
Shaping capabilities with token-level data filtering
Authors: Neil Rathi, Alec Radford
Paper: https://arxiv.org/abs/2601.21571
Code: https://github.com/neilrathi/token-filtering
Model: Custom Transformers (up to 1.8B)
TL;DR
WHAT was done? The authors propose token-level data filtering as a mechanism to surgically remove specific capabilities (using medical knowledge as a proxy) during the pretraining phase. By training lightweight classifiers to identify and mask specific tokens associated with a target domain, they prevent the model from learning those concepts while preserving adjacent knowledge (e.g., general biology).
WHY it matters? This represents a shift from “post-hoc” safety (RLHF/Unlearning) to “ab initio” safety. The results are striking: token filtering scales significantly better than document-level filtering, creating a 7000× compute slowdown for the model to re-acquire the forgotten knowledge at the 1.8B parameter scale. Furthermore, the paper features Alec Radford (lead author of GPT-2 and GPT-3) as an independent author alongside Anthropic researchers, signaling a high-profile convergence on data curation as a primary safety lever.

Details
The Pretraining “Hammer” vs. The Safety “Scalpel”
The prevailing paradigm in AI safety has largely relied on post-training interventions—Reinforcement Learning from Human Feedback (RLHF) or various “unlearning” techniques—to suppress dangerous capabilities like biological weapon synthesis. However, these methods effectively fight against the model’s own weights; the knowledge exists in the substrate, and adversarial attacks (jailbreaks) often succeed by eliciting it. A more robust alternative is data filtering: simply not showing the model the dangerous data in the first place.
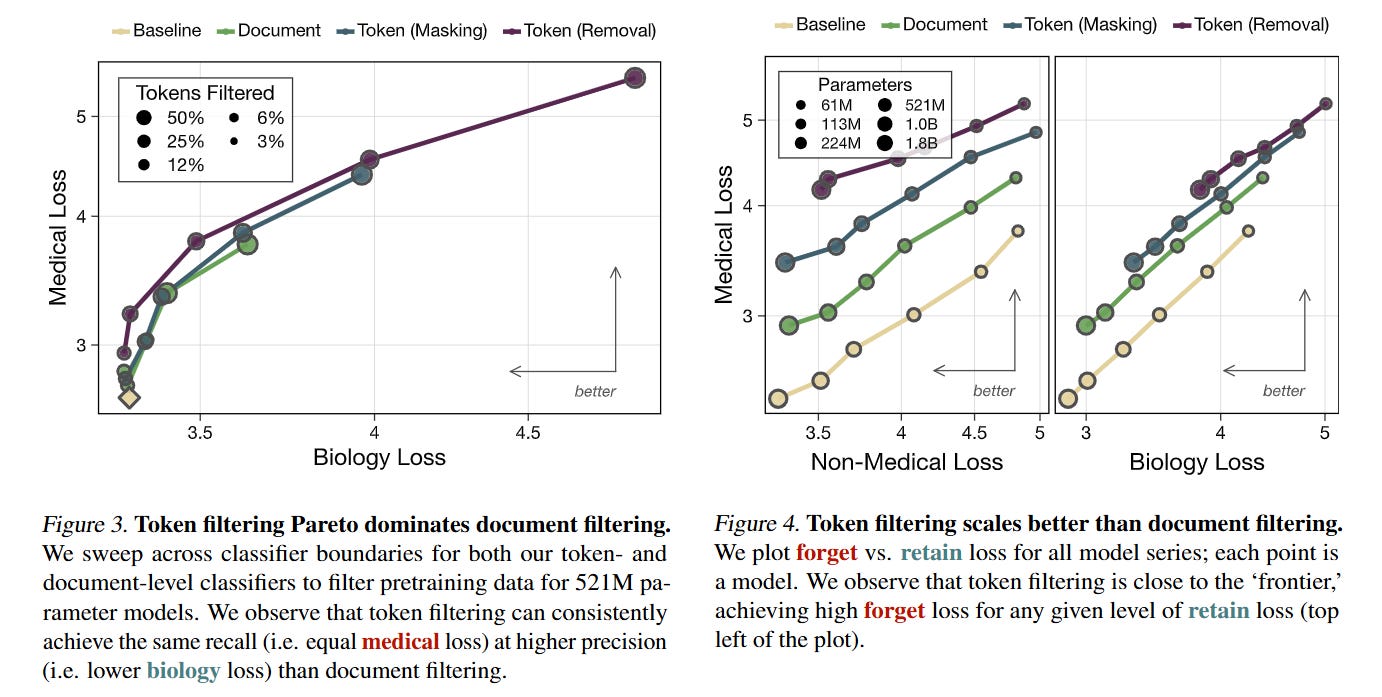
Prior work, such as O’Brien et al. (2025), demonstrated that removing entire documents containing dangerous information is effective. However, document filtering is a blunt instrument. A document containing a recipe for a pathogen might also contain high-quality prose or general reasoning structures that we want the model to learn. Removing the whole document degrades general performance. Rathi and Radford propose a scalpel: Token-Level Filtering. Instead of discarding the haystack, they identify and mask only the needles—specific tokens relevant to the “forget” domain—allowing the model to train on the surrounding benign context.
The Mechanism: From Sparse Autoencoders to Loss Masking
The core technical challenge is labeling. We cannot manually annotate billions of tokens as “medical” or “non-medical.” To solve this, the authors deploy a clever weak-to-strong pipeline that utilizes Sparse Autoencoders (SAEs). They first run a pretrained SAE on a small model (Gemma 2 9B) to identify latent features that activate on medical concepts. These features serve as the “ground truth” to label a dataset, which is then used to train a specialized, lightweight classifier.
This classifier is not a standard causal transformer. The authors correctly identify that predicting whether a current token is “medical” requires future context (e.g., the word “virus” means something different in “computer virus” vs. “influenza virus”). Consequently, they train a bidirectional language model (biLM)—specifically a 224M parameter BERT-style probe—to classify tokens. During the pretraining of the main model, this classifier runs over the corpus.
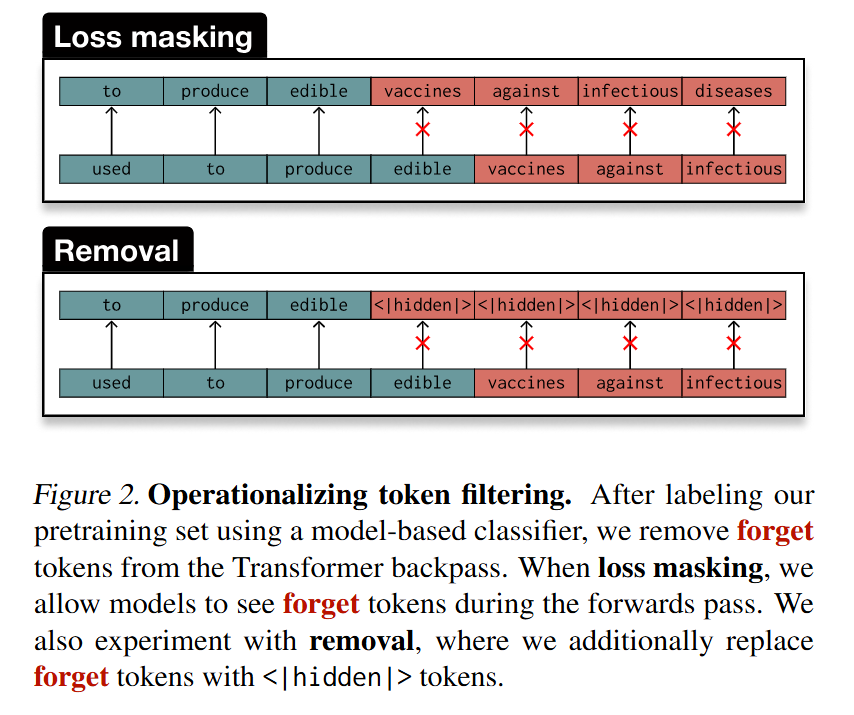
The actual intervention is performed via Loss Masking. For a sequence of tokens x=[x1,…,xT], standard autoregressive training minimizes the negative log-likelihood. The authors introduce a binary mask mt∈{0,1}, where mt=0 if the token xt is classified as belonging to the “forget” domain. The modified update rule becomes
L=−∑t=1TmtlogP(xt∣x<t). This effectively zeroes out the gradient for dangerous tokens, preventing the model from updating its weights based on that specific information, while still allowing it to see the token in the context window (in the Masking variant) or replacing it with a <|hidden|> token (in the Removal variant).
Analysis: The 7000x Compute Barrier
The most significant contribution of this paper is the quantification of how well this method scales. The authors introduce a metric called relative scaling laws, which measures the effective compute slowdown on the forget domain. Essentially, they ask: “How much compute would a baseline model need to achieve the same (poor) performance on medical tasks as our filtered model?”
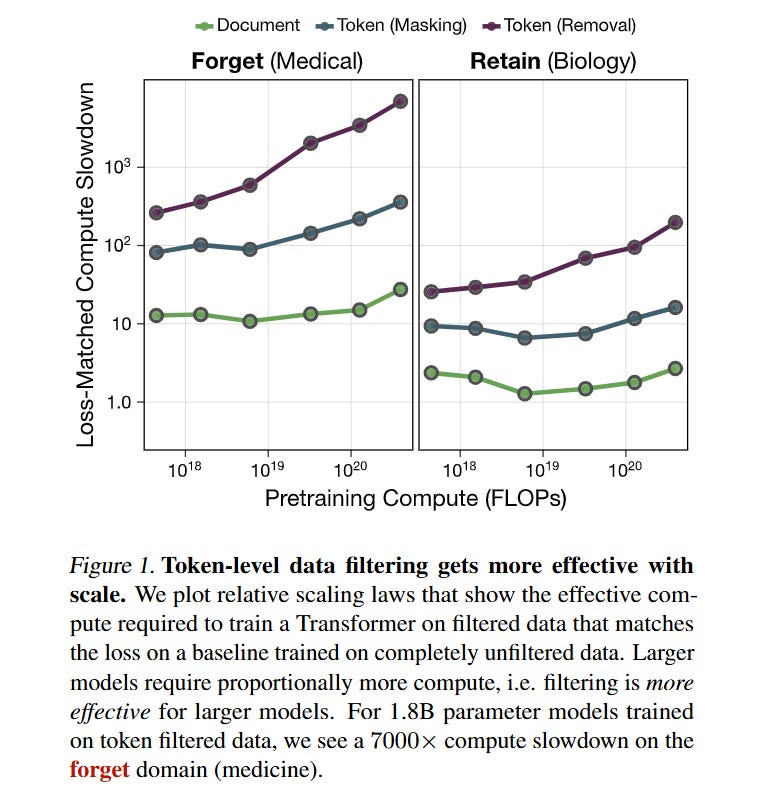
As shown in Figure 1, token filtering does not just beat document filtering; it creates a gap that widens with model size. For their largest model (1.8B parameters), token removal resulted in a 7000× compute slowdown regarding the acquisition of medical knowledge. In contrast, document filtering only achieved a ~30× slowdown. This suggests that as models get larger, the surgical removal of tokens becomes exponentially more effective at suppressing specific capabilities compared to the crude removal of documents.
Robustness and The Alignment Paradox
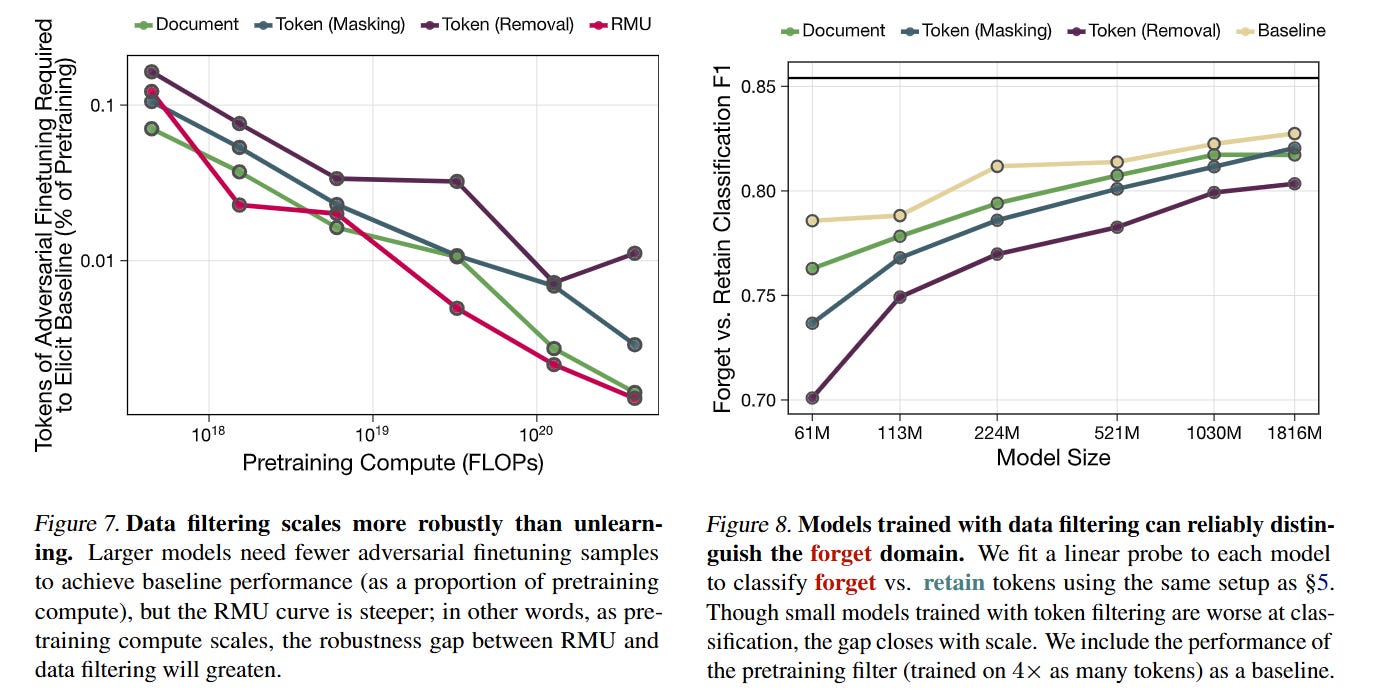
A critical vulnerability of “unlearning” methods (like RMU) is that the model can relearn the suppressed information with very little fine-tuning data. The authors subjected their token-filtered models to adversarial finetuning and found them to be substantially more robust. While state-of-the-art unlearning methods collapsed quickly, models trained with token filtering maintained their ignorance much longer, requiring orders of magnitude more data to recover the capabilities.
Perhaps the most counter-intuitive result involves alignment. One might assume that if a model has never seen medical text, it would be unable to recognize a medical query to refuse it. However, the authors found the opposite. Models trained with token filtering generalized better to refusal training than models trained with document filtering. The hypothesis is that by seeing the context around the masked tokens, the model learns to identify the “shape” of the medical domain without learning the facts within it. It learns that “this is the kind of question I cannot answer,” whereas a document-filtered model is simply out-of-distribution and confused.
Engineering the Classifier
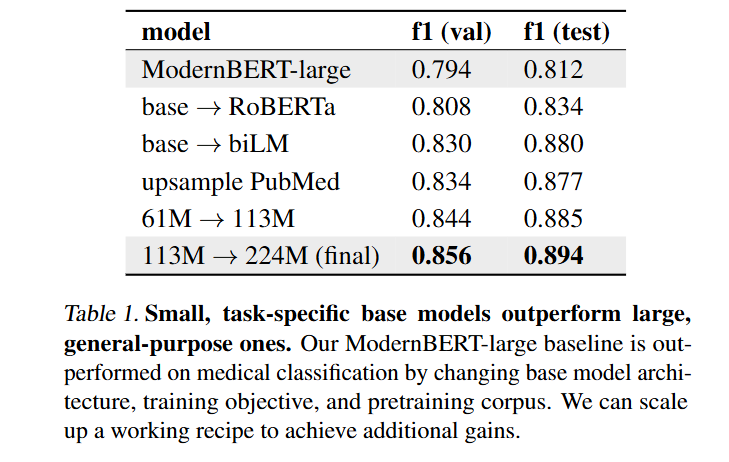
The engineering choices behind the classifier deserve attention for practitioners. The authors found that small, task-specific bidirectional models significantly outperform larger, general-purpose causal models for this tagging task. A 224M parameter biLM achieved an F1 score of 0.894 on token classification, beating a ModernBERT-large baseline.
They also tackle the “noisy label” problem. Even with SAE-generated labels, the ground truth is imperfect. They demonstrate that filtering is highly sensitive to precision and recall trade-offs. An aggressive filter (high recall, low precision) is necessary to scrub the capability. This aligns with the “knowledge vs. capability” distinction: you must remove enough granular information (atomic facts) to collapse the higher-level capability.
Related Works
This work situates itself at the intersection of Data Attribution and Machine Unlearning. It directly builds upon the document-filtering findings of O’Brien et al. (2025) and Chen et al. (2025). It contrasts sharply with post-hoc representation engineering methods like RMU (Li et al., 2024), showing that pre-computation intervention is far more stable. The use of SAEs for dataset labeling leverages recent interpretability advances from Lieberum et al. (2024), essentially using interpretability tools to bootstrap safety filters.
Limitations
The primary limitation lies in the definition of the “forget” set. The authors used medical data as a proxy for dangerous capabilities (like CBRN). Medical data is distinct and vocabulary-rich. It remains to be seen if this method works as effectively for domains that are more entangled with general reasoning, such as “cybersecurity exploits” or “social manipulation,” where the vocabulary overlaps significantly with benign computer science or creative writing. Additionally, before specific refusal training is applied, models trained with token filtering can exhibit “confident hallucinations,” generating coherent but factually incorrect nonsense in the forget domain (e.g., claiming dry lips are a symptom of heart disease), which presents a unique safety nuance compared to simple silence.

Impact & Conclusion
The collaboration between Anthropic and Alec Radford is a strong signal that the industry is moving toward curated pretraining as a primary safety layer. “Shaping capabilities with token-level data filtering” provides a rigorous empirical foundation for this shift. It suggests that we can decouple general reasoning from hazardous knowledge by operating at the token level. If the scaling laws hold, this “scalpel” approach could allow open-weights release of powerful models that are structurally incapable of specific dangerous tasks, simply because the atomic units of that knowledge were never computed in the backward pass.