ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration
Authors: Hongjin Su, Shizhe Diao, Ximing Lu, Mingjie Liu, Jiacheng Xu, Xin Dong, Yonggan Fu, Peter Belcak, Hanrong Ye, Hongxu Yin, Yi Dong, Evelina Bakhturina, Tao Yu, Yejin Choi, Jan Kautz, Pavlo Molchanov
Paper: https://arxiv.org/abs/2511.21689
Code: https://github.com/NVlabs/ToolOrchestra/
Data: https://huggingface.co/datasets/nvidia/ToolScale
Model: https://huggingface.co/nvidia/Orchestrator-8B
Webpage: https://research.nvidia.com/labs/lpr/ToolOrchestra
TL;DR
WHAT was done? The authors introduce ToolOrchestra, a framework for training lightweight language models (specifically an 8B parameter model) to act as routing controllers for a suite of diverse tools and stronger “expert” models (such as GPT-5). By utilizing Group Relative Policy Optimization (GRPO) on a massive synthetic dataset called ToolScale, the resulting Orchestrator learns to balance task accuracy with computational cost and user preferences.
WHY it matters? This research challenges the “monolithic” scaling hypothesis by demonstrating that an 8B model, when properly trained to coordinate external resources, can outperform frontier models like GPT-5 on complex benchmarks like Humanity’s Last Exam (HLE) while reducing inference costs by roughly 70%. It validates the strategic shift from single giant models to compound AI systems where intelligence emerges from orchestration rather than parameter count.

Details
The Bias of Monolithic Agents
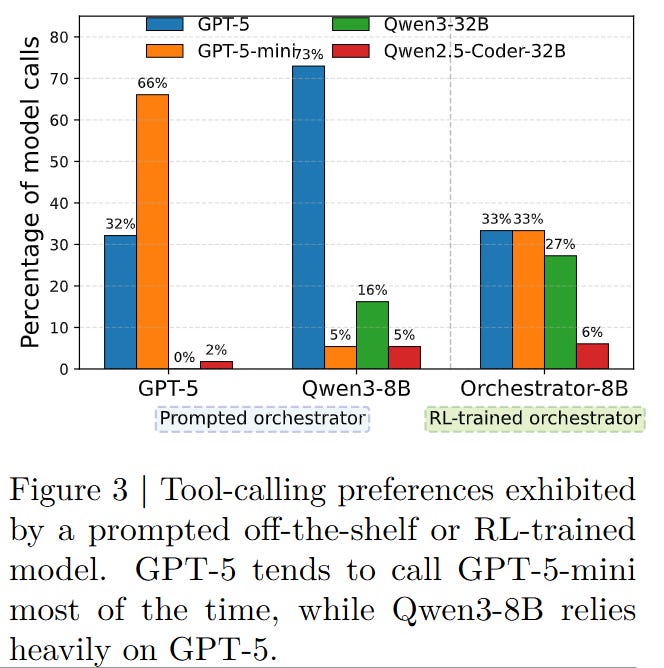
The current paradigm in agentic AI relies heavily on the “God Model” approach, where a single frontier model (like GPT-5 or Claude Opus) is expected to handle everything—from creative writing to Python execution—often defaulting to its internal weights even when external tools would be more efficient. A significant bottleneck identified in this work is the phenomenon of self-enhancement bias. When a large model is prompted to orchestrate tools, it disproportionately favors calling developmentally related variants of itself or the strongest available model, regardless of the task’s actual difficulty. As illustrated in the authors’ pilot study (Figure 3), GPT-5 defaults to calling GPT-5-mini or itself nearly 98% of the time, ignoring cost-effective alternatives. This leads to a system that is accurate but economically ruinous and computationally wasteful. The industry needs a mechanism that decouples the planner from the executor, allowing a cheaper “frontal lobe” to assign work to the most appropriate “muscle.”