The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding
Authors: Weichen Fan, Haiwen Diao, Quan Wang, Dahua Lin, Ziwei Liu
Paper: https://arxiv.org/abs/2512.19693
Code: https://github.com/WeichenFan/UAE
TL;DR
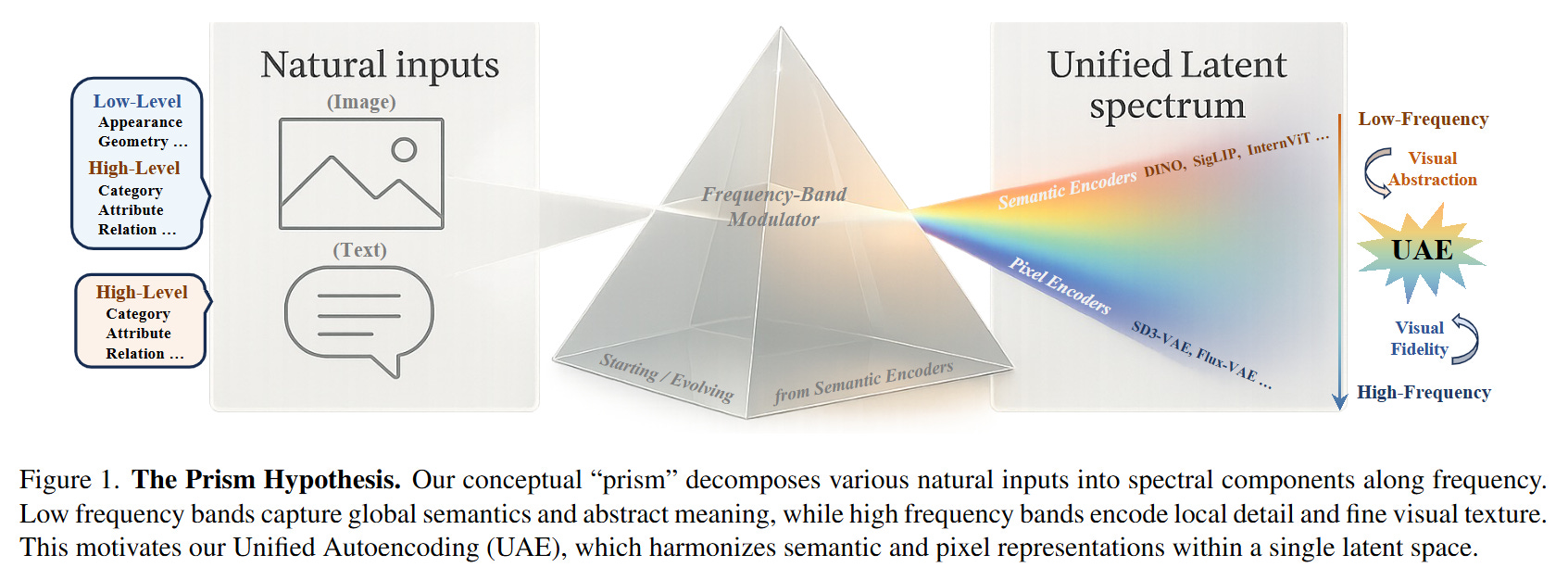
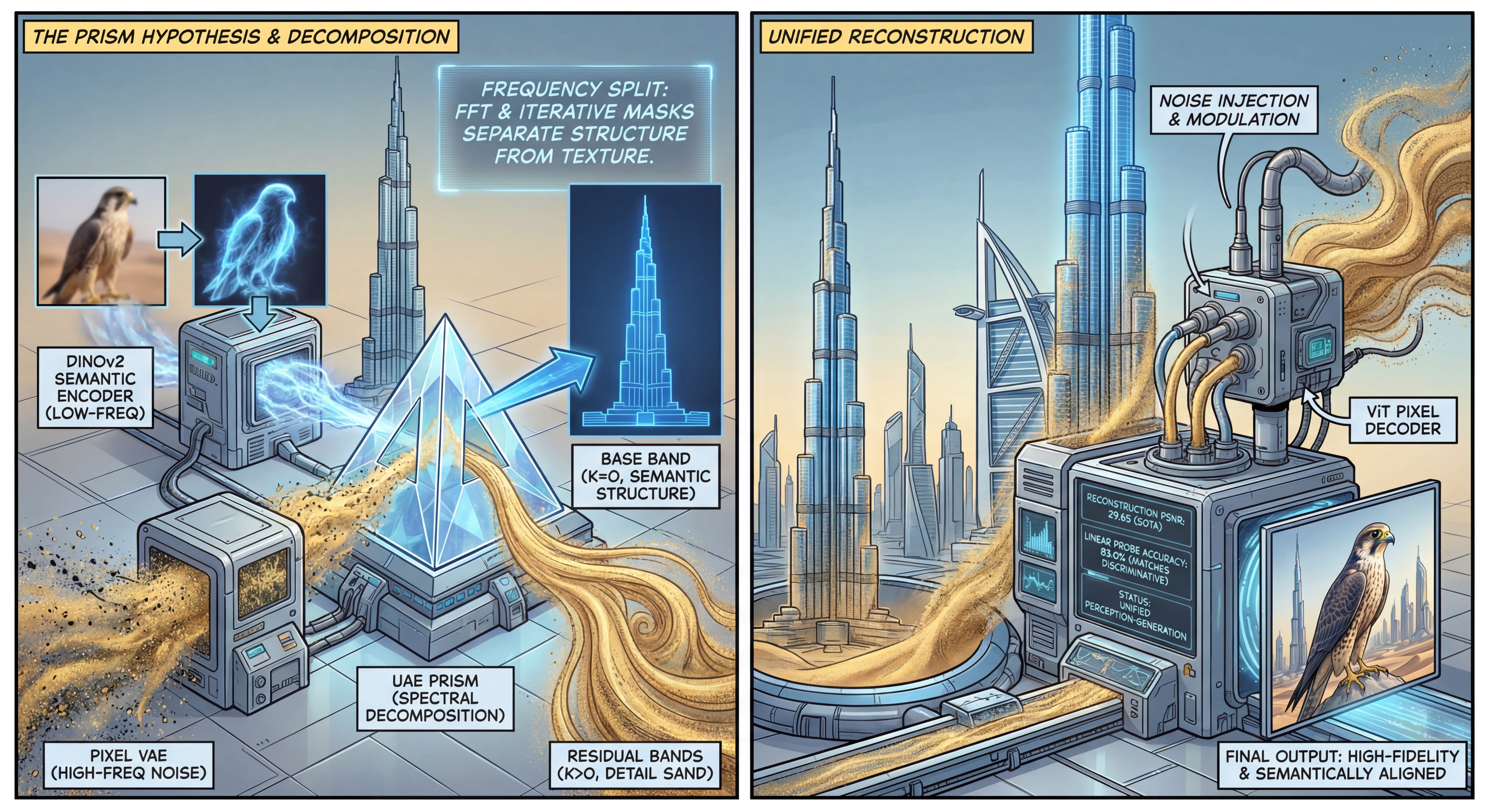
WHAT was done? The authors propose the “Prism Hypothesis,” positing that the tension between semantic understanding (e.g., DINO) and visual generation (e.g., VAEs) is a frequency-domain problem: semantics reside in low frequencies, while details reside in high frequencies. Based on this, they introduce Unified Autoencoding (UAE), a tokenizer that decomposes pretrained semantic latents into frequency bands. It retains a semantic base band aligned with the teacher model while offloading fine-grained reconstruction details to residual high-frequency bands.
WHY it matters? Current foundation models rely on disjoint architectures—separate encoders for understanding and decoding for generation—creating significant inefficiency and representation misalignment. UAE demonstrates that a single latent space can achieve state-of-the-art reconstruction (beating RAE and SVG) while maintaining the high linear-probing accuracy of discriminative models, effectively unifying perception and generation without the typical trade-offs.
Details
The Perception-Generation Gap
A central friction in modern deep learning architecture is the dichotomy between “looking” and “creating.” Semantic encoders like DINOv2 or CLIP excel at capturing abstract concepts—such as identifying “a golden retriever”—but discard the high-frequency textures required for faithful reconstruction. Conversely, pixel-space autoencoders (like the VAEs in Stable Diffusion) prioritize high-fidelity reconstruction but produce latents that are semantically opaque. Recent efforts such as RAE and UniFlow have attempted to bridge this by forcing diffusion models to work directly with semantic latents or by distilling semantics into pixel encoders. However, these methods often result in a “tug-of-war,” leading to either blurred reconstructions or diminished semantic discriminability. The authors of UAE argue that this is not just an architectural issue, but a signal processing one: semantics and pixels are simply different spectral slices of the same signal.