
Self-Improving Pretraining: using post-trained models to pretrain better models
Authors: Ellen Xiaoqing Tan, Shehzaad Dhuliawala, Jing Xu, Ping Yu, Sainbayar Sukhbaatar, Jason Weston, Olga Golovneva
Paper: https://arxiv.org/abs/2601.21343
Code: N/A
Model: N/A
Affiliation: FAIR at Meta
TL;DR
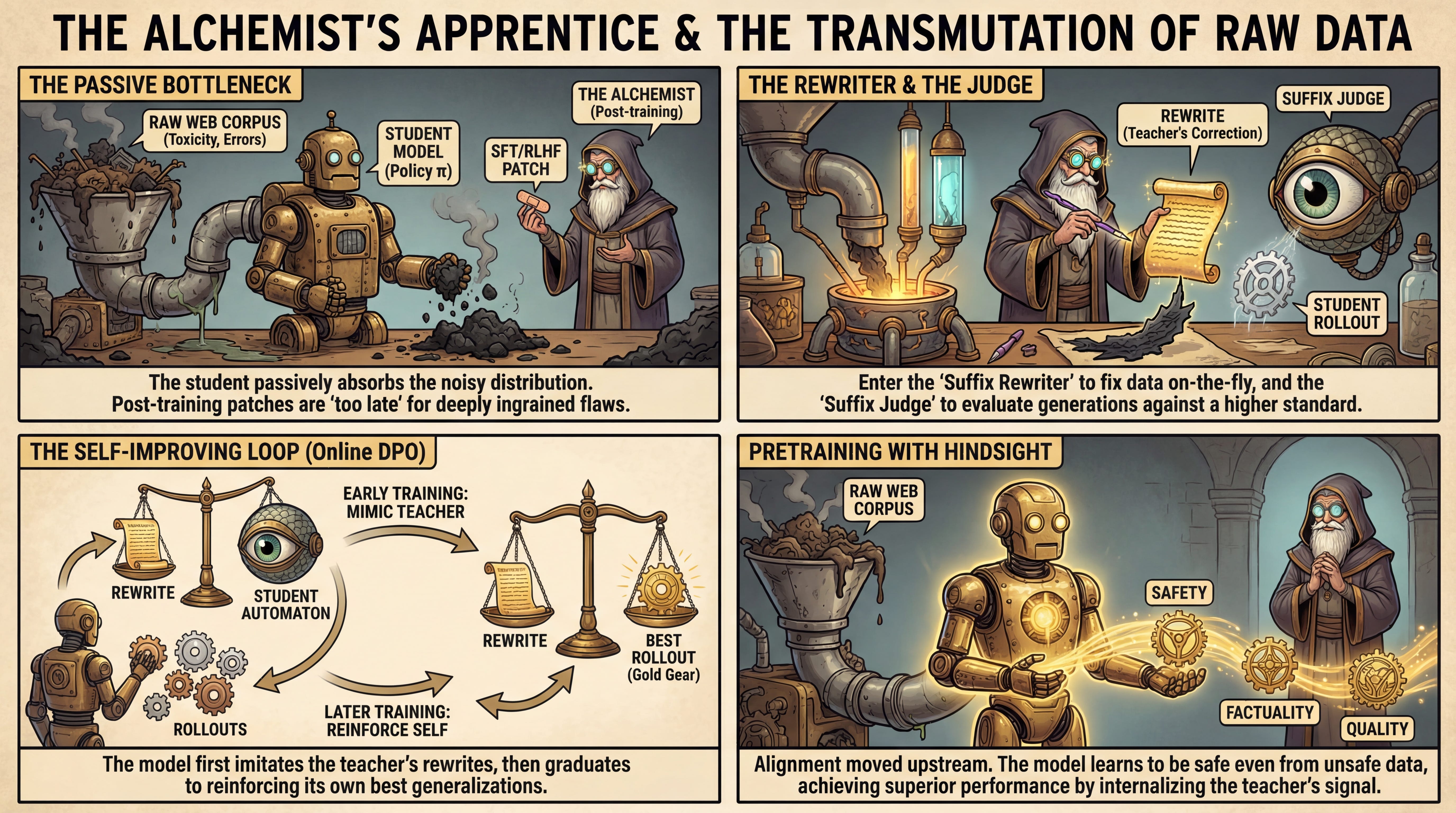
WHAT was done? The authors introduce “Self-Improving Pretraining,” a method that replaces standard next-token prediction with an online reinforcement learning loop during the pretraining phase. Instead of passively learning from raw corpora, the model uses a strong post-trained “teacher” model to rewrite low-quality data on the fly and judge the student model’s own generations. This allows the model to learn from a curated, high-quality signal—composed of rewrites and its own best rollouts—rather than raw web text.
WHY it matters? This approach challenges the prevailing dogma that alignment (safety, factuality) is solely a post-training concern (SFT/RLHF). By integrating preference learning into the pretraining substrate, the method prevents the model from baking in toxicity or hallucinations found in raw data. It demonstrates that models can learn to be safe even when trained on unsafe data, provided the training objective actively steers them away from it, yielding up to 86.3% win rate improvements over standard baselines.
Details
The Passive Learning Bottleneck
The current paradigm of Large Language Model (LLM) training relies heavily on a two-stage process: massive self-supervised pretraining on raw web data followed by fine-tuning (SFT and RLHF) for alignment. The fundamental bottleneck here is that pretraining is passive; the model indiscriminately absorbs the distribution of the internet, including toxicity, bias, and factual errors. While post-training attempts to suppress these behaviors, it often acts as a superficial patch over deeply ingrained patterns. The authors of this paper argue that addressing these issues during post-training is “too late.” If a model learns that “The Earth is flat” is a plausible continuation of a specific context during pretraining, unlearning that association requires fighting the model’s core weights. This paper proposes moving the alignment signal upstream, effectively cleaning the data and the model’s behavior simultaneously during the compute-heavy pretraining phase.
