
The Free Transformer
A Latent-Variable Approach to Boost Reasoning
Authors: François Fleuret
Paper: https://arxiv.org/abs/2510.17558
Code: Not available
Model: Not available
TL;DR
WHAT was done? The paper introduces the “Free Transformer,” an extension of the standard decoder-only Transformer that conditions its generative process on random latent variables. This is achieved by reformulating the architecture as a Conditional Variational Autoencoder (CVAE). The key innovation is an exceptionally efficient design where the latent variable is injected into the decoder’s middle layer, allowing the encoder and decoder to share the first half of the Transformer blocks. This adds only one extra non-causal Transformer block and results in a minimal computational overhead of just 3-4%.
WHY it matters? This work challenges the long-standing paradigm of purely autoregressive generation. By allowing the model to learn and condition on explicit, high-level latent decisions (e.g., topic, sentiment, or problem structure), it provides a more powerful inductive bias. The results are compelling: without any special tuning of the baseline optimizer, the Free Transformer shows substantial performance improvements on complex reasoning, math, and code generation benchmarks (e.g., HumanEval+, GSM8K, MBPP). This suggests that providing models with the “freedom” to structure their generation via latent variables is a more efficient path to enhanced reasoning capabilities than relying solely on scaling up autoregressive models.
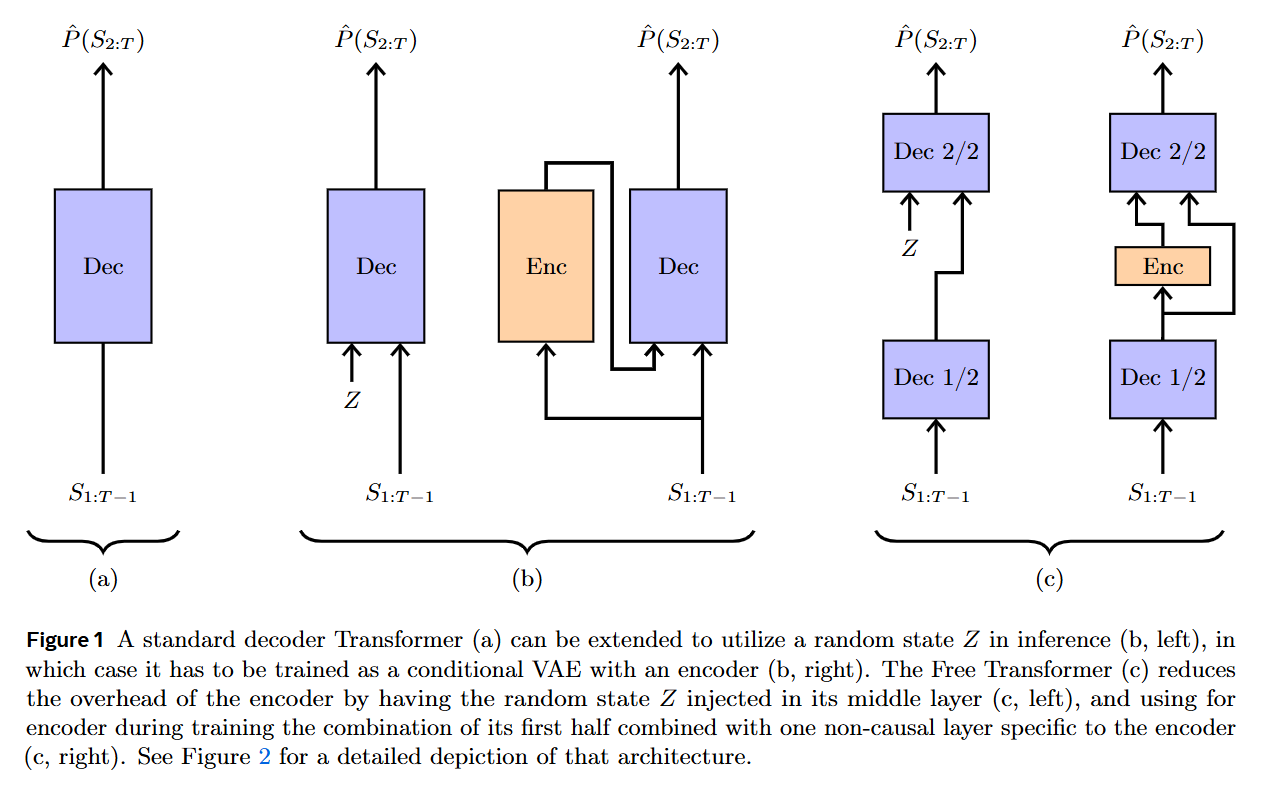
Details
The Limitation of Pure Autoregression
Since their inception, decoder-only Transformers like the GPT series have operated on a simple, powerful principle: autoregressive next-token prediction. This approach, governed by the chain rule, forces the model to encode all high-level structure—be it the sentiment of a review, the topic of an essay, or the logic of a program—implicitly within the sequence of token probabilities. The authors of “The Free Transformer” argue that this reliance on post-hoc inference from previously generated tokens is a fundamental constraint, leading to unnecessarily complex models that can be brittle and struggle to form abstract concepts spontaneously.
To make this concrete, the paper offers a simple analogy: imagine a process where you first flip a coin (a latent decision, Z) and then generate a sequence of tokens that are all “heads” or “tails” based on that initial flip, with a small chance of error. For a model that has access to the latent coin flip Z, this is a trivial task. However, a purely autoregressive model, which cannot “see” Z, must infer the original coin flip from the noisy sequence of tokens it has generated so far. This requires a much more complex function and can easily be thrown off by a few erroneous tokens, illustrating how autoregressive models can be an inefficient way to represent processes with a “natural” latent structure.
