
Towards a Neural Debugger for Python
Authors: Maximilian Beck, Jonas Gehring, Jannik Kossen, Gabriel Synnaeve
Affiliation: Meta FAIR CodeGen Team & Johannes Kepler University Linz
Paper: https://arxiv.org/abs/2603.09951
Code: N/A
Model: N/A
TL;DR
WHAT was done? The authors formulate interactive debugging as a Markov Decision Process, training language models to predict intermediate program states conditioned on standard debugger actions (e.g., step_into, breakpoint). They construct a data pipeline that transforms Python execution traces into formatted trajectory trees, enabling both forward execution and inverse state inference.
WHY it matters? Current execution-aware models consume linear, non-interactive traces, which fails to reflect how developers actually isolate faults. By equipping a model with interactive control over simulated execution, this work provides a foundational “world model” for agentic coding systems, allowing them to step through code, reverse-engineer inputs, and iteratively self-correct without needing a live runtime environment.

Details
The Sequential Execution Bottleneck
The intersection of language modeling and software engineering has historically relied on static code analysis. Recent advancements have sought to ground models in dynamic behavior by training them on execution traces—essentially turning them into neural interpreters. Models like the Code World Model (CWM) reliably predict line-by-line state changes. However, this paradigm introduces a strict sequential bottleneck. Real-world debugging is rarely linear; engineers set breakpoints to bypass irrelevant logic and step meticulously through critical segments. Existing neural interpreters lack this interactive control flow, forcing agents to process entire trace histories sequentially. This paper addresses this delta by introducing “neural debuggers,” which learn to map specific control actions to nonlinear state transitions, bypassing the need to model every intermediate instruction.

Debugging as a Markov Decision Process
To instill interactive control, the authors formulate the debugging environment from first principles as a Markov Decision Process defined by the tuple (S,A,P,s0). Here, the state space S is defined as a snapshot of the program at a specific point in time, encapsulating the runtime event type, local variables (or function arguments), and the current source line. The action space A mirrors traditional debuggers: step_into, step_over, step_return, breakpoint, and continue. The transition dynamics P:S×A→S represent the deterministic (or, in the case of inverse execution, probabilistic) shift to the next valid program state. By omitting a rigid reward function, the formulation isolates the core objective: highly accurate state prediction conditioned on user-directed or agent-directed traversal paths.
Traversing the Execution Tree
The mechanism relies on converting flat execution traces—captured via Python’s sys.settrace—into hierarchical data structures. As illustrated in Figure 1 and Figure 3, the system constructs a State Tree where the depth of a node corresponds directly to the depth of the call stack.
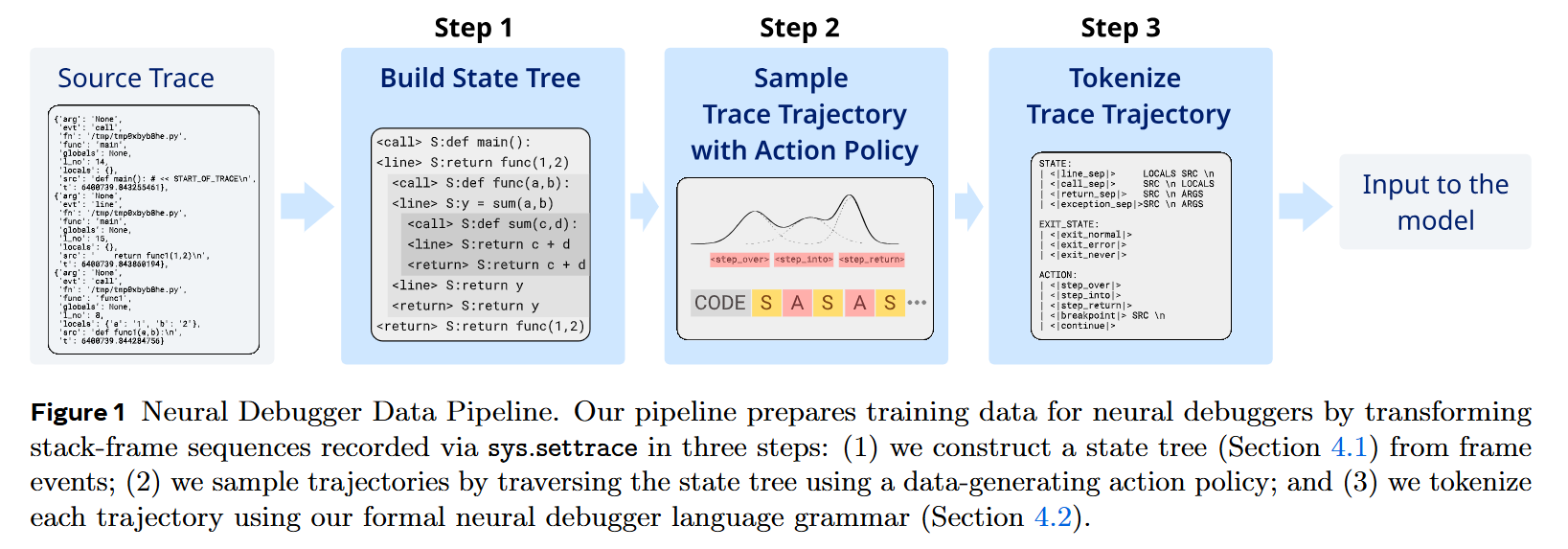
Consider a single concrete input: a program evaluating y = sum(a, b). When the simulated debugger pauses at this line, the current state contains the source code string and the local variables a and b. If the network receives the step_into action, the transition dynamics dictate moving one level deeper into the State Tree; the model must predict the next state as the first internal line of the sum function, updating the context to reflect the local namespace of that function. Conversely, if the network receives the step_over action, it bypasses the child nodes entirely, traversing laterally to the next sibling node in the tree. The model outputs the state at the subsequent line of the caller function, with y successfully added to the locals dictionary. This structured traversal allows the network to natively skip arbitrary amounts of execution trace data without losing state coherency.

Model Scale and Optimization Strategy
To prove the viability of this mechanism, the authors experiment with two distinct optimization regimens using a formal Domain-Specific Language (DSL) that tokenizes states and actions with specialized separators like <|frame_sep|> and <|action_sep|>.

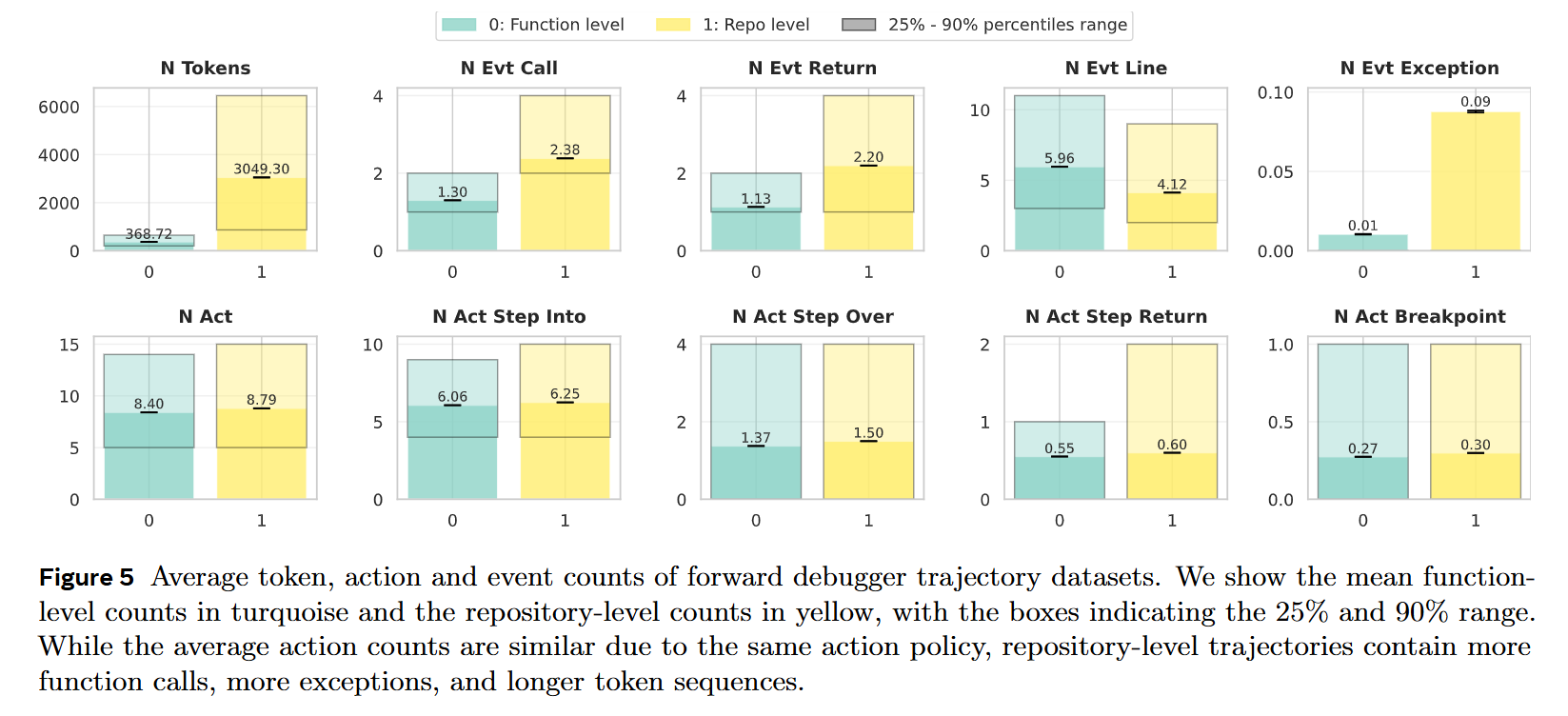
First, they finetune a 32-billion parameter dense Transformer originally mid-trained on linear traces. This model is updated for 50 billion tokens using a constant learning rate following a linear warmup. Alternatively, they pre-train 1.8-billion parameter models based on the LLaMA-2 architecture from scratch, scaling up to 150 billion tokens using an AdamW optimizer and a cosine decay schedule. To handle the variable state, arbitrary Python objects within the LOCALS dictionaries are serialized into JSON via their __repr__() methods. A stochastic data-generating policy ensures the models see a diverse mix of short steps and massive jumps, preventing the network from merely memorizing linear execution.
Analyzing the Inference Horizon
The empirical validation demonstrates that language models are highly capable of acting as simulated execution runtimes. The finetuned 32B model achieves over 90% exact-match accuracy for predicting the immediate next state following step_into or step_over actions. When evaluated on the CruxEval output prediction benchmark, the 32B model yields a pass@1 score of 83.2% when utilizing the breakpoint action—a massive improvement over baseline sequential predictors.
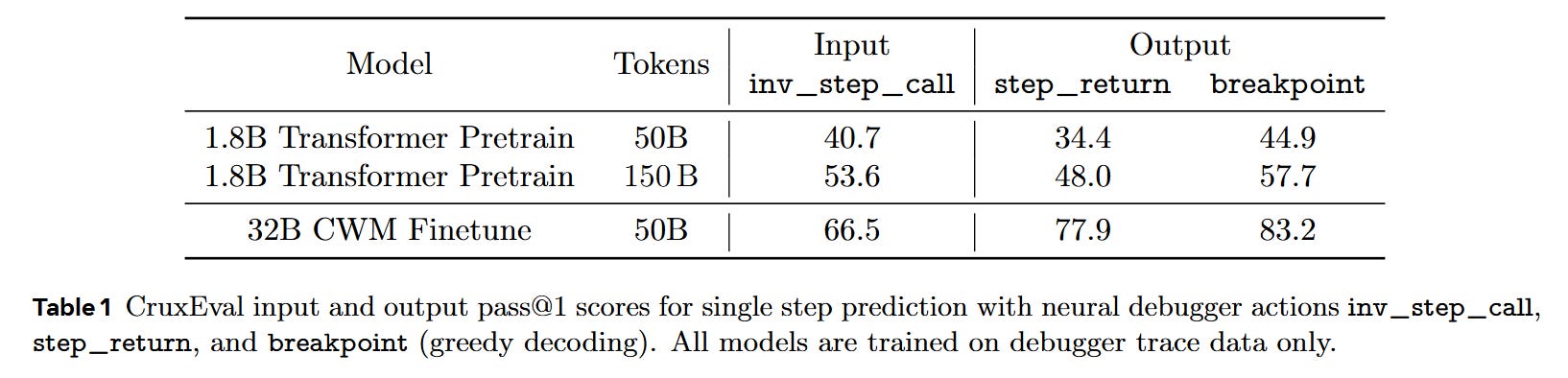
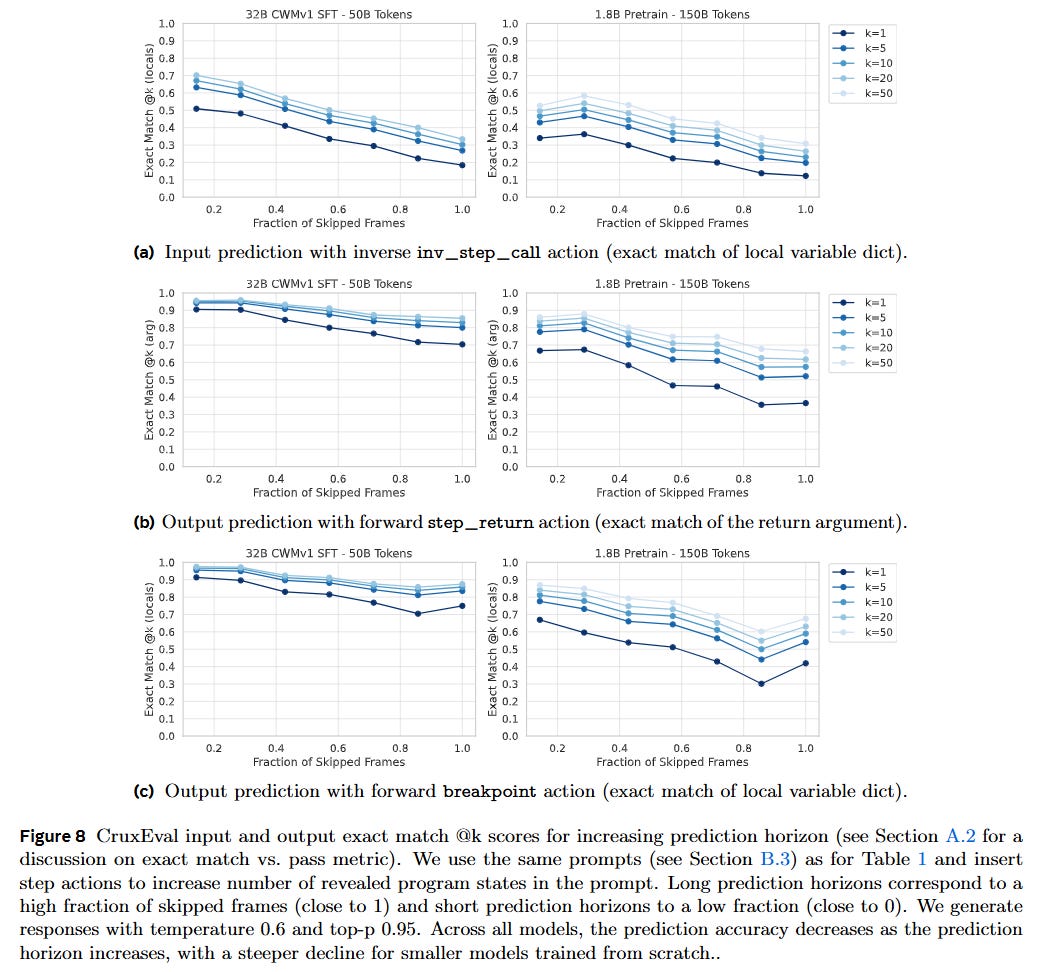
However, mechanistic probing of the results reveals a critical vulnerability. As documented in Figure 8, prediction accuracy inversely correlates with the “prediction horizon.” When a step_return or breakpoint action forces the model to skip a vast number of intermediate frames, performance drops. Component-level analysis shows that the model rarely fails to predict the correct control flow (the next source line); instead, the primary source of error lies in tracking the exact state of the local variables across long, unobserved contexts.
Tracing the Lineage of Learned Execution
This architecture builds heavily on previous attempts to augment LLMs with execution state. Early works like Scratchpads for Intermediate Computation demonstrated that forcing models to emit intermediate variable states vastly improves algorithmic reasoning. The authors adapt the formal structures established by the Code World Model, which serialized full traces but lacked semantic control operators. By shifting the objective from passive sequence modeling to active environment simulation, this paper aligns more closely with reinforcement learning interfaces, providing a missing semantic layer between static code parsing and dynamic testing.
Ambiguity in Time Reversal
While forward execution is generally deterministic, the paper ambitiously tackles inverse execution—inferring predecessor states or inputs given a final state. The primary limitation here is mathematical ambiguity. Because execution is a many-to-one mapping (e.g., if a state shows c=5 after evaluating c=a+b, the exact values of a and b form an underdetermined system with infinitely many solutions), exact-match accuracy metrics artificially depress the model’s perceived performance. Traditional debuggers cannot reverse state without a prior recorded forward pass, whereas neural debuggers attempt to sample from a learned conditional distribution of plausible pasts. The current text serialization format struggles to natively represent this ambiguity, pointing to a need for distributional evaluation metrics in future iterations.

The Horizon of Agentic Tool Use
Neural debuggers represent a strategic shift in how we build coding agents. Instead of forcing an LLM to rely entirely on an external, sandbox execution environment—which is slow, compute-intensive, and sometimes unavailable for incomplete snippets—we can embed a rapid, probabilistic world model directly into the reasoning loop. An agent equipped with a neural debugger can test hypotheses, step backward from an error trace to hallucinate the faulty input, and self-correct prior to generating final source code. This tightly coupled feedback mechanism is a crucial stepping stone toward fully autonomous software engineering systems.