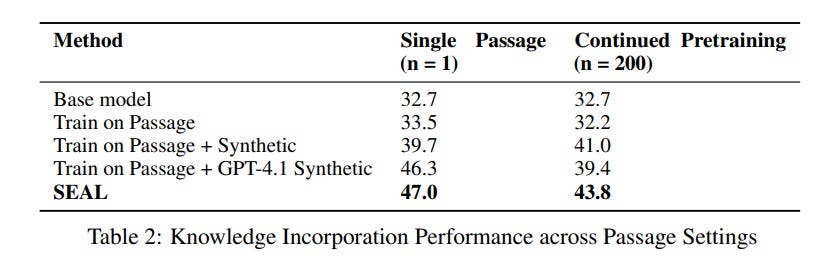
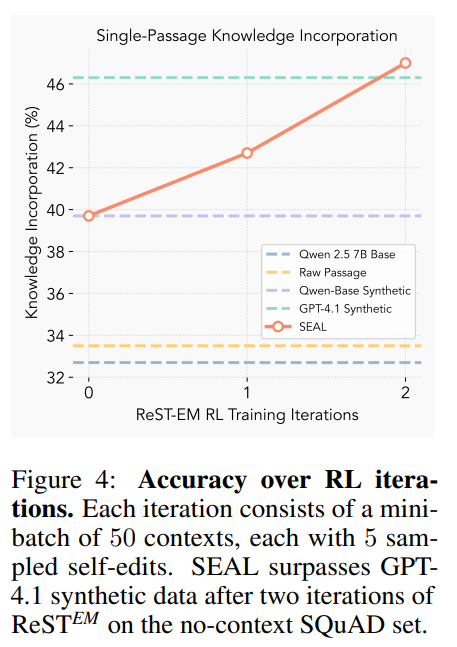
This result is significant. It suggests that the quality of synthetic data is not just about the power of the generator model, but about how well that data is tailored to the specific learning needs of the target model. A qualitative analysis (Figure 5) reveals how the RL process guides the model to refine its self-edits from simple paraphrases into more detailed, "learnable atomic facts," leading to better downstream performance.

Impact and Future Directions: Towards Self-Sufficient AI
The implications of this work are far-reaching. By showing that an LLM can generate its own high-utility training data, SEAL presents a credible strategy for overcoming the "data wall" and enabling models to continue scaling in a data-constrained world.
The framework lays the groundwork for more sophisticated agentic systems. One can envision an agent that, after interacting with its environment, generates self-edits to internalize new knowledge, leading to structured and persistent self-improvement. The authors also propose intriguing future work, including integrating SEAL with chain-of-thought reasoning, where a model might perform weight updates mid-inference or distill insights into its parameters after completing a reasoning task. The framework also opens the door to a "teacher-student" setup, where a separate, dedicated "teacher" model could be trained via RL to generate optimal edits for a "student" model, further decoupling the adaptation and generation processes.
Limitations and Open Questions
The authors are transparent about the framework's current limitations. The primary challenge is catastrophic forgetting; as the model sequentially integrates new edits, its performance on earlier tasks degrades (Figure 6). While SEAL can perform multiple updates without a complete collapse, robustly preserving knowledge remains an open problem for this line of research.
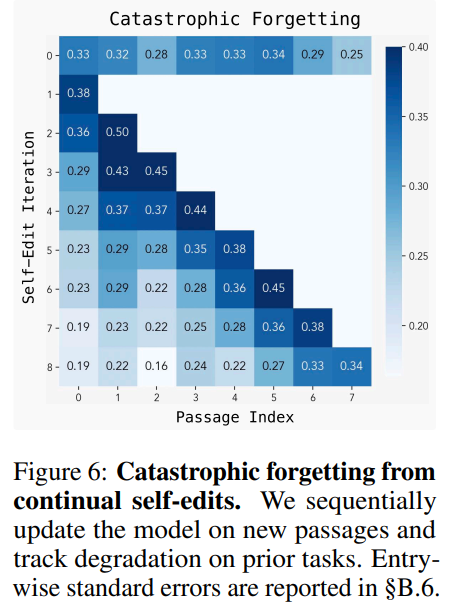
Furthermore, the RL training loop is computationally expensive, as it requires a full finetuning and evaluation cycle for each candidate self-edit. The current evaluation paradigm also relies on explicit downstream tasks to generate a reward signal, which limits its application to unlabeled corpora. The authors suggest a potential solution where the model learns to generate its own evaluation questions, an interesting direction for future exploration.
Conclusion
"Self-Adapting Language Models" presents a significant conceptual advance in our quest for more dynamic and autonomous AI. By demonstrating that a model can effectively direct its own learning process, the authors have opened a new and exciting research frontier. The SEAL framework is not just another finetuning technique; it is a paradigm shift that recasts LLMs as active participants in their own evolution. While challenges like catastrophic forgetting and computational cost remain, this paper offers a valuable and compelling vision for the future of continually learning systems. It is a foundational piece of work that will likely inspire a great deal of follow-up research.