


Speed Always Wins: A Survey on Efficient Architectures for Large Language Models
Authors: Weigao Sun, Jiaxi Hu, Yucheng Zhou, Jusen Du, Disen Lan, Kexin Wang, Tong Zhu, Xiaoye Qu, Yu Zhang, Xiaoyu Mo, Daizong Liu, Yuxuan Liang, Wenliang Chen, Guoqi Li, Yu Cheng
Paper: https://arxiv.org/abs/2508.09834
Code: https://github.com/weigao266/Awesome-Efficient-Arch
TL;DR
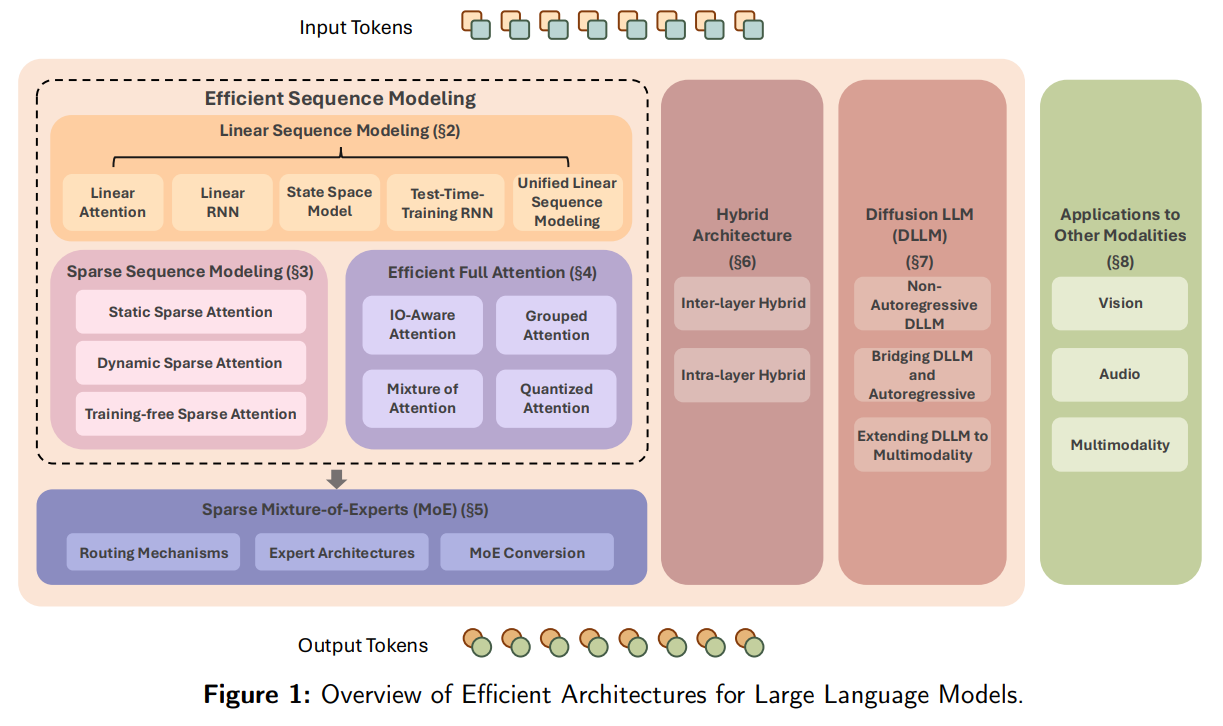
WHAT was done? This paper provides a comprehensive and systematic survey of innovative architectures designed to enhance the efficiency of Large Language Models (LLMs). The authors categorize recent advancements into seven key areas: Linear Sequence Modeling (e.g., Mamba, Linear Attention), Sparse Sequence Modeling (e.g., Longformer, dynamic sparsity), Efficient Full Attention (e.g., FlashAttention), Sparse Mixture-of-Experts (MoE), Hybrid Architectures, Diffusion LLMs, and their applications across diverse modalities like vision and audio. The survey details the core design principles, technical formulations, and hardware-level optimizations for each category, presenting a unified blueprint (Figure 1) of the current landscape. In some sense it’s the next step beyond the well-known “Efficient Transformers: A Survey” paper from 2020 (https://arxiv.org/abs/2009.06732).
WHY it matters? The traditional Transformer architecture, with its quadratic self-attention complexity, poses significant computational and financial barriers to scaling and deploying LLMs. This survey is crucial as it organizes the vast and fragmented research field dedicated to overcoming this "efficiency ceiling." By providing a structured overview of the trade-offs between different approaches—from approximating attention to conditional computation and hardware co-design—it equips researchers and practitioners with the necessary context to build more sustainable, scalable, and versatile AI systems. It maps the evolution from resource-intensive models towards architectures that can handle ultra-long contexts, power real-time agents, and operate efficiently across multiple data types, charting a clear path for the future of resource-aware foundation models.
Details
Introduction
The remarkable capabilities of Large Language Models (LLMs) are built upon the Transformer. Yet, its core self-attention mechanism is like a detective who, to understand one person's statement, insists on re-interviewing and cross-referencing every other witness every single time. It's thorough, but wildly inefficient as the number of witnesses grows. This quadratic scaling has become a major bottleneck, making large-scale deployment prohibitively expensive.
A new comprehensive survey, "Speed Always Wins," offers a much-needed blueprint for the rapidly evolving field of efficient AI. It systematically charts the diverse strategies researchers are using to break through the Transformer's efficiency ceiling, providing an organized tour of the architectural landscape, from fundamental reformulations of attention to entirely new generative paradigms.
Here’s the full ToC of the paper:

The Architectural Blueprint for Efficiency
The survey's primary contribution is its systematic categorization of efficient architectures into seven distinct but interconnected areas (Figure 3). This framework helps to understand not just individual methods, but the broader trends shaping the future of LLMs.

1. Rewriting the Rules: New Math for Attention
The most direct approach to tackling the O(N^2) complexity is to fundamentally alter the attention mechanism. The survey details two major families of solutions:
Linear Sequence Modeling (§2): This category encompasses methods that reformulate attention to achieve linear
O(N)complexity. The paper compellingly illustrates a convergence of previously distinct research lines—Linear Attention, Linear RNNs, and State Space Models (SSMs)—towards a unified framework (Figure 4).
Linear Attention approximates the standard softmax using kernel functions. By leveraging the associative property of matrix multiplication, the computation
(QK^T)Vis reordered toQ(K^T V). This is profound: the(K^T V)term can be seen as a compressed 'memory' or 'state' which is updated incrementally, allowing these models to operate in a recurrent fashion with linear complexity. The update rule is key:
State Space Models, such as the influential Mamba architecture, model sequences using a continuous-time formulation:

The key innovation in modern SSMs is making these matrices data-dependent (i.e., "selective"), allowing the model to dynamically adjust how it accumulates information based on the input, giving it the contextual power of attention with the efficiency of an RNN. The survey also unifies these models from an optimizer's perspective, framing memory updates as solving a local objective (Table 1, and there are other works unifying something, e.g. recurrences),

such as a regularized L2 loss:

Sparse Sequence Modeling (§3): Instead of calculating attention over all token pairs, these methods selectively compute a subset of interactions. The survey distinguishes between static sparsity (e.g., windowed or dilated patterns as in Longformer (https://arxiv.org/abs/2004.05150), which is efficient but fixed (Figure 7),

and dynamic sparsity, which adapts patterns to the input content. A significant portion of recent work also focuses on training-free sparsity for inference, intelligently pruning the Key-Value (KV) cache by exploiting phenomena like the "attention sink" (https://arxiv.org/abs/2309.17453) or using dynamic eviction policies.






2. Smarter, Not Harder: Optimizing the Transformer We Know
Rather than replacing components, another line of research focuses on making them more efficient.
Efficient Full Attention (§4): This section details methods that retain exact quadratic attention but optimize its implementation. The prime example is the FlashAttention series (https://arxiv.org/abs/2205.14135, the latest is FlashAttention 3, https://arxiv.org/abs/2407.08608), which is I/O-aware. The true bottleneck is often moving data between the GPU's large but slow HBM and its small but fast SRAM. FlashAttention uses 'tiling' to break the attention matrix into blocks that fit in SRAM, computing on one block at a time and avoiding writing the full N×N matrix back to HBM. Further developments like Grouped Attention (MQA, GQA, MLA) (Figure 9) tackle the inference memory bottleneck by having multiple query heads share key and value heads, drastically reducing KV cache size.

Sparse Mixture-of-Experts (MoE) (§5): To address the scaling costs of Feed-Forward Network (FFN) layers, MoE introduces conditional computation. A model contains many "expert" FFNs, but for any given token, a routing "gate" selects only a few to activate.

This allows for a massive increase in model parameters without a proportional rise in computational cost. A critical challenge is load balancing, often addressed with an auxiliary loss to encourage even distribution:

where
D(X)is the token load andG(X)is the gate's importance. The survey also covers strategies for creating MoE models by converting existing dense models (Figure 12).




3. New Paradigms: Hybrids and Diffusion
Hybrid Architectures (§6): Recognizing that no single method is perfect, hybrid models strategically combine approaches. Inter-layer hybrids might alternate between linear Mamba blocks and full attention blocks, while intra-layer hybrids could split attention heads within a single layer (Figure 13). This allows for a fine-grained trade-off between speed and expressive power.

Diffusion Large Language Models (§7): Perhaps the most paradigm-shifting area is the rise of Diffusion LLMs. These non-autoregressive models generate text not token-by-token, but by progressively denoising a sequence from a masked state (Figure 14).

This offers two advantages: parallel decoding, which can significantly reduce latency, and enhanced controllability. The training objective minimizes a cross-entropy loss over masked positions, where the prediction for each token is conditioned on the entire corrupted sequence, highlighting its global, non-autoregressive nature:



Efficiency is a Universal Language
A crucial insight from the survey is that these architectural principles are not confined to language. Section 8 details their successful application to vision, audio, and multimodal tasks (Table 2).

Linear models like Mamba are being integrated into vision backbones for tasks from classification to segmentation, while MoE is used to scale vision models to billions of parameters. This cross-modal generalization underscores that the quest for computational efficiency is a universal driver of progress.
Future Directions and Overall Assessment
The survey concludes by identifying key future research directions, including deeper algorithm-system-hardware co-design, more adaptive attention mechanisms, efficient large models with far more parameters and small models on edge devices, and the development of hierarchical memory architectures. Enhancements in MoE routing and non-autoregressive diffusion LLMs are also highly expected.
The paper's strength lies in its comprehensive scope and systematic organization, making it an invaluable resource for both newcomers and experts. It successfully synthesizes a vast and complex field into a coherent narrative. While a direct quantitative comparison of all methods is beyond the scope of a single survey, the paper provides the necessary context and technical details for readers to understand the core trade-offs.
Overall, "Speed Always Wins" is a landmark survey that provides a clear, structured, and insightful overview of this critical research area. It is an essential guide for anyone looking to build the next generation of scalable, sustainable, and powerful AI systems.