Spiking Manifesto
Authors: Eugene Izhikevich
Paper: https://arxiv.org/abs/2512.11843
Code: https://github.com/izhikevich/SNN
TL;DR
WHAT was done? The author proposes a novel Spiking Neural Network (SNN) framework that abandons the simulation of membrane potentials in favor of treating spike latencies as vectors. By mapping relative spike timings (permutations) to synaptic weights via Look-Up Tables (LUTs), the method completely eliminates Matrix Multiplications (MatMuls) from the inference loop, effectively compiling Deep Learning architectures—including Transformers and RNNs—into sparse, memory-efficient table lookups.
WHY it matters? This approach challenges the foundational efficiency bottleneck of modern AI: the O(N2) compute and memory cost of dense matrix operations. By leveraging the combinatorial explosion of spike orderings (n! states) rather than the linear capacity of vector spaces, the proposed architecture demonstrates a theoretical 10,000x reduction in memory bandwidth and significantly faster convergence rates, suggesting a viable path toward running LLM-class logic on milliwatt-scale hardware.
Details
The Matrix Multiplication Tax
The central conflict in modern deep learning is the disparity between biological efficiency and silicon brute force. While a human brain operates on roughly 20 watts, a standard Large Language Model (LLM) requires massive GPU clusters consuming megawatts. The culprit, as identified in this manifesto, is the reliance on continuous-valued activations and the ubiquitous Matrix Multiplication (MatMul). In standard Artificial Neural Networks (ANNs), information is encoded in firing rates (magnitudes), requiring expensive dot products to propagate signals. Previous attempts to bridge this gap using Spiking Neural Networks (SNNs) often failed because they focused on faithfully simulating biological ion channels or simply quantizing ANNs, missing the forest for the trees.
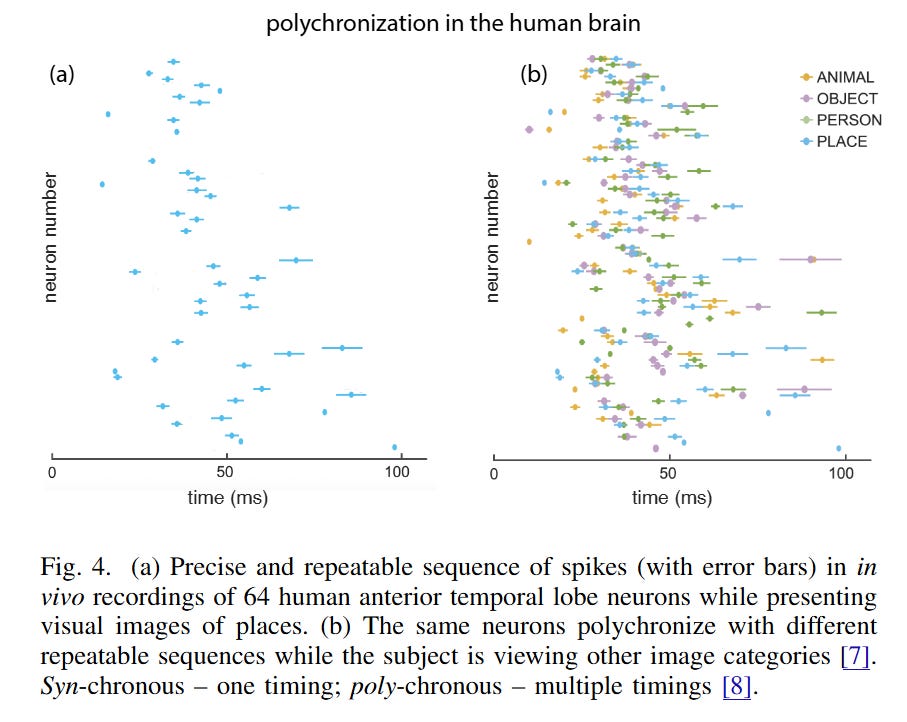
The “Spiking Manifesto” argues that the true computational advantage of the brain lies not in the spike itself, but in polychronization—the precise relative timing of spikes. The author posits that we must abstract away the voltage dynamics of individual neurons and instead model the transition from one spatial-temporal spiking pattern to another. By treating the state of the network as a vector of latencies rather than magnitudes, the dense matrix operations optimized by GPUs are revealed to be an inefficient emulation of what biology implements as a high-dimensional hash map.