
The Principles of Diffusion Models
Authors: Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, Stefano Ermon
Paper: https://arxiv.org/abs/2510.21890
TL;DR
WHAT was done? This 470-pages monograph presents a unified theoretical framework for diffusion models, demonstrating that the three historically distinct approaches—the variational view (e.g., DDPM), the score-based view (e.g., Score SDE), and the flow-based view (e.g., Flow Matching)—are mathematically equivalent. They all converge on the same core principle: learning a time-dependent vector field to reverse a fixed forward corruption process. The authors show that this entire generative process is governed by a single differential equation (the Probability Flow ODE), with its consistency guaranteed by the Fokker-Planck equation. The work further proves that the various prediction targets used in training (noise, clean data, score, or velocity) are algebraically interchangeable, clarifying that their differences are matters of implementation and stability, not fundamental modeling capacity.
WHY it matters? This work transforms the art of designing diffusion models into a science. By providing a unified differential equation framework, it replaces a collection of disparate heuristics with a principled engineering discipline. This “first principles” understanding is crucial for systematically developing faster samplers (like DPM-Solver), enabling robust and controllable generation (via guidance), and designing the next generation of highly efficient, standalone generative models (like Consistency Models). These new models learn the solution map directly from data, resolving the long-standing trade-off between sample quality and speed and paving the way for more powerful and practical generative AI.

Details
From a Cambrian Explosion to a Unified Theory
The field of generative AI has witnessed a Cambrian explosion fueled by diffusion models. From DDPMs and Score SDEs to Flow Matching, a dizzying array of formulations have emerged, each with its own intuition and mathematical machinery. This rapid progress, while powerful, has often felt fragmented, leaving researchers to navigate a complex landscape of seemingly disconnected ideas.

The new monograph, “The Principles of Diffusion Models,” serves as a much-needed Rosetta Stone. It doesn’t introduce a new model but rather provides something more profound: a unified theory that synthesizes the entire field. The authors trace the intellectual lineages of modern diffusion models back to their distinct origins and demonstrate how these separate paths converge on a single, elegant mathematical framework. The core narrative is clear: generative modeling with diffusion is fundamentally a problem of solving a differential equation.
The Three Paths to a Single Destination
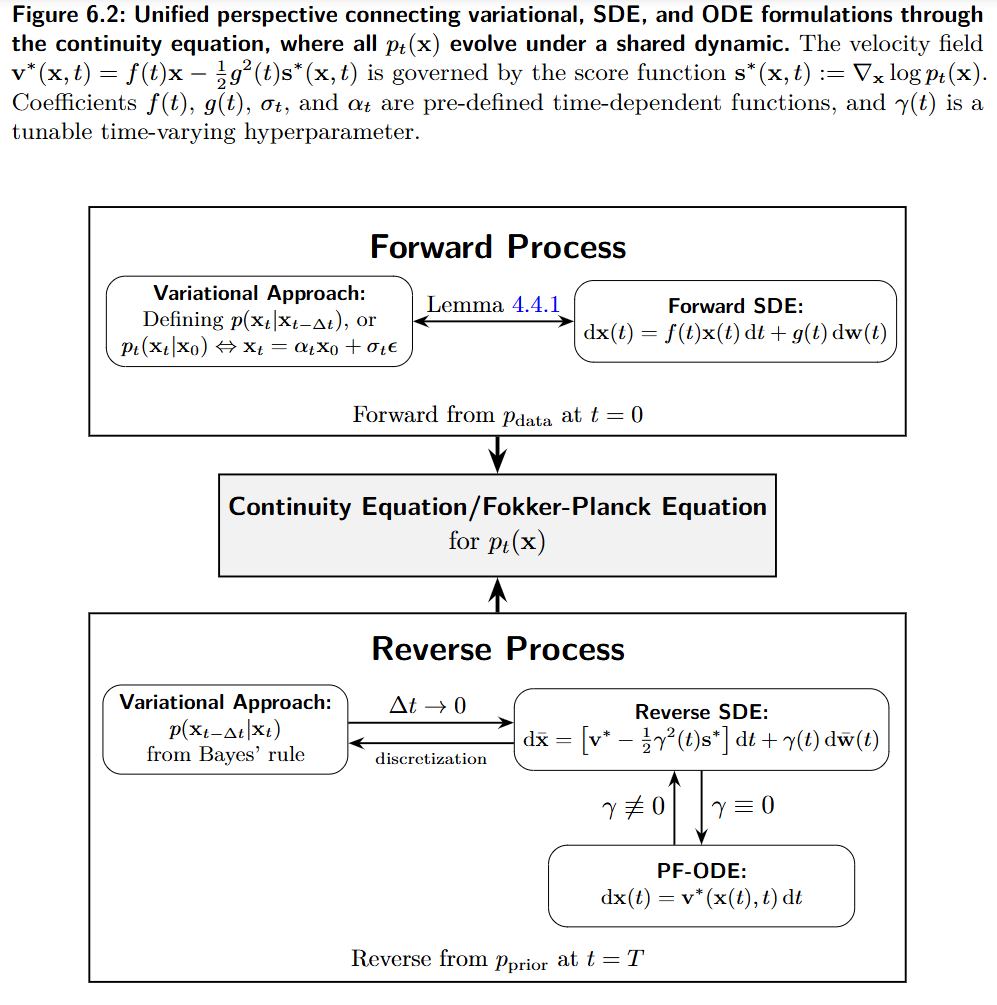
The monograph begins by outlining the three foundational perspectives on diffusion models, each originating from a classic generative modeling paradigm (Figure 2):
The Variational View: Stemming from Variational Autoencoders (VAEs), this path leads to Denoising Diffusion Probabilistic Models (DDPMs) (Ho et al., 2020, https://arxiv.org/abs/2006.11239). Generation is framed as a hierarchical denoising process, where the model learns to reverse a fixed, multi-step noising process by maximizing a variational lower bound (ELBO) on the data likelihood.
The Score-Based View: Rooted in Energy-Based Models (EBMs), this perspective focuses on learning the score function (∇xlogp(x))—the gradient of the log data density. This vector field points toward regions of higher probability, and by following it, one can transform noise into data. This leads to models like Noise Conditional Score Networks (NCSN) and the continuous-time Score SDE framework (Song et al., 2020c, https://arxiv.org/abs/2011.13456).
The Flow-Based View: Inspired by Normalizing Flows (NFs) and Neural ODEs, this approach models generation as a deterministic transport process. A learned velocity field governs a continuous flow that transforms a simple prior distribution into the complex data distribution, as generalized by Flow Matching (FM) (Lipman et al., 2022, https://arxiv.org/abs/2210.02747).
The Grand Unification: The PF-ODE and Its “Secret Sauce”
The monograph’s central thesis is that these three paths are not just analogous but mathematically equivalent. They are different lenses for viewing the same underlying generative process: a continuous-time flow governed by a differential equation.
This unification is built on two pillars:
1. The Probability Flow ODE (PF-ODE)
The authors show that the generative process in all three frameworks can be described by a single deterministic differential equation, the theoretical Probability Flow ODE:
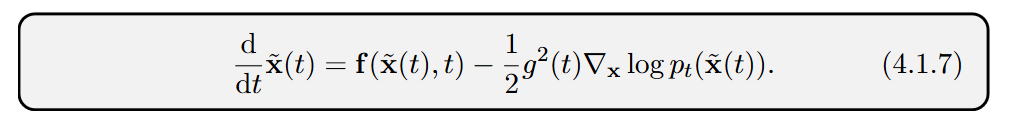
In practice, the true score ∇xlogp_t(x(t)) is unknown and is replaced by a trained neural network s_ϕ×(x(t),t), giving the empirical ODE used for sampling. The consistency between this deterministic ODE and its stochastic (SDE) counterparts is guaranteed by the Fokker-Planck equation. This master equation describes how the probability density p_t(x) evolves over time for the forward SDE, and the PF-ODE is constructed such that its flow of samples obeys the exact same law, ensuring both processes share the same marginal distributions (Figure 6.2).
2. The “Conditioning Trick” for Tractable Training
A crucial insight that enables this entire framework is what the authors call the “secret sauce”: the conditioning trick. The core training objectives are intractable because they require the score of the marginal density p_t(x_t), which involves an integral over the unknown data distribution. The conditioning trick elegantly bypasses this by making the regression target the score of the conditional density p_t(x_t∣x_0), which is a known Gaussian and has a simple, analytical form.
All training losses for diffusion models ultimately reduce to a unified template
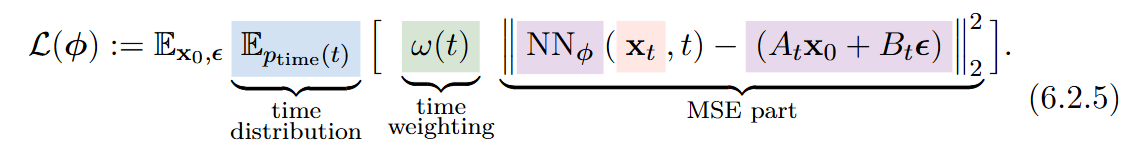
where x_t=α_t x_0 + σ_t ϵ. The neural network NNϕ is trained to predict a specific target constructed from the clean data x_0 and the noise ϵ. The choice of prediction—noise (ϵ), clean data (x_0), score (s), or velocity (v)—simply changes the coefficients At and Bt (Table 6.1).
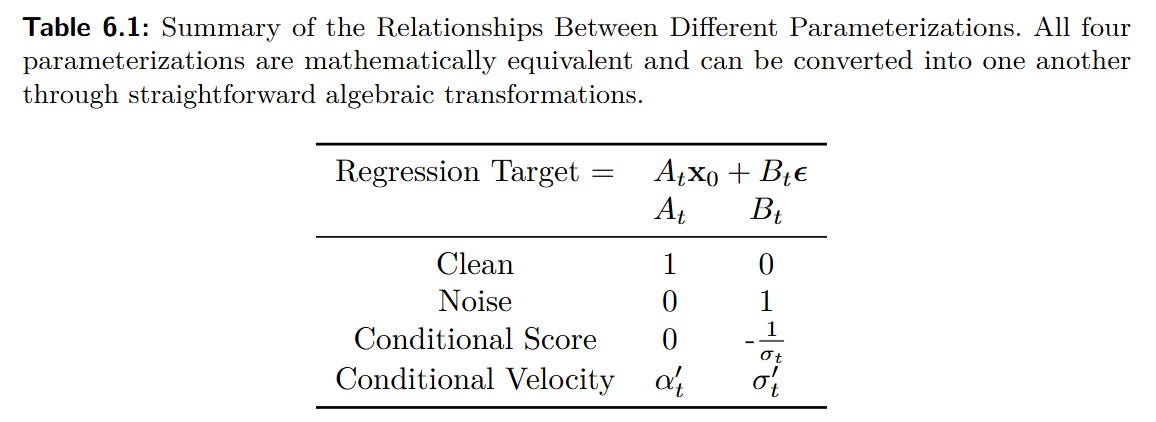
This proves that all common parameterizations are algebraically equivalent, with the practical choice depending on numerical stability rather than fundamental modeling capacity.
From Theory to Practice: Accelerating and Controlling Generation
With the unified framework in place, the monograph systematically explores the two primary practical challenges in diffusion modeling: control and speed.
Controllable Generation via Guidance Guidance techniques are elegantly explained through the Bayesian decomposition of the conditional score (Equation 8.1.1).

Classifier-Free Guidance (CFG), for instance, models the conditional score as a linear combination of the unconditional and conditional scores:
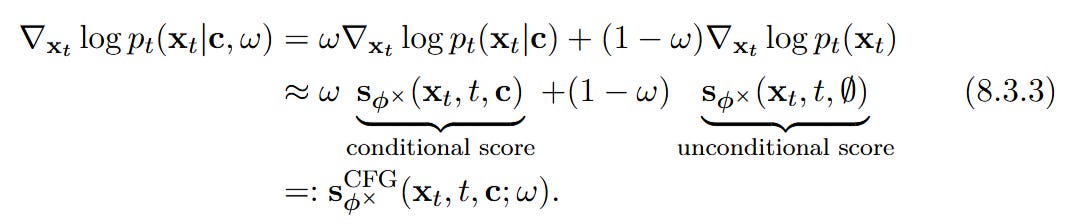
This provides a principled way to steer the ODE solver toward desired attributes during generation.
Accelerating Sampling: From Better Solvers to Direct Maps The monograph dedicates its final part to the critical problem of slow sampling, structuring the solutions into two major paradigms:
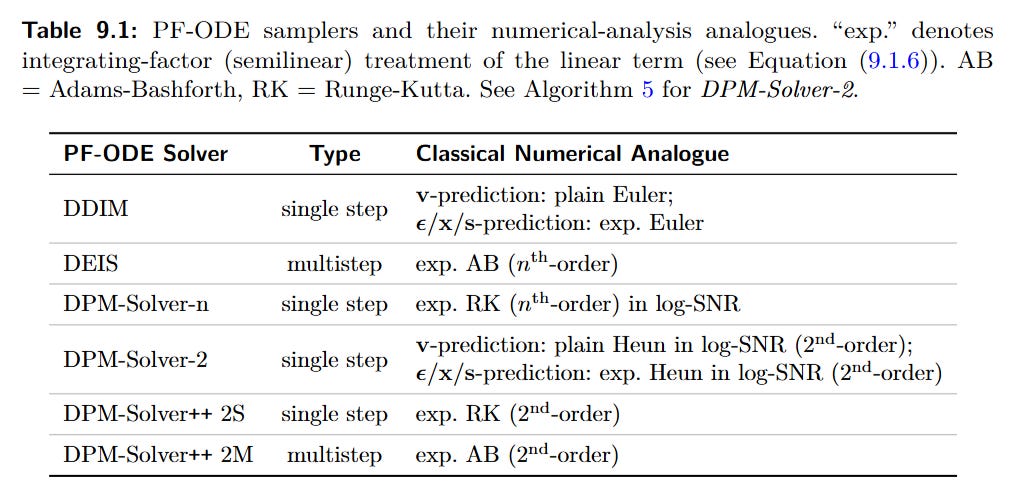
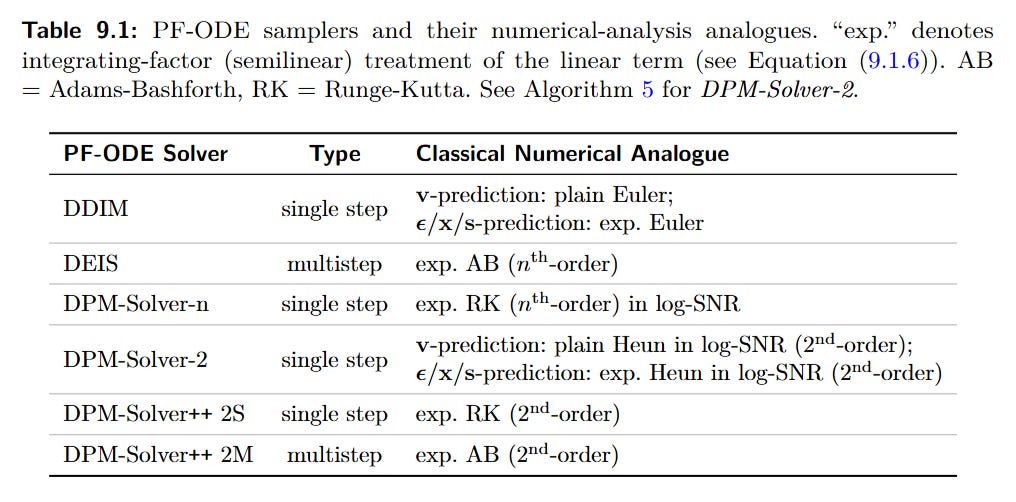
Training-Free Acceleration (Improving the Solver): This approach treats the trained diffusion model as a fixed vector field and focuses on developing better numerical ODE solvers. The monograph details the evolution from DDIM (an exponential-Euler method) to higher-order solvers like DEIS (Zhang and Chen, 2022, https://arxiv.org/abs/2204.13902) and the DPM-Solver family (Lu et al., 2022b, https://arxiv.org/abs/2206.00927), which achieve massive speedups by leveraging the semi-linear structure of the PF-ODE and a clever log-SNR time reparameterization (Table 9.1).
Training-Based Acceleration (Learning the Solution Map): This represents the current frontier. Instead of improving the iterative solver, these methods learn the ODE’s solution map, Ψs→t, directly.
Distillation: A student model is trained to replicate the multi-step trajectory of a pre-trained teacher model in fewer steps (e.g., Progressive Distillation).
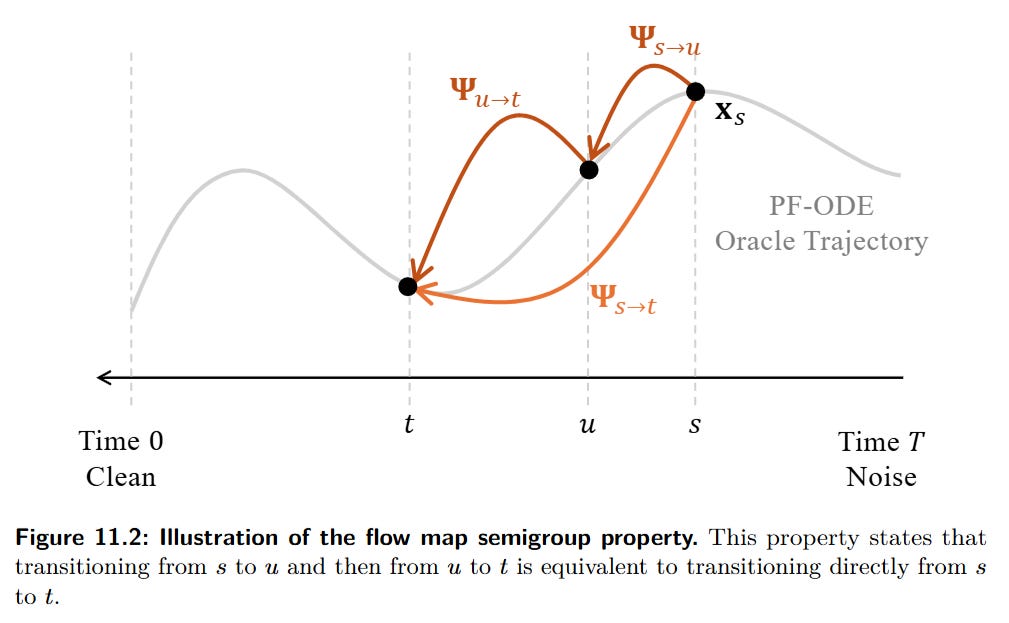
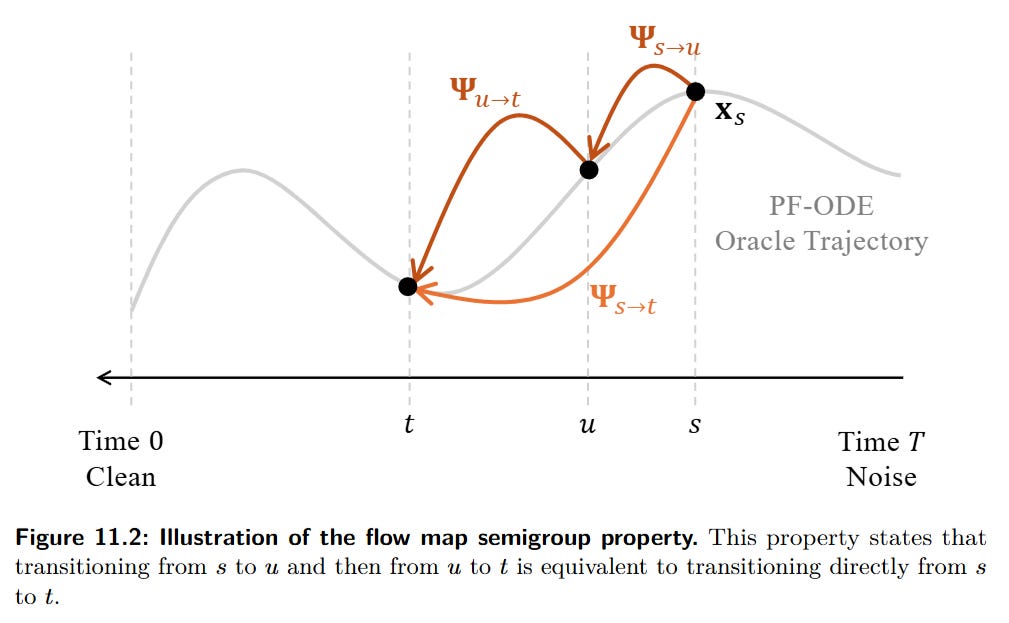
Learning from Scratch: The most advanced approach, exemplified by Consistency Models (CMs) (Song et al., 2023, https://arxiv.org/abs/2303.01469), trains a fast, few-step generator without any teacher. This is achieved by enforcing the semigroup property of ODE flows
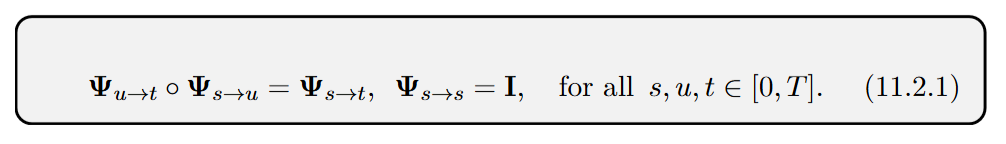
which provides a powerful self-supervisory signal. Intuitively, this allows the model to teach itself by ensuring that a single large jump produces the same result as a sequence of smaller jumps, removing the need for a pre-trained teacher (Figure 11.2).
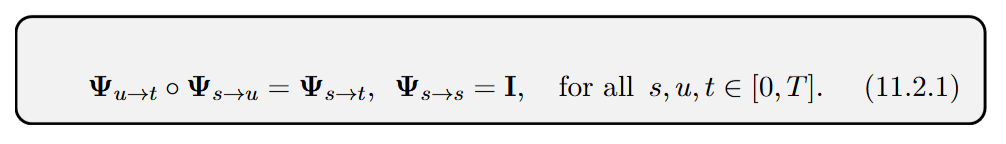
Limitations and Future Directions
The monograph is a theoretical masterpiece but is not a practical implementation guide; it intentionally omits details on specific architectures, hyperparameters, and datasets. It also highlights open theoretical questions, most notably the gap between the PF-ODE flow and a truly “optimal” transport map from classical OT theory—the paths diffusion models take are efficient, but not necessarily the most efficient possible.
The future is clear: designing standalone, one-step generative principles that are efficient, controllable, and stable. The work on Consistency Models and Mean Flow points the way, suggesting that by directly learning the solution map of the underlying physical process, we can build generative models that are both powerful and practical.
Conclusion
“The Principles of Diffusion Models” is a landmark contribution that provides a clear, unified, and mathematically rigorous foundation for one of the most important technologies in modern AI. By synthesizing a decade of research into a single coherent framework, it demystifies why diffusion models work and provides a principled roadmap for future innovation. It is essential reading for any researcher aiming to understand, improve, or build upon the current generation of generative models. This monograph doesn’t just describe a field; it defines it.