
Topological Neural Operators [deep math version]
Authors: Lennart Bastian, Samuel Leventhal, Mustafa Hajij, Tolga Birdal
Paper: https://arxiv.org/abs/2606.09806
Code: N/A
Model: N/A
This is a math-heavy version of the review. There is a math-lite version of the same post here. Please, click 💖 Like on the version you prefer!
TL;DR
WHAT was done? The authors introduce Topological Neural Operators (TNOs) and Hierarchical TNOs (HTNOs), a new class of neural operators that represent physical data as multi-rank cochains on cell complexes. By utilizing Discrete Exterior Calculus (DEC), the framework enforces cross-dimensional physical routing through fixed topological operators while leaving the feature-mixing transformations to be learned.
WHY it matters? Traditional point-centric neural operators collapse physical fields (e.g., fluxes, circulations) onto nodes, forcing the model to implicitly relearn geometric types, orientations, and algebraic identities. TNOs structurally guarantee core conservation laws, such as the boundary of a boundary being empty (d∘d=0), offering discretization-invariant learning, superior accuracy on irregular meshes, and a unified path toward physics-respecting scientific foundation models.
Details
The Point-Centric Bottleneck in Continuum Physics
Modern deep learning surrogates for partial differential equations (PDEs) have achieved significant speedups over classical numerical solvers. Despite their success, established architectures like Fourier Neural Operators (FNOs) and their geometric or graph-based successors remain fundamentally point-centric. They model physical quantities strictly as functions defined on points or nodes, resolving spatial interactions through learned kernels or node-to-node message passing. This abstraction directly contradicts the geometric nature of continuum physics, where physical quantities have native dimensional supports. Potentials live on vertices, circulations along edges, fluxes across faces, and densities within volumes. When point-based networks collapse these multi-rank fields to a single node-level representation, they obscure structural orientations and conservation laws. Consequently, the network is forced to approximate these exact algebraic relationships through data-driven regularization, leading to poor generalization, physical inconsistencies, and a failure to scale across complex multi-physics systems.
Discrete Exterior Calculus First Principles: The Cochain Paradigm
To address this structural mismatch, the proposed framework models physical domains as regular cell complexes, denoted by K, rather than unstructured graphs. The fundamental mathematical entities in this setting are k-cochains, which represent physical fields integrated over k-dimensional cells. Formally, a vector-valued k-cochain is defined as a mapping uk:Kk→Rdk assigning a dk-dimensional feature vector to each k-cell in Kk, where k=0 represents vertices, k=1 represents edges, k=2 represents faces, and k=3 represents volumes. The topology of the complex is encoded via the signed incidence matrix Bk∈Rnk−1×nk, which tracks boundary relations and orientations. The discrete exterior derivative, defined as the transpose of the incidence matrix dk=Bk+1⊤, acts as the topological operator that lifts a k-cochain to a (k+1)-cochain. Crucially, the diamond condition BkBk+1=0 translates to the discrete identity dk+1∘dk=0, guaranteeing that curl-of-gradient and div-of-curl operations vanish by construction. To capture the geometry of the domain, the framework equips the cochain space with positive-definite Hodge star matrices Mk∈Rnk×nk, which encode metric properties like edge lengths and face areas. This allows the definition of the codifferential operator δk=Mk−1−1BkMk mapping cochains downward in rank, as well as the discrete k-Hodge Laplacian Δk=δk+1dk+dk−1δk. By decomposing the cochain space using the Hodge Decomposition Theorem, any signal can be orthogonally split into exact, coexact, and harmonic subspaces, providing a rigorous mathematical foundation for information routing.
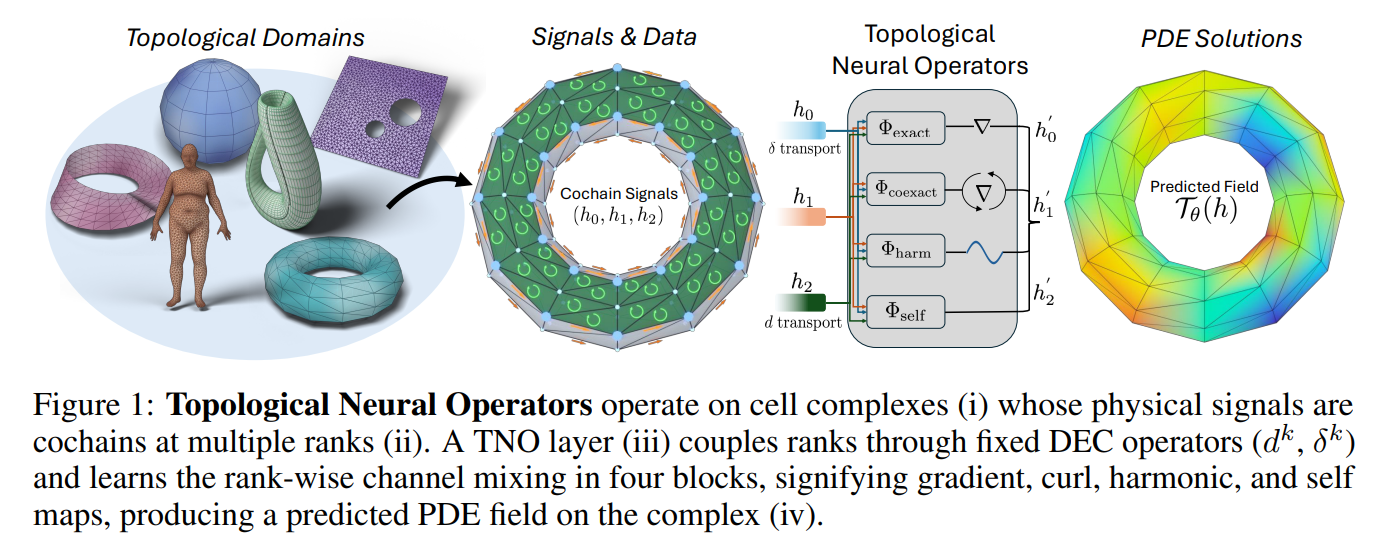
The Topological Operator Mechanism: Structural Routing of Physics
The core design principle of the TNO layer is to decouple where information flows, which is fixed by the topology, from how it is transformed, which is learned. As illustrated in Figure 1 and Figure 2, a TNO layer processes and couples cochains of multiple ranks simultaneously.
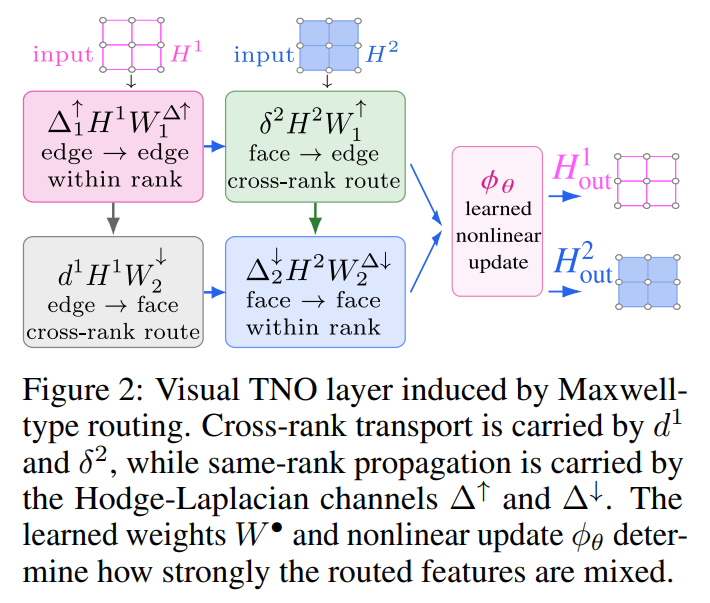
Let Hℓk denote the hidden cochain features of rank k at layer ℓ. The general residual update for a TNO layer takes the form:
where dk−1 is the exterior derivative mapping upward, δk+1 is the codifferential mapping downward, Δk↑=δk+1dk is the upper Hodge Laplacian, and Δk↓=dk−1δk is the lower Hodge Laplacian. The learnable parameters are the channel-mixing matrices W∙ and the nonlinear function ϕθ.
To understand this mechanism concretely, consider a running example of a Maxwell system where the electric field E is represented as an edge 1-cochain h1 and the magnetic flux B as a face 2-cochain h2. When updating the edge features to Hℓ+11, the exact channel uses the discrete gradient d0 to pull potential-driven information from the vertices. Concurrently, the coexact channel applies the codifferential δ2 to transport flux-type updates from neighboring faces down to the edges. Same-rank interactions are distributed across the upper and lower Hodge Laplacians to separate face-mediated curl-type propagation from vertex-mediated divergence-type propagation. The learnable channel-mixing weights determine the strength of the interaction, but the pathway is strictly dictated by the DEC operators. This prevents the network from diffusing information across arbitrary spatial neighbors, ensuring that conservation laws are structurally respected.
Multigrid Coarsening and Hierarchy
For complex physical domains, local operators are insufficient for capturing global topological features and long-range effects. The authors address this by introducing Hierarchical TNOs (HTNOs), which arrange TNO blocks into a learned V-cycle over a sequence of coarsened complexes, as detailed in Figure 14.
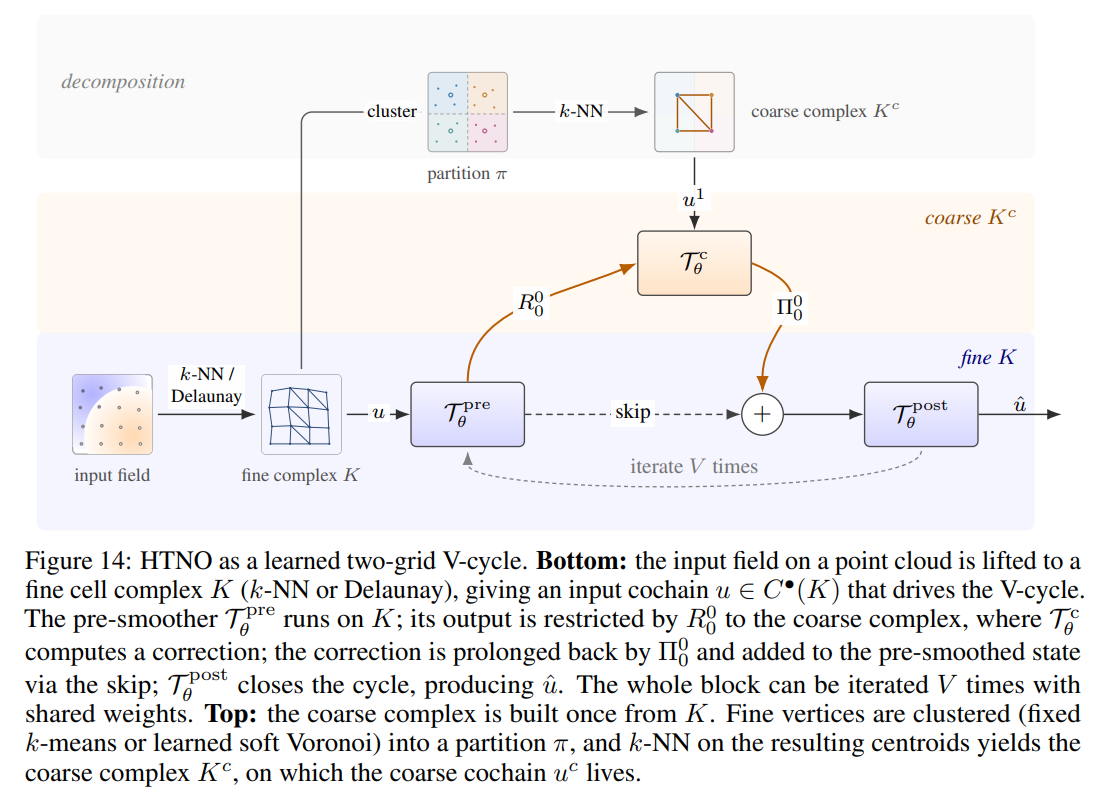
At each level ℓ, cochains are transferred via degree-preserving restriction Rℓk and prolongation Πℓk operators. Rather than imposing rigid, analytically derived grid transfers which can be mathematically intractable on arbitrary meshes, the partition π is learned end-to-end as a soft Voronoi diagram over vertex coordinates. To stabilize this clustering and prevent centroids from collapsing, auxiliary spread and entropy losses are applied directly to the assignment matrices. Once the coarse complex is established, its own incidence matrices and Hodge star operators are computed, allowing TNO blocks on the coarse grid to run multi-rank updates. This hierarchical structure functions as a Hodge-compatible smoother, where fine blocks resolve local, high-frequency physical components and the coarse grid handles low-frequency, global topological modes.
All TNO and HTNO architectures are implemented using JAX and are accelerated via LayerNorm, Swish activations, and residual connections to stabilize training. Models are trained using the AdamW optimizer with a cosine-decay schedule, weight decay, and gradient clipping set to 1.0. High-performance training was executed on a cluster of NVIDIA GH200 GPUs.
Quantifying the Topological Advantage on Irregular PDE Domains
The authors validate TNO and HTNO against a comprehensive suite of steady-state PDE benchmarks on irregular 2D and 3D geometries, contrasting performance with established baselines such as RIGNO and GAOT. As shown in Table 1, TNO and HTNO set new performance standards on traditional datasets. On the Poisson-Gauss benchmark, TNO achieves a relative L1 test error of 1.03%, compared to 2.26% for RIGNO-18. On Elasticity, HTNO leads with an error of 1.70%, outperforming RIGNO-18 (4.31%) and GAOT (4.07%).
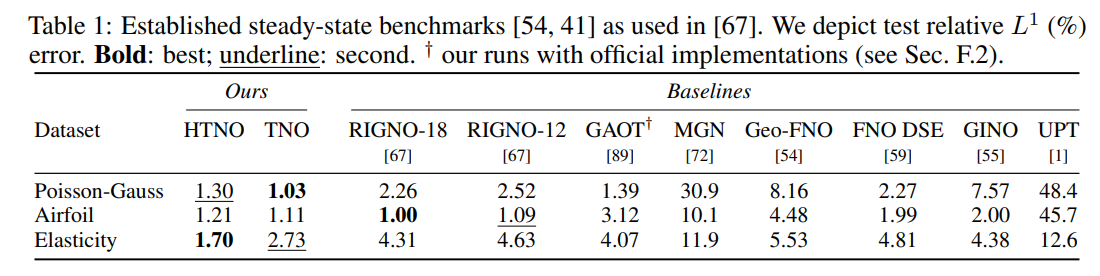
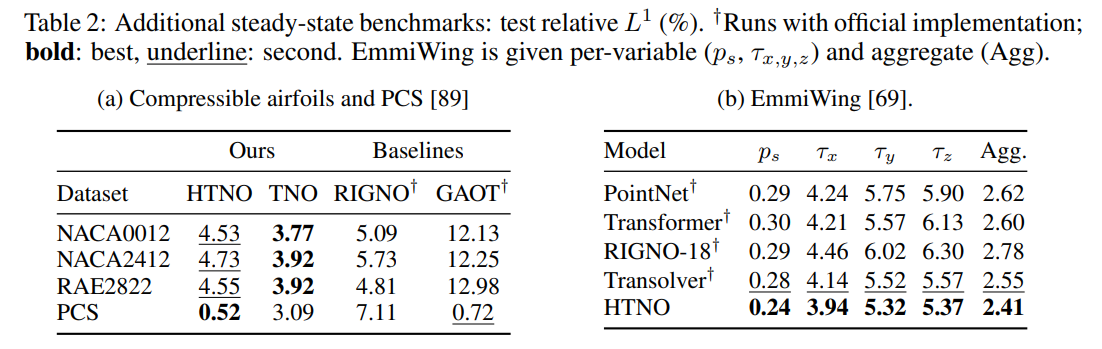
Similarly, on the large-scale 3D surface aerodynamics benchmark EmmiWing (Table 2b), HTNO produces an aggregate error of 2.41%, surpassing Transolver (2.55%) and RIGNO-18 (2.78%).
To isolate the benefit of native higher-rank cochain ingestion, the authors perform a controlled study using an Anisotropic Darcy PDE with per-face random tensor orientations (Table 3a). By design, projecting the face-valued principal axis of diffusivity onto the vertices results in a vanishing population mean, making vertex projection lossy. TNO with native rank-2 face ingestion achieves a relative L1 error of 4.88%, whereas the vertex-projected TNO drops to 5.42%, and a vertex-based MPNN scores 9.97%.

Furthermore, synthetic-topology component ablations (Table 3b) highlight the critical importance of the harmonic-basis channel. Disabling the harmonic projection (Pkharm) in the complete TNO model degrades performance on the Darcy PDE, causing the relative error to spike from 4.87% to 11.64% (a performance drop of 6.77 percentage points). This confirms that explicitly representing topological harmonics is vital for solving equations with non-trivial curl.
Placing TNOs in the Operator Learning Landscape
TNOs represent a significant evolutionary step over point-centric, graph-based simulators such as MeshGraphNet or RIGNO. While existing geometric or manifold-based neural operators treat physical fields as node features and indirectly approximate differential relationships, TNOs treat cochains as first-class computational objects. They are conceptually distinct from prior topological deep learning architectures, such as HOGNN, which primarily operate as higher-order message-passing graph neural networks. TNOs are the first to define a mathematically rigorous, discretization-transferable neural operator that embeds the full Hodge Decomposition as a native architectural component. The paper provides theoretical proofs showing that standard Fourier Neural Operators and Graph Neural Operators are recovered as restricted, rank-0 special cases of the TNO formulation.
Unresolved Obstacles on the Topological Horizon
Despite their elegant mathematical formulation and strong empirical showing, TNOs face several practical limitations. The framework relies heavily on the availability of high-quality, pre-computed cell complexes and boundary matrices, which can introduce substantial preprocessing overhead for large, noisy, or unstructured industrial datasets. Furthermore, scaling TNOs to dynamic or adaptive meshes remains a significant challenge, as re-evaluating the topological incidence structure and Hodge stars at each timestep is computationally demanding. In the current hierarchical implementation, the commuting-diagram property (d∘R=R∘d) is not strictly enforced on the learned coarse complexes due to the extreme mathematical complexity of higher-rank transfers (k≥1), which introduces a soft optimization approximation. Finally, because TNOs lack a continuous, neural-field-style decoder, the predictions remain tied to the discrete geometry of the input grid, requiring downsampling or interpolation on massive raw meshes, such as those in the EmmiWing dataset.
The Verdict on Structure-Preserving ML
Topological Neural Operators successfully demonstrate that enforcing physical and geometric supports in neural architectures is not just theoretically satisfying, but also yields substantial empirical dividends. By separating topological routing from learned feature transformations, TNOs guarantee conservation laws by design and show remarkable accuracy, data efficiency, and generalization across complex, irregular meshes. This work sets a compelling precedent for structure-preserving scientific machine learning, illustrating how discrete differential geometry can serve as the backbone for next-generation, robust physical surrogate models.