
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Authors: Robert Tjarko Lange, Yuki Imajuku and Edoardo Cetin
Paper: https://arxiv.org/abs/2509.19349
Code: https://github.com/SakanaAI/ShinkaEvolve
Blog: https://sakana.ai/shinka-evolve/
TL;DR
WHAT was done? The paper introduces ShinkaEvolve, a new open-source framework that uses large language models (LLMs) for evolutionary program synthesis and scientific discovery. It addresses the critical issue of sample inefficiency in existing methods by incorporating three key algorithmic innovations: 1) an adaptive parent sampling strategy that intelligently balances exploration and exploitation; 2) a code novelty rejection-sampling mechanism using embeddings and an LLM-as-judge to prune redundant program variants; and 3) a bandit-based LLM ensemble selector that dynamically prioritizes models based on their historical performance.
WHY it matters? ShinkaEvolve marks a significant step towards making AI-driven algorithmic discovery practical and accessible. By achieving state-of-the-art results with orders of magnitude fewer evaluations than previous methods, it dramatically lowers the computational and economic barriers to entry. This efficiency is demonstrated across diverse and challenging domains, including discovering a new state-of-the-art algorithm for circle packing with only 150 samples, designing high-performing agent scaffolds for mathematical reasoning, improving competitive programming solutions, and even discovering a novel load balancing loss function for Mixture-of-Experts (MoE) models. Its open-source release further democratizes these powerful tools, enabling broader community engagement in automated scientific discovery.

Details
The Dawn of Efficient Algorithmic Discovery
Recent years have seen an explosion of interest in using Large Language Models (LLMs) as engines for scientific discovery, where they act as sophisticated “mutation operators” in evolutionary systems. These approaches have shown immense promise but have been hampered by a critical bottleneck: profound sample inefficiency. Finding effective solutions often required thousands of costly evaluations, confining this research to well-resourced labs and proprietary systems.
The paper on ShinkaEvolve presents a compelling solution to this challenge, narrating a shift from brute-force exploration to a more intelligent, efficient, and accessible paradigm for AI-driven discovery. The name itself, ‘Shinka’ (進化), is Japanese for ‘evolution’ or ‘innovation,’ reflecting the framework’s core purpose. It introduces a framework that not only achieves state-of-the-art results but does so with unprecedented efficiency, effectively democratizing a powerful research frontier.
Methodology: A Smarter Evolutionary Loop
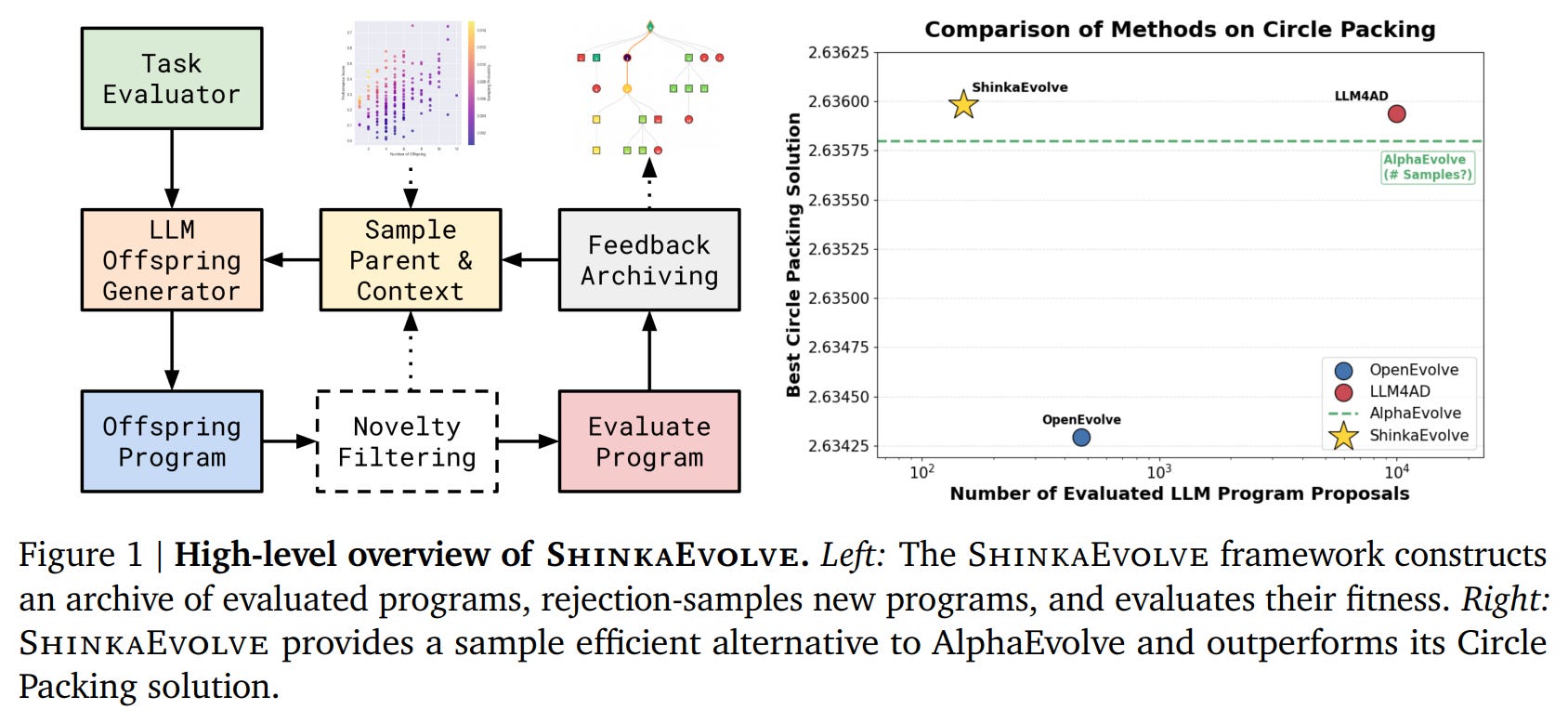
ShinkaEvolve’s core is an evolutionary framework that iteratively refines a population of programs. Its key innovations are woven into a three-phase control flow designed to maximize the value of every sample (Figure 1).
1. Intelligent Parent and Inspiration Sampling
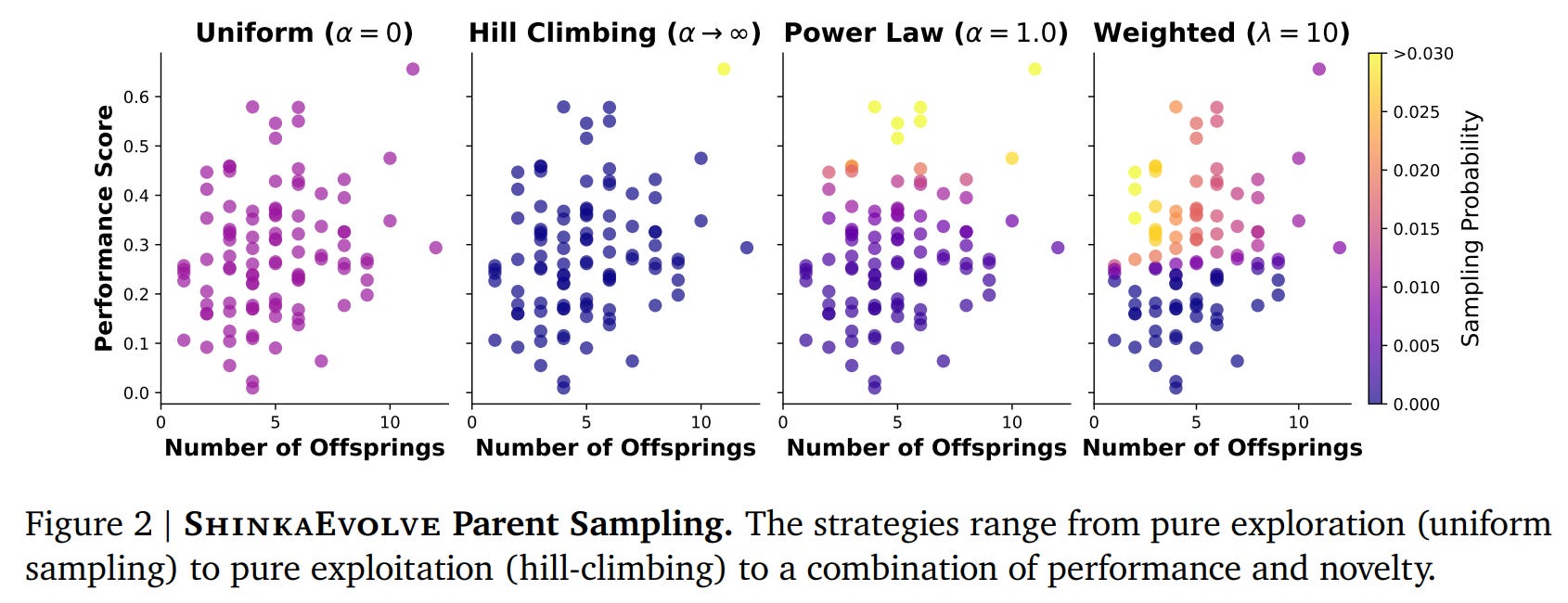
Instead of naive selection, ShinkaEvolve employs sophisticated strategies to choose programs for mutation from its archive. The framework supports multiple approaches, most notably a weighted sampling strategy that balances performance and novelty.
The probability pi of selecting a program Pi is given by:
pi=wi/Σwj, where wi=si⋅hi
Here, the performance component si=σ(λ⋅(F(Pi)–ao)) scales the program’s fitness F(Pi) relative to the population’s median fitness ao. The novelty component hi=1/(1+N(Pi)) favors programs with fewer prior offspring N(Pi), encouraging exploration of less-traveled paths.
2. Program Mutation and Novelty Filtering
LLMs generate new “offspring” programs via three mutation types: diff-based edits, full rewrites, and crossover between two parent programs. To avoid wasting resources on trivial variations, ShinkaEvolve introduces a code novelty rejection-sampling mechanism (Figure 3).
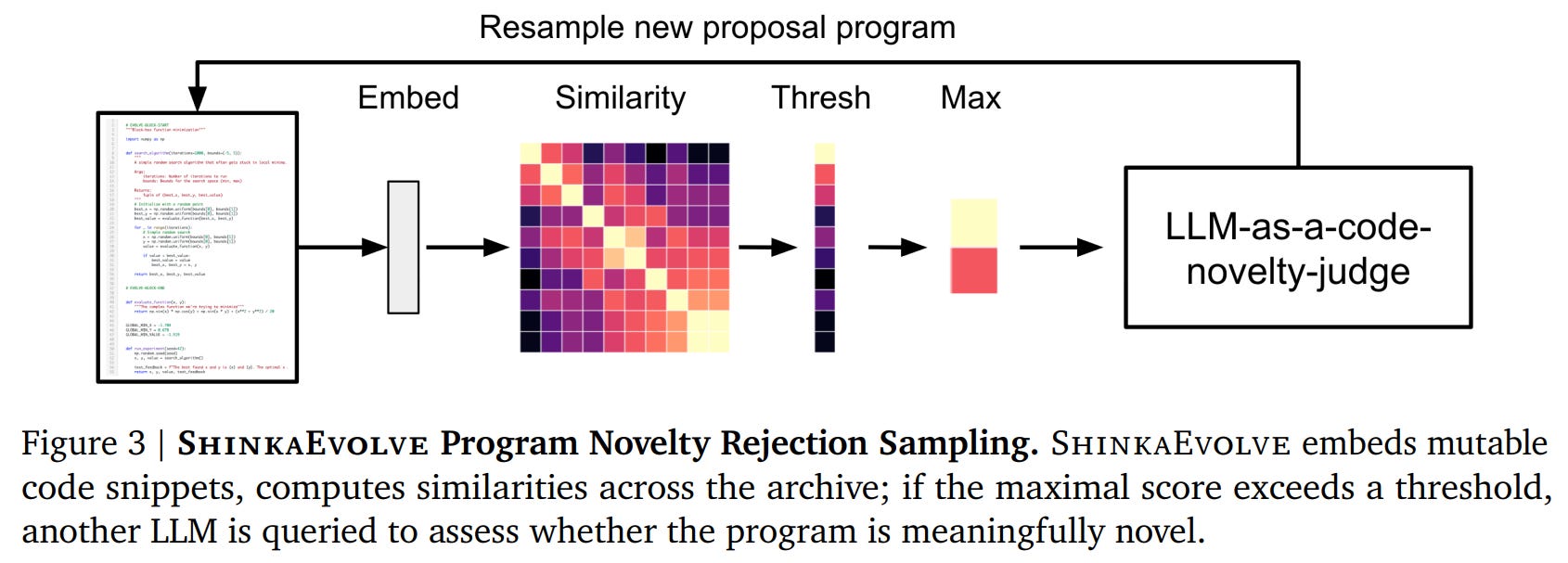
Mutable code snippets of a new proposal are embedded, and their cosine similarity to existing programs is calculated. If the similarity exceeds a threshold (e.g., 0.95), an “LLM-as-a-novelty-judge” is queried to assess if the change is genuinely meaningful before the program is accepted for evaluation.
3. Adaptive Feedback and Meta-Learning
After a new program is evaluated, the resulting fitness score and feedback are used to guide future evolution. ShinkaEvolve introduces two powerful feedback loops:
Bandit-Based LLM Ensemble Selection: The framework uses a multi-armed bandit approach (UCB1) to dynamically adjust the sampling probability of different LLMs in its ensemble. The reward update is based on the relative improvement a model provides, calculated as ri′=exp(max(ri–r0,0))–1, where ri is the new fitness and r0 is the parent’s fitness. This specific formula, using an exponential function, is designed to heavily reward ‘bold’ mutations that yield significant gains over the parent program while giving zero reward to mutations that offer no improvement. This encourages the system to prioritize LLMs capable of breakthrough innovations over those that only make safe, incremental changes.
Meta-Scratchpad: Periodically, a meta-agent analyzes successful programs in the archive, synthesizes common design principles and optimization strategies, and appends these insights as actionable recommendations to the mutation prompt for the LLMs (Figure 4).


This ‘Meta-Scratchpad’ acts like a chief engineer’s logbook for the entire evolutionary process. By having an AI reflect on what has worked, it distills successful strategies into guiding principles, preventing future generations of LLMs from repeating past mistakes and accelerating the path to discovery.

Experimental Validation Across Diverse Domains
The authors demonstrate ShinkaEvolve’s broad applicability and efficiency across four distinct and challenging domains.
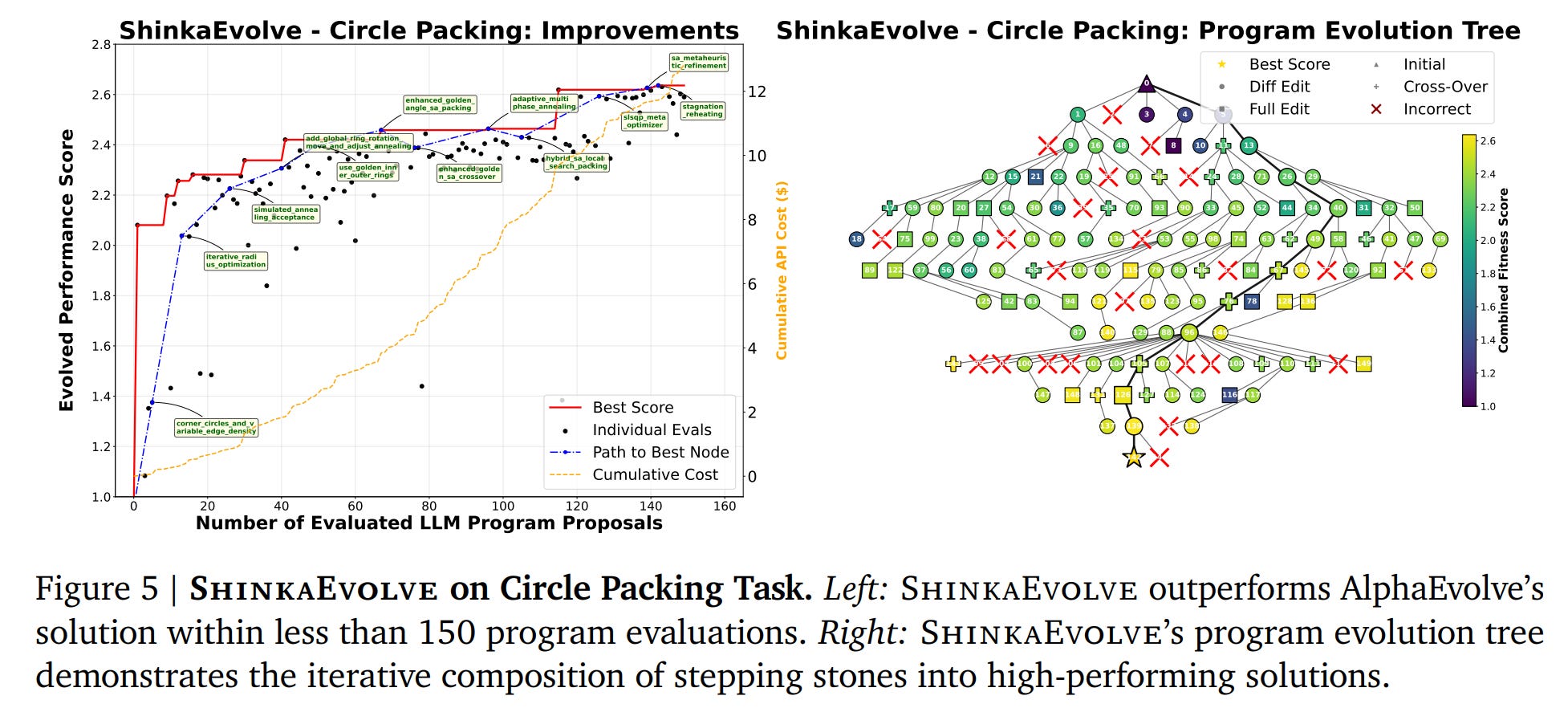
1. Circle Packing: In this classic optimization problem, ShinkaEvolve discovers a new state-of-the-art solution using only 150 evaluations—an orders-of-magnitude improvement in sample efficiency over systems like AlphaEvolve (https://arxiv.org/abs/2506.13131, review is here) (Figure 5). The discovered algorithm is a sophisticated composition of a golden-angle spiral initialization, a hybrid SLSQP/simulated annealing optimizer, and intelligent perturbation mechanisms.
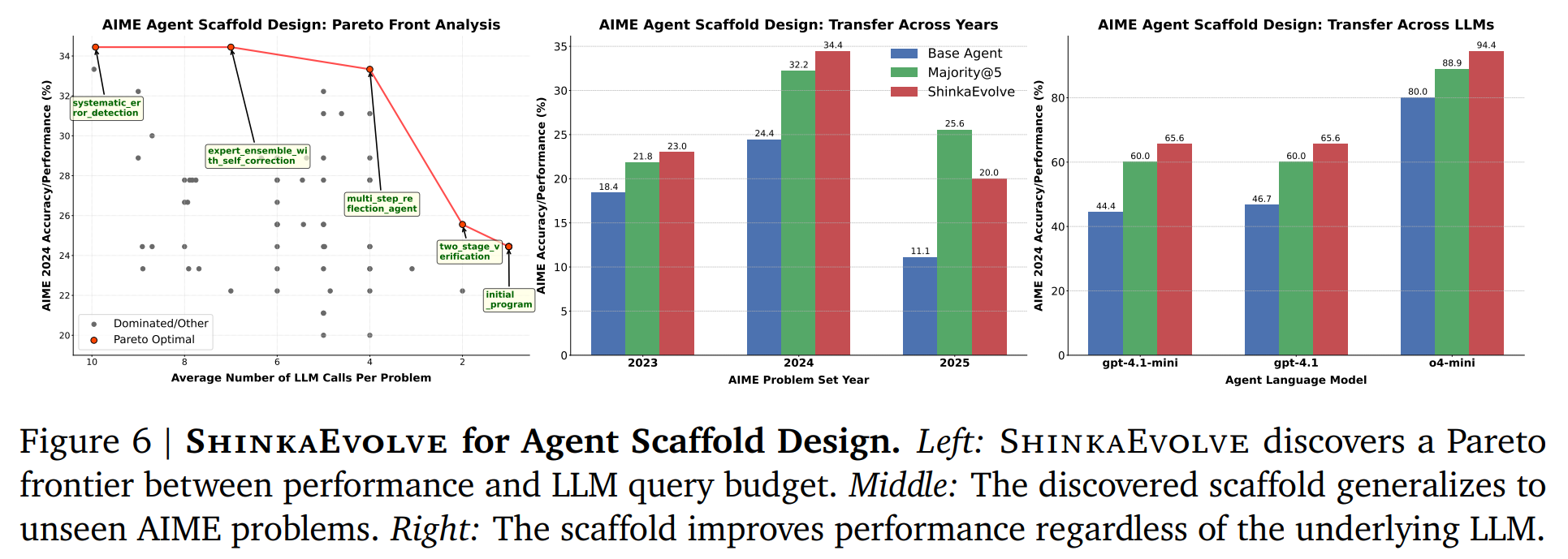
2. AIME Math Reasoning: The framework successfully evolves complex agentic scaffolds for solving competition-level math problems. The discovered three-stage architecture—leveraging expert personas, peer review, and final synthesis—outperforms hand-designed baselines and generalizes robustly to unseen problems from different years and across different base LLMs (Figure 6).
3. ALE-Bench Competitive Programming: ShinkaEvolve demonstrates its ability to improve upon existing high-performing solutions. It refines algorithms from the ALE-Agent (https://arxiv.org/abs/2506.09050), achieving an average improvement of 2.3% across 10 tasks (Figure 7). For one task, it improved a solution from a 5th-place to a hypothetical 2nd-place rank on the public leaderboard by introducing targeted algorithmic changes like a “targeted edge move.”

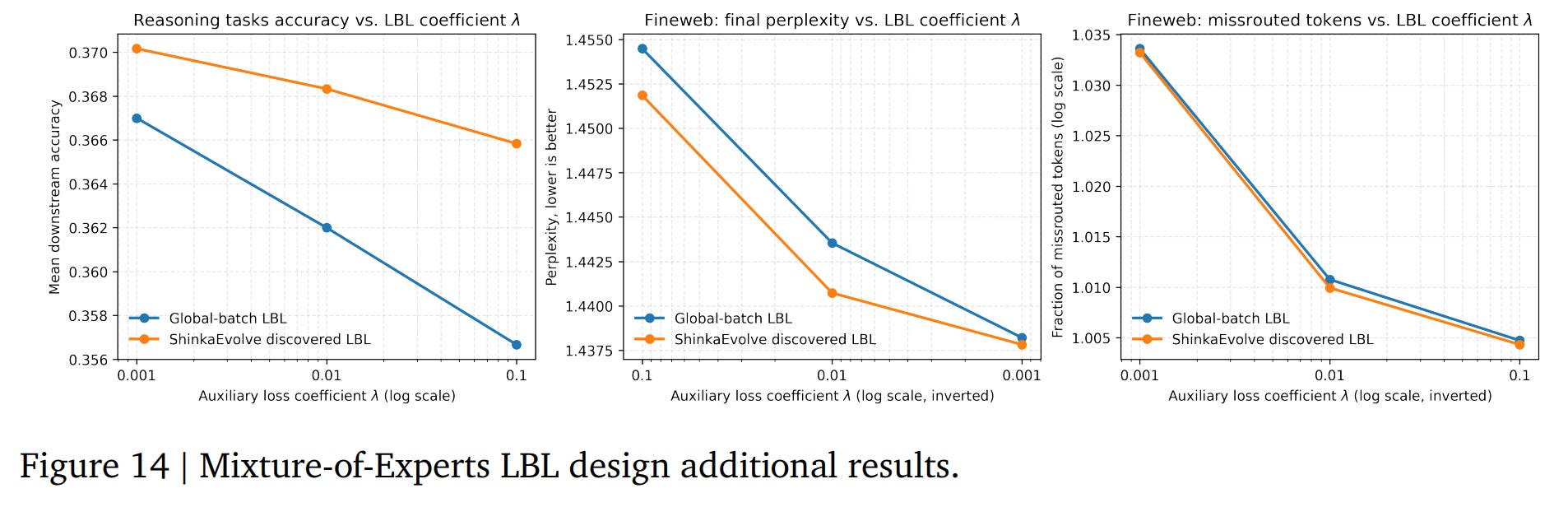
4. Mixture-of-Experts (MoE) Load Balancing: In a compelling demonstration of ‘AI for AI,’ ShinkaEvolve tackles the open architectural challenge of designing an effective load balancing loss (LBL) for MoE models. Starting with the standard global-batch LBL, it discovers a novel regularization term. The new, complete loss function is:
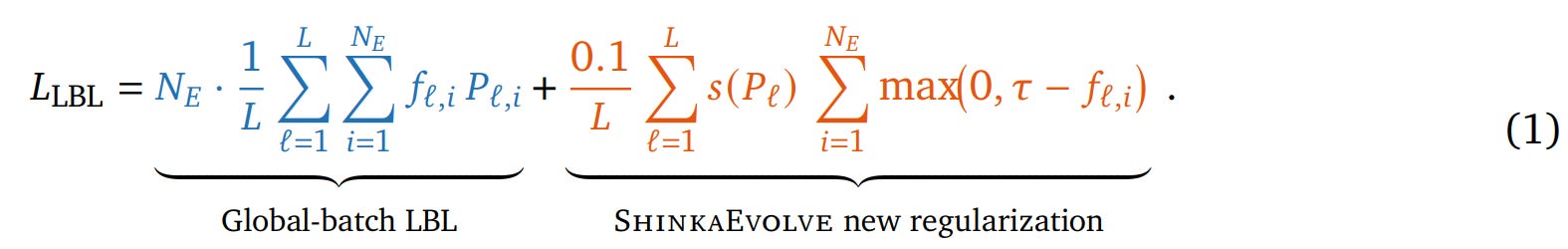
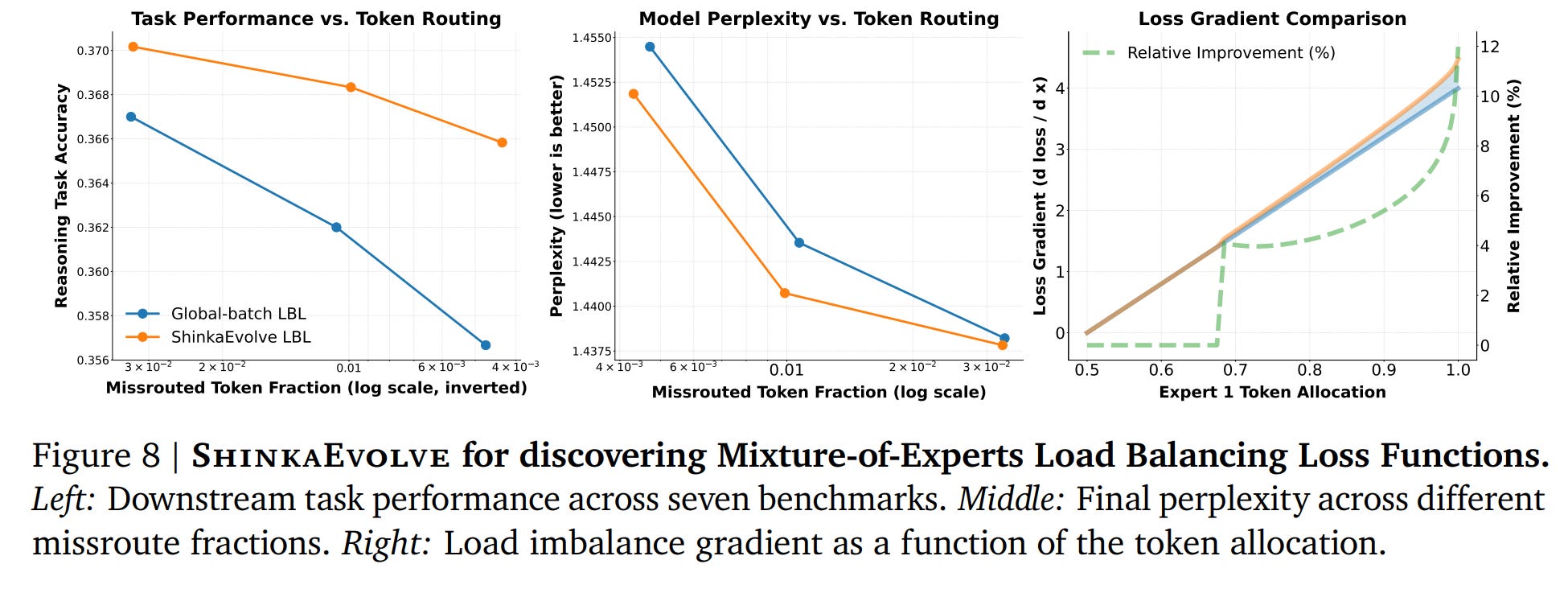
The key innovation is the new term on the right. It acts as a ‘safety net’ where τ is a minimum usage threshold for any expert, and f_{l,i} is its actual usage. The crucial component is s(Pl)=0.5+(1−logNEH(Pl)), an entropy-based scaler. This scaler intelligently applies the penalty more strongly when the routing distribution’s entropy H(Pl) is low (i.e., the model is already over-specializing on a few experts), preventing expert death without over-regularizing well-balanced layers. The discovered loss consistently improves downstream task performance and perplexity over the baseline (Figure 8, Figure 14).
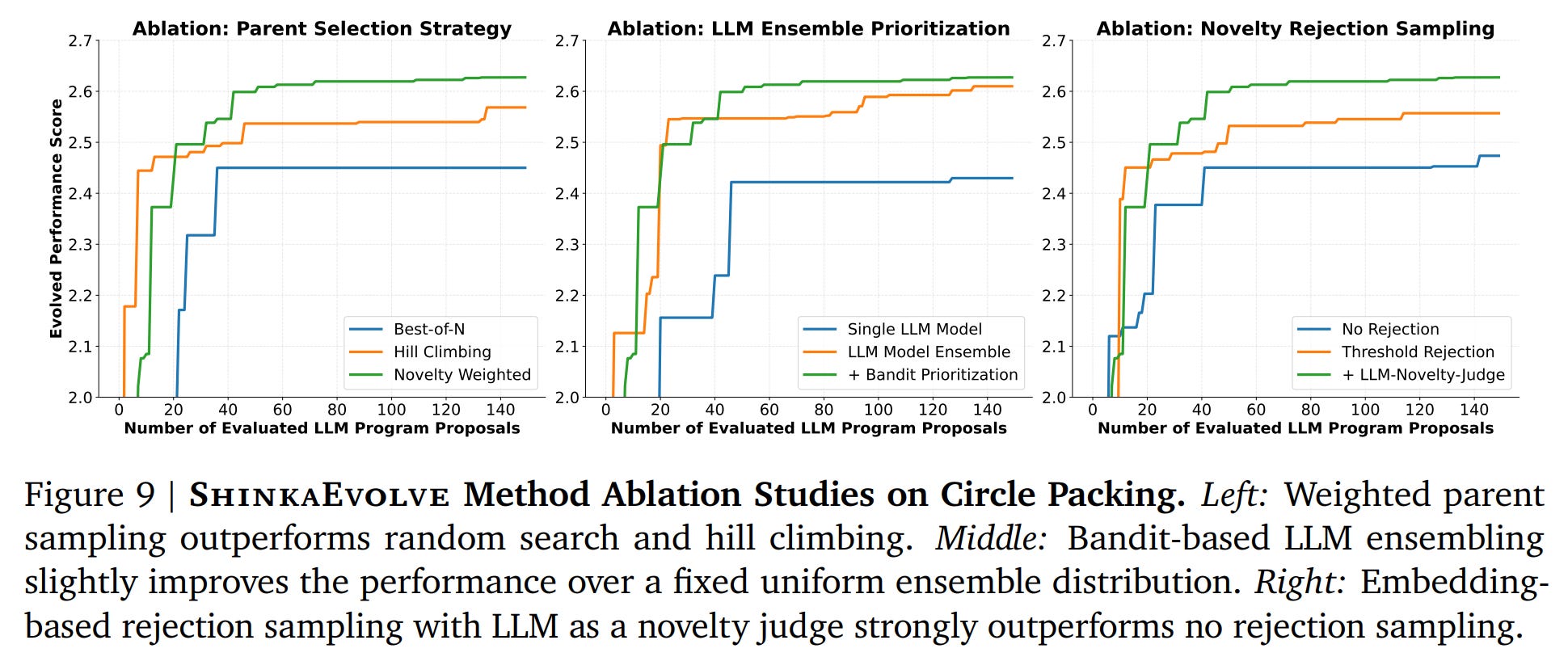
Ablation studies confirm that each of ShinkaEvolve’s core components—weighted parent sampling, bandit-based LLM ensembling, and novelty rejection—contributes significantly to its performance (Figure 9). For those interested in the fine-grained details, the authors provide the complete, evolved Python and C++ code for their discovered solutions in the paper’s appendix, showcasing a high degree of transparency.
Limitations and Future Directions
The authors transparently acknowledge the framework’s current limitations. Task specification still requires human expertise to define objective functions, and its applicability is currently constrained to problems with well-defined numerical objectives. Future work aims to automate task specification via LLM generation and transition towards true open-endedness, where the system can define its own objectives.
Conclusion
ShinkaEvolve is a significant contribution to the field of AI-driven scientific discovery. Its remarkable gains in sample efficiency, combined with a robust and generalizable methodology, move the needle from theoretical potential to practical application. By making the framework open-source, the authors have not only presented a powerful new tool but have also invited the broader research community to build upon it. This paper is a clear signal that the era of intelligent, efficient, and democratized algorithmic discovery is well underway. It is a valuable read for anyone interested in program synthesis, agentic AI, and the future of automated science.