
ThreadWeaver: Adaptive Threading for Efficient Parallel Reasoning in Language Models
Authors: Long Lian, Sida Wang, Felix Juefei-Xu, Tsu-Jui Fu, Xiuyu Li, Adam Yala, Trevor Darrell, Alane Suhr, Yuandong Tian, Xi Victoria Lin
Paper: https://arxiv.org/abs/2512.07843
TL;DR
WHAT was done? The authors introduce ThreadWeaver, a framework that enables Large Language Models (LLMs) to dynamically break sequential Chain-of-Thought (CoT) reasoning into concurrent threads. By training the model to output specific control tokens (<Parallel>, <Thread>) and leveraging a trie-based attention mechanism during training, the system allows for “fork-join” execution patterns. They further refine this behavior using a modified reinforcement learning algorithm, P-GRPO, which optimizes for both answer correctness and reduced critical path length.
WHY it matters? Inference latency for complex reasoning tasks typically scales linearly with chain length (O(N)), creating a bottleneck for “System 2” scaling. ThreadWeaver demonstrates that it is possible to maintain state-of-the-art accuracy (matching sequential baselines like Qwen3-8B) while achieving significant wall-clock speedups (up to 1.53x). Crucially, it achieves this compatibly with standard inference engines (e.g., vLLM) without requiring custom CUDA kernels or specialized KV-cache management.
Details
The Latency Bottleneck in System 2 Scaling
The current paradigm for advanced reasoning relies heavily on test-time compute scaling, where models generate extensive Chain-of-Thought (CoT) sequences to navigate complex problem spaces. However, autoregressive decoding imposes a rigid sequential constraint: a reasoning trace that requires 10,000 tokens incurs a latency penalty proportional to 10,000 steps, regardless of the available compute capacity. While techniques like Skeleton-of-Thought or Tree of Thoughts attempt to introduce parallelism, they often rely on static heuristics or result in significant performance degradation compared to sequential baselines. Recent adaptive approaches, such as Multiverse, have struggled to balance the trade-off, often sacrificing reasoning accuracy for parallelism. ThreadWeaver addresses this specific “Pareto inefficiency” by learning to parallelize adaptively—forking only when the problem structure permits—thereby utilizing abundant parallel compute to reduce wall-clock time without degrading the logical coherence of the solution.
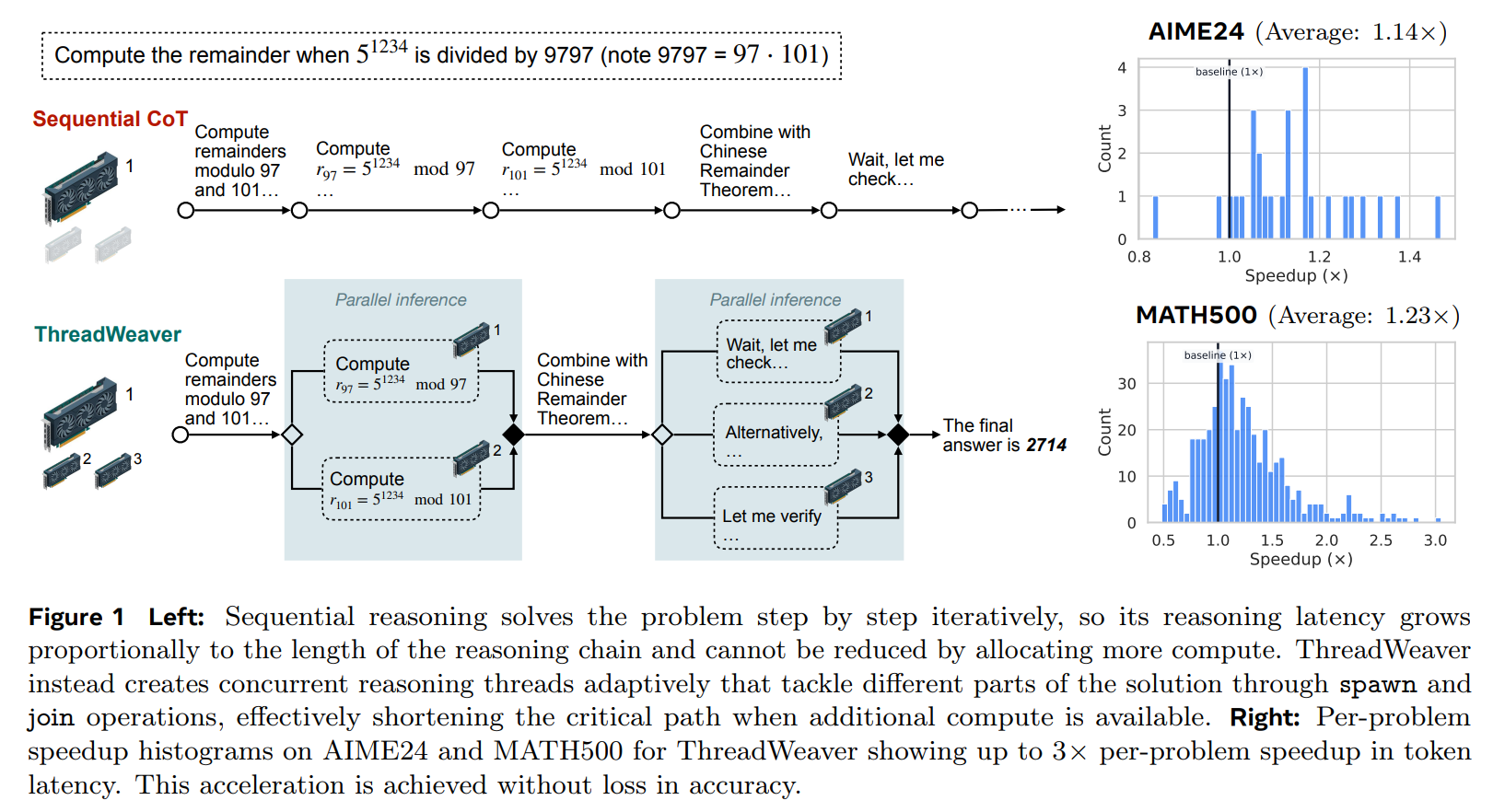
First Principles: The Fork-Join DSL
Keep reading with a 7-day free trial
Subscribe to ArXivIQ to keep reading this post and get 7 days of free access to the full post archives.