
Towards General Agentic Intelligence via Environment Scaling
Authors: Runnan Fang, Shihao Cai, Baixuan Li, Jialong Wu, Guangyu Li, Wenbiao Yin, Xinyu Wang, Xiaobin Wang, Liangcai Su, Zhen Zhang, Shibin Wu, Zhengwei Tao, Yong Jiang, Pengjun Xie, Fei Huang, Jingren Zhou
Paper: https://arxiv.org/abs/2509.13311
Code: https://github.com/Alibaba-NLP/DeepResearch
TL;DR
WHAT was done? The paper introduces a principled framework for developing advanced AI agents by tackling the core problem of data scarcity. The authors developed a pipeline that automatically constructs diverse, fully simulated, and verifiable environments where agents can interact with tools. This process involves modeling tool dependencies as a graph, programmatically materializing tools as executable code that operates on database-like states, and generating high-fidelity interaction data. This data is then used to train a family of models, named AgentScaler, through a novel two-phase fine-tuning strategy that first builds fundamental tool-use skills and then specializes them for specific domains.
WHY it matters? This work addresses a fundamental bottleneck in agentic AI: the lack of scalable and realistic training environments. By automating the creation of verifiable interaction data, it provides a robust and cost-effective alternative to manual data collection or less reliable simulation methods. The results are significant: the AgentScaler models achieve state-of-the-art performance among open-source competitors, with smaller models (e.g., 4B parameters) performing on par with much larger 30B models. This demonstrates that advanced agentic capabilities can be efficiently trained, making powerful, reliable AI agents more practical and accessible for real-world deployment, especially in resource-constrained scenarios.

Details
Introduction: The Experience Bottleneck in Agentic AI
The promise of Large Language Models (LLMs) evolving into capable agents that can interact with the real world hinges on their ability to use tools and APIs effectively—a capability known as function calling. However, progress has been fundamentally constrained by the scarcity of high-quality “agentic data,” the interaction trajectories from which agents learn. Existing methods for generating this data often fall short: they either lack realism, require significant manual intervention, or fail to scale.
Think of it like training a pilot. You can give them books and manuals (the equivalent of static datasets), but to become truly skilled, they need countless hours in a high-fidelity flight simulator that can replicate a vast range of scenarios and emergencies. This paper essentially builds the ultimate, auto-scaling ‘flight simulator’ for AI agents, moving the field from an era of ‘studying data’ to an ‘era of experience.’ It presents a compelling solution that argues the key to unlocking general agentic intelligence lies not just in model architecture, but in systematically scaling the diversity and complexity of the environments in which agents are trained.
Methodology: A Principled Pipeline for Environment and Agent Scaling
The core of the proposed method is a two-part pipeline designed to create a rich source of agentic experience and then use it effectively for training.
1. Fully Simulated Environment Construction
The authors’ approach is grounded in a simple yet powerful design principle: any function call can be abstracted as a read-write operation on an underlying database that represents the environment’s state. This is the paper’s key innovation for data quality. Unlike LLM-simulated environments which can be prone to hallucination, this database-grounded approach ensures that the outcome of any tool use is deterministic and verifiable. If an agent’s action is supposed to change a user’s flight reservation, you can check the database state to see if it actually did.
The process, illustrated in the paper (Figure 1), involves several key steps:
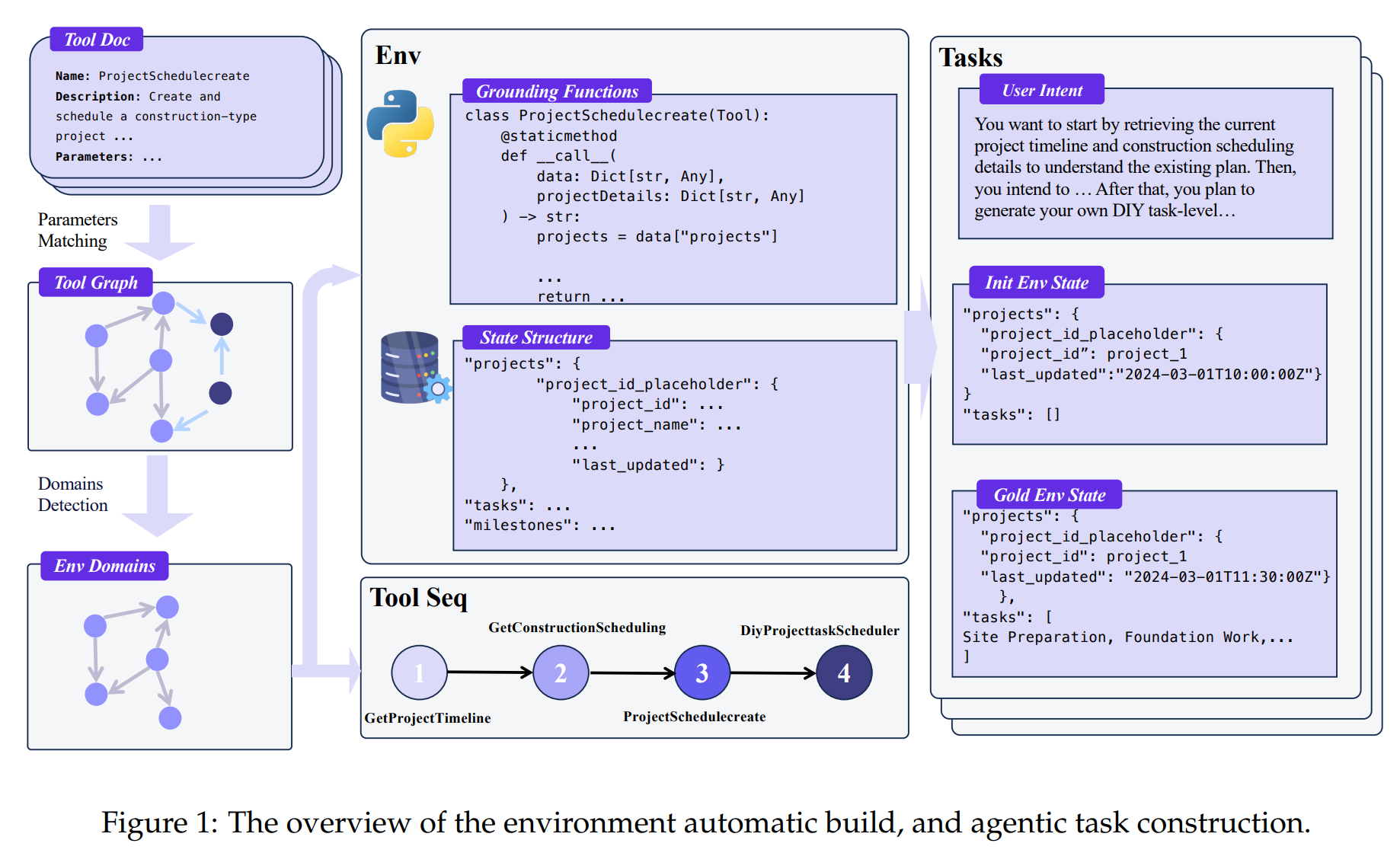
Scenario Collection and Graph Modeling: Starting with a massive pool of over 30,000 real-world APIs, the system builds a “tool dependency graph.” Tools are nodes, and an edge is created between two tools if their parameters are semantically similar, indicating potential compositional compatibility. This is formalized as:
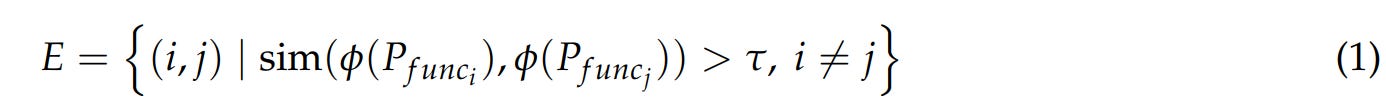
Domain Partitioning: Louvain community detection is then applied to this graph to automatically partition the vast tool space into coherent domains (e.g., “retail,” “airline”).
Programmatic Materialization: For each domain, the framework automatically generates a specific database schema. Crucially, each tool is then materialized as executable Python code that can perform direct, verifiable read-write operations on this database.
Agentic Task Construction: The system generates agentic tasks by sampling logical sequences of tool calls from the domain’s tool graph. These sequences are executed against the database, ensuring verifiability at two levels: consistency of the final database state and exact matching of the tool sequence.
2. Agent Experience Learning
Once the environments are built, the next stage is to collect agent experiences and use them for training (Figure 2).
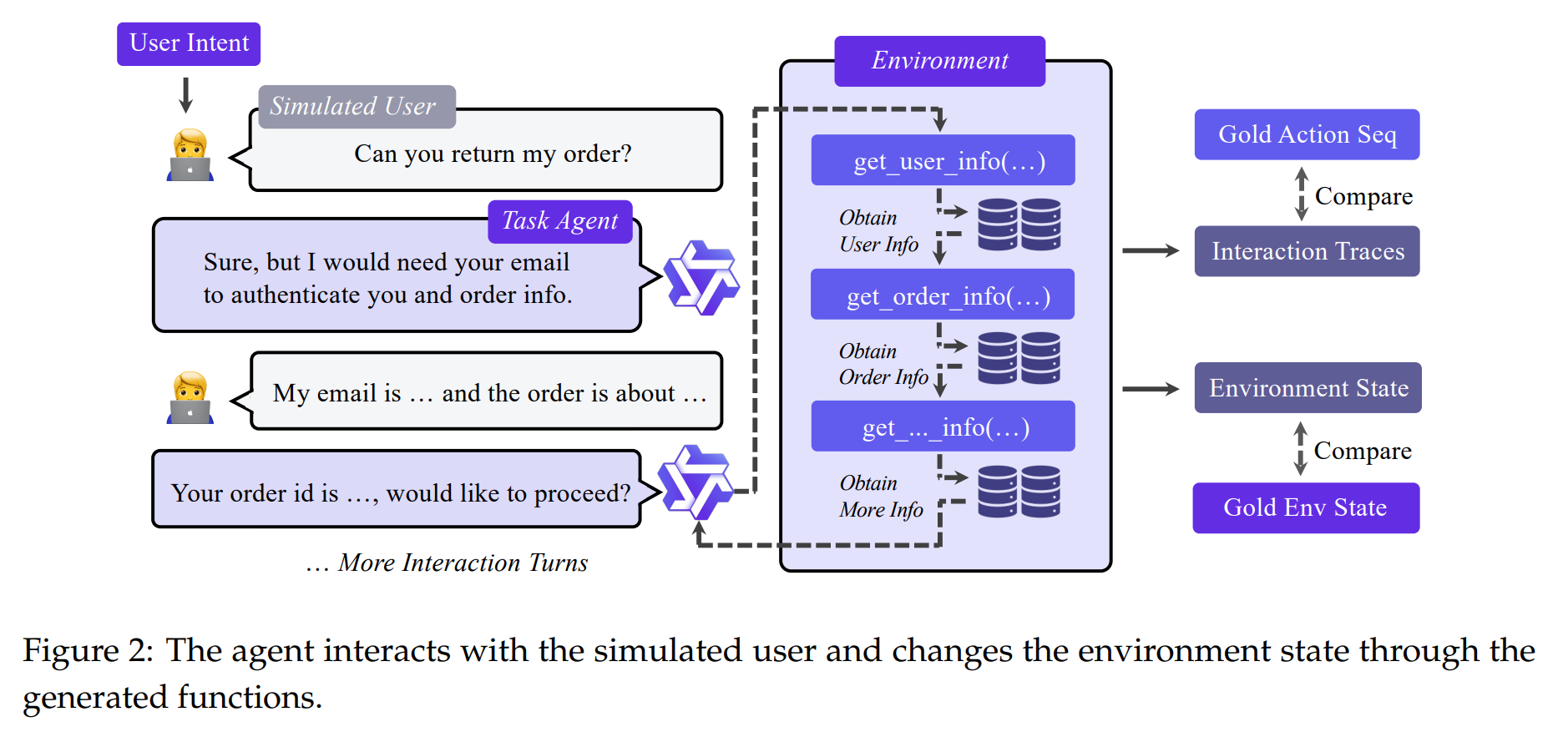
Simulated Interplay and Filtering: An agent interacts with a simulated user within the environment. The resulting trajectories are subjected to a rigorous three-stage filtering process:
Validity Control: Removes malformed or repetitive interactions.
Environment State Alignment: Retains only trajectories where the final database state matches the expected “gold” state.
Function Calling Exact Match: A stricter filter that ensures the sequence of tools and arguments perfectly matches the intended plan. Interestingly, trajectories with intermediate tool call errors are kept if the final goal is met, helping to improve model robustness.
Two-Phase Agent Fine-Tuning: The filtered data is used in a two-phase learning strategy. This is strategically clever: the initial broad training prevents overfitting, giving the agent a general understanding of tool use. The subsequent specialization then hones these skills for real-world contexts, achieving both generalization and expertise.
The training objective is carefully designed to focus learning on the agent’s outputs. The loss function masks out human instructions and tool responses, ensuring gradients only propagate through the agent’s generated tool calls and natural language responses. This is formally defined as:
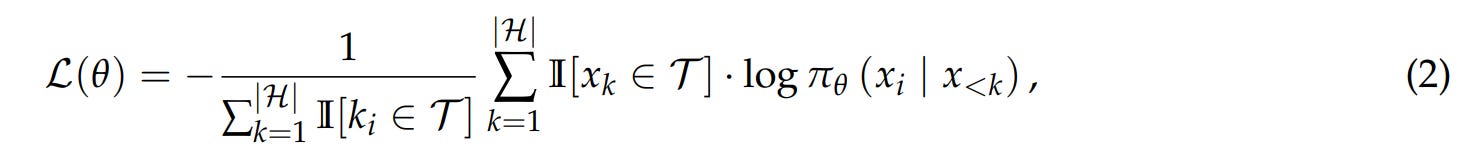
where I[·] is the indicator function, and T is the set of tokens belonging to the agent’s tool calls and assistant responses, ensuring the model only learns from its own generated actions.
Experimental Results: Efficiency Meets State-of-the-Art Performance
The authors evaluated their AgentScaler models on three established benchmarks: τ-bench (https://arxiv.org/abs/2406.12045), τ²-Bench (https://arxiv.org/abs/2506.07982), and ACEBench (https://arxiv.org/abs/2501.12851). The results are compelling.
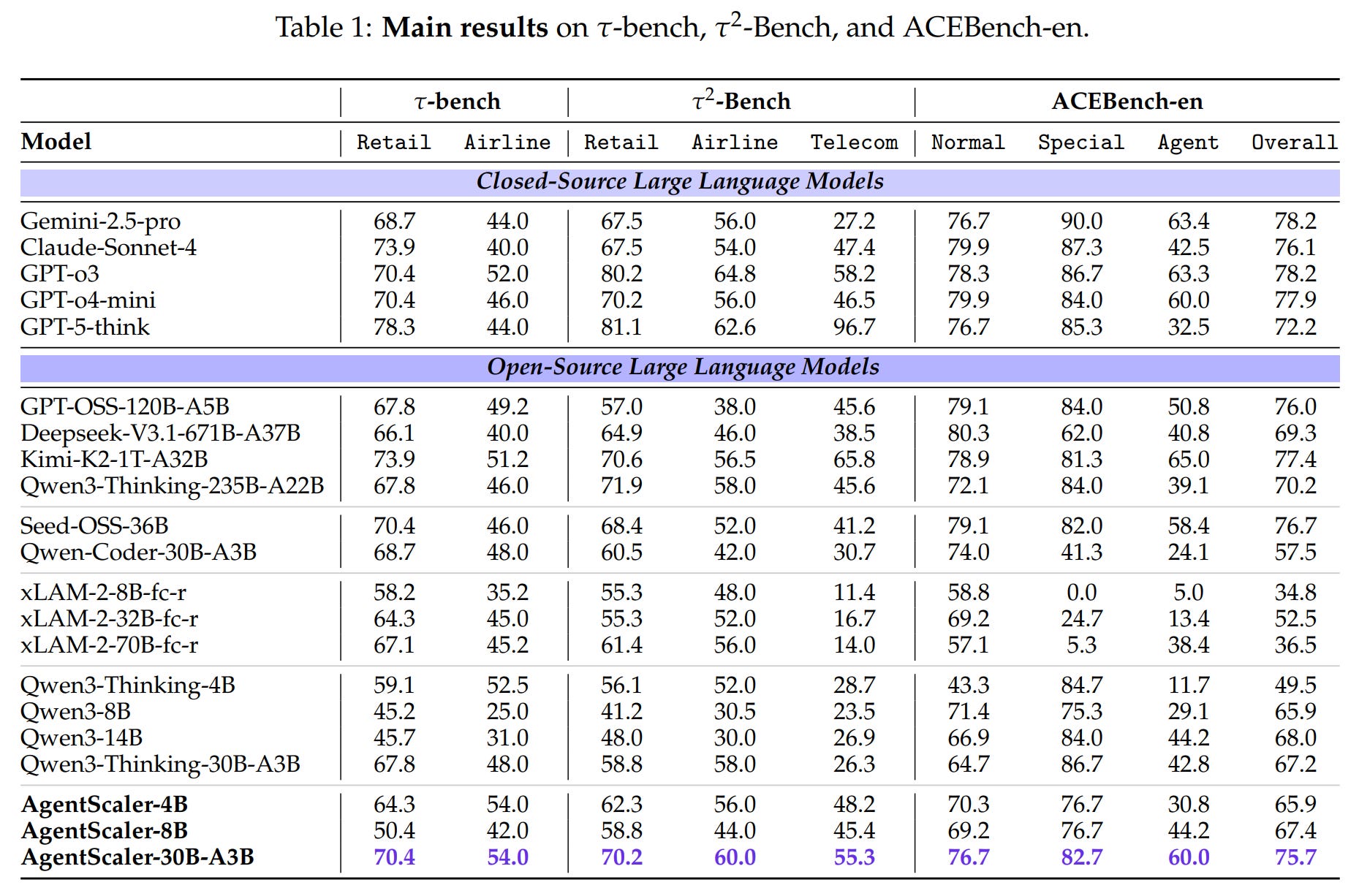
State-of-the-Art Performance: As shown in the main results (Table 1), the AgentScaler models set a new state-of-the-art across these benchmarks for open-source models under 1 trillion parameters. The
AgentScaler-30B-A3Bmodel delivers results comparable to trillion-parameter open-source models and approaches the performance of leading closed-source systems.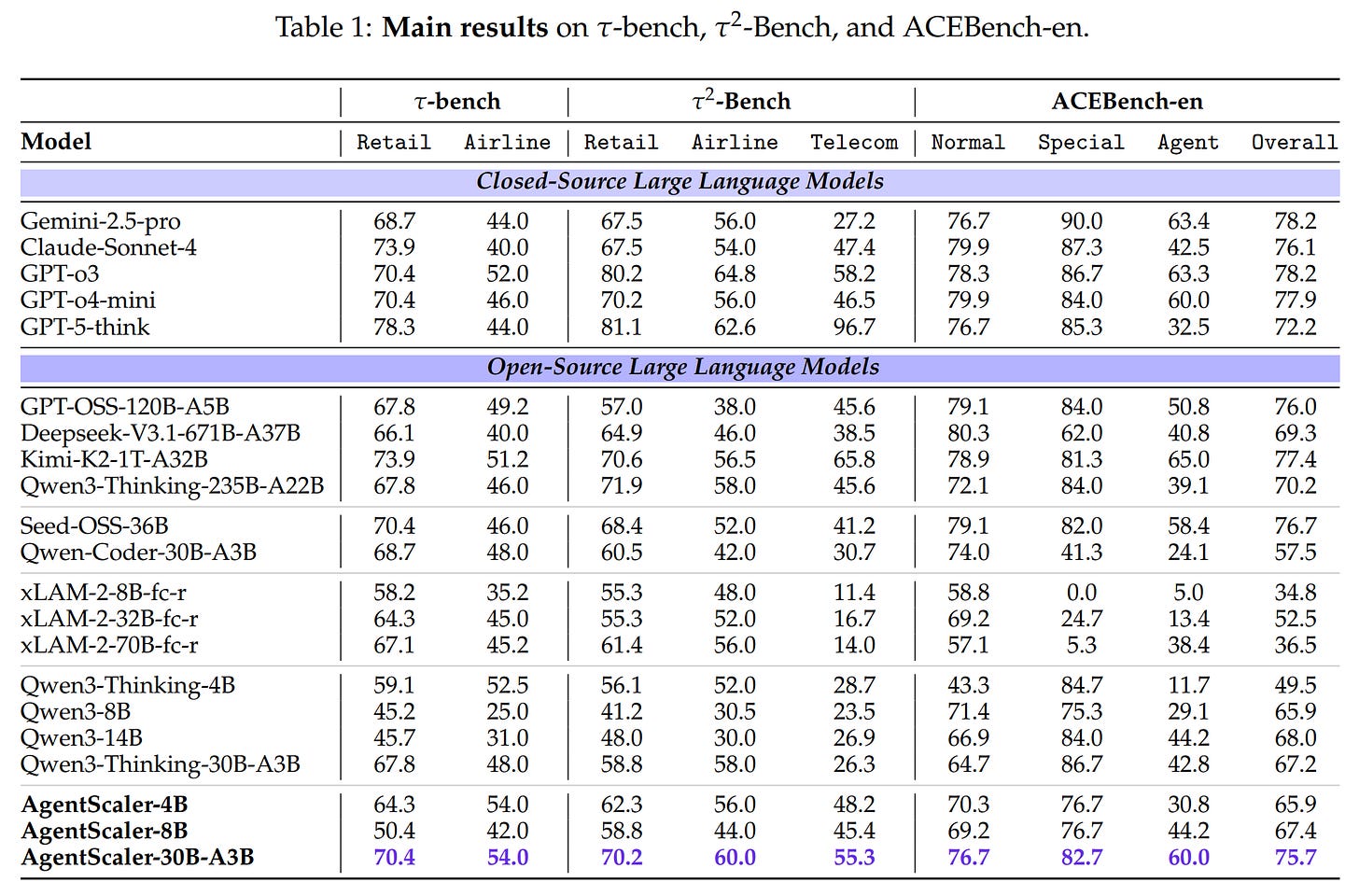
Remarkable Efficiency: Perhaps the most significant finding is the performance of the smaller models. The
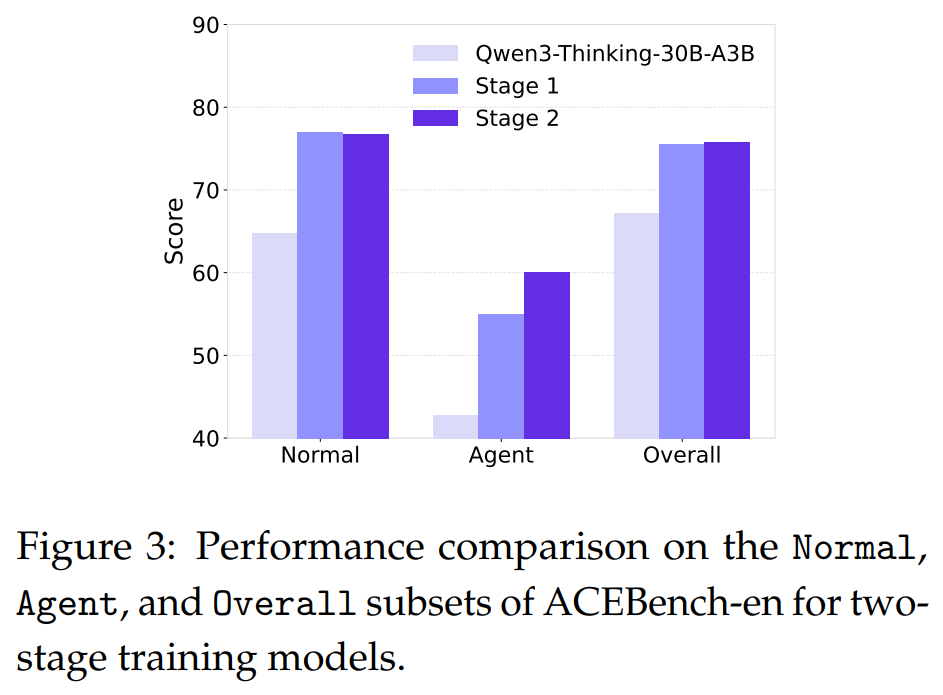
AgentScaler-4Bmodel achieves performance on par with 30B-parameter baselines, demonstrating that the proposed training framework can instill powerful agentic capabilities in compact models.Validation of Two-Phase Training: An ablation study (Figure 3) confirms the effectiveness of the two-phase learning strategy. Both stages provide substantial gains over the base model, with specialization in Stage 2 further improving performance.
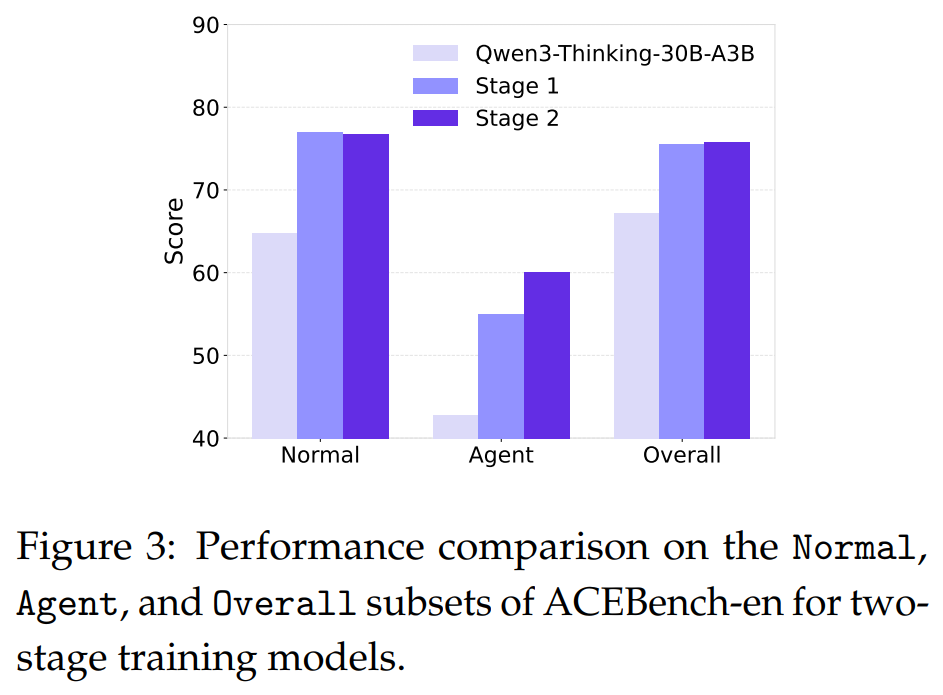
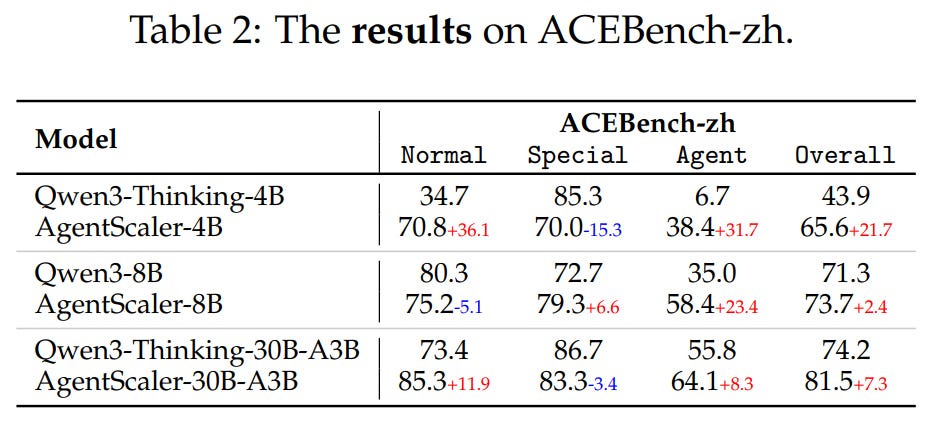
Strong Generalization and Stability: The models show strong generalization to an out-of-distribution benchmark (Table 2)
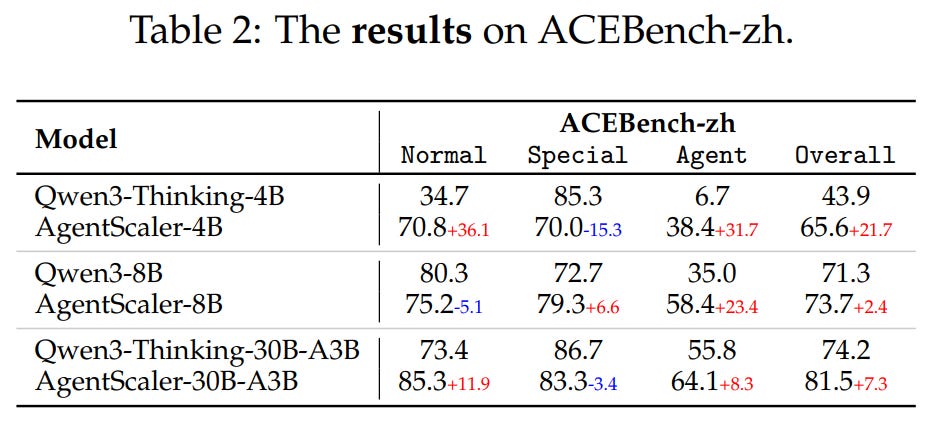
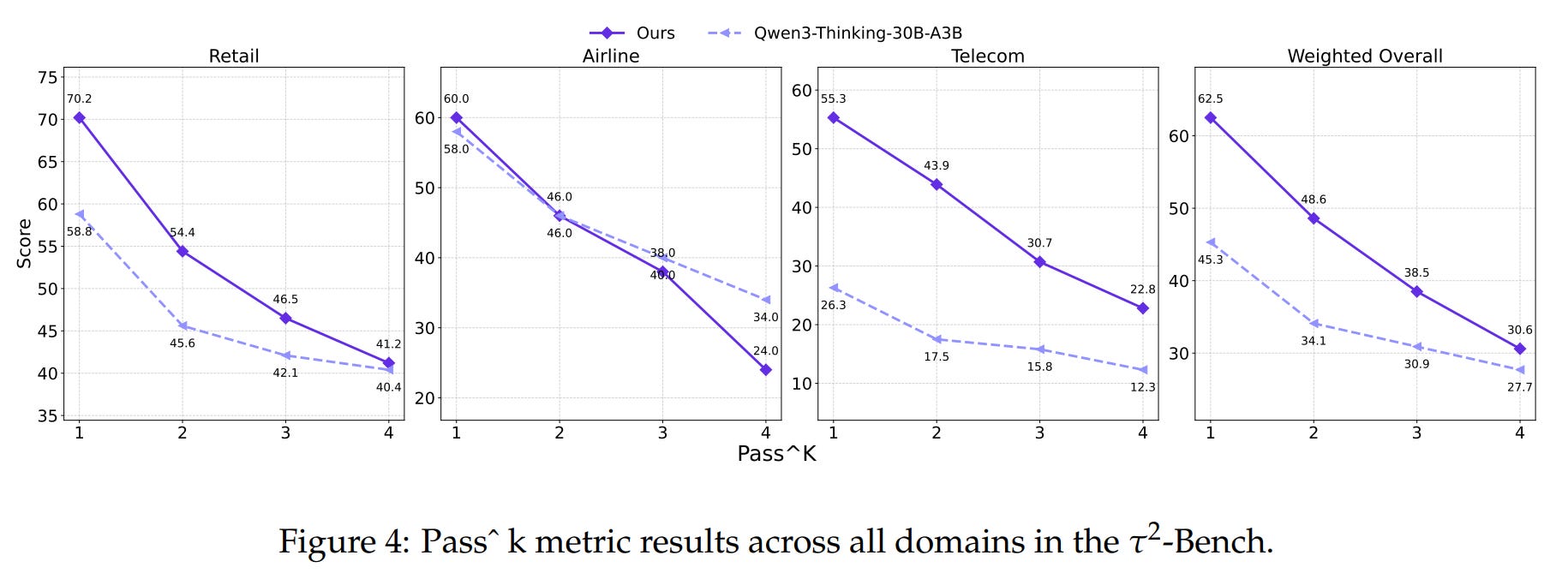
and demonstrate superior stability across all
pass@ksettings (Figure 4), which measures correctness over multiple independent trials.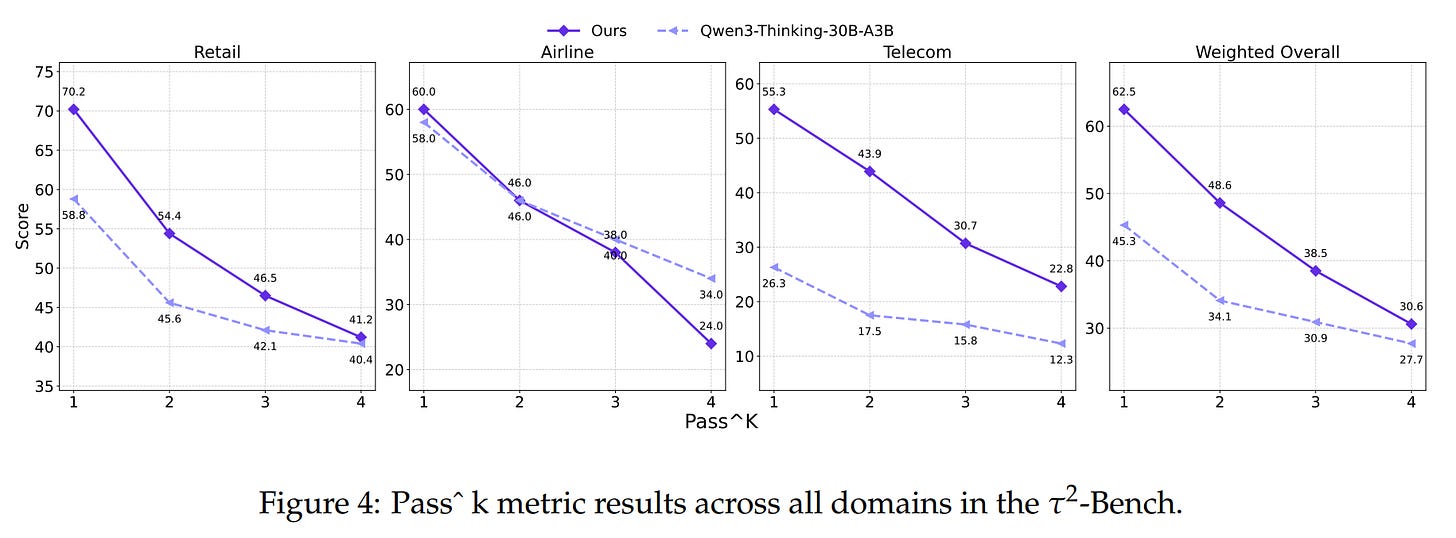
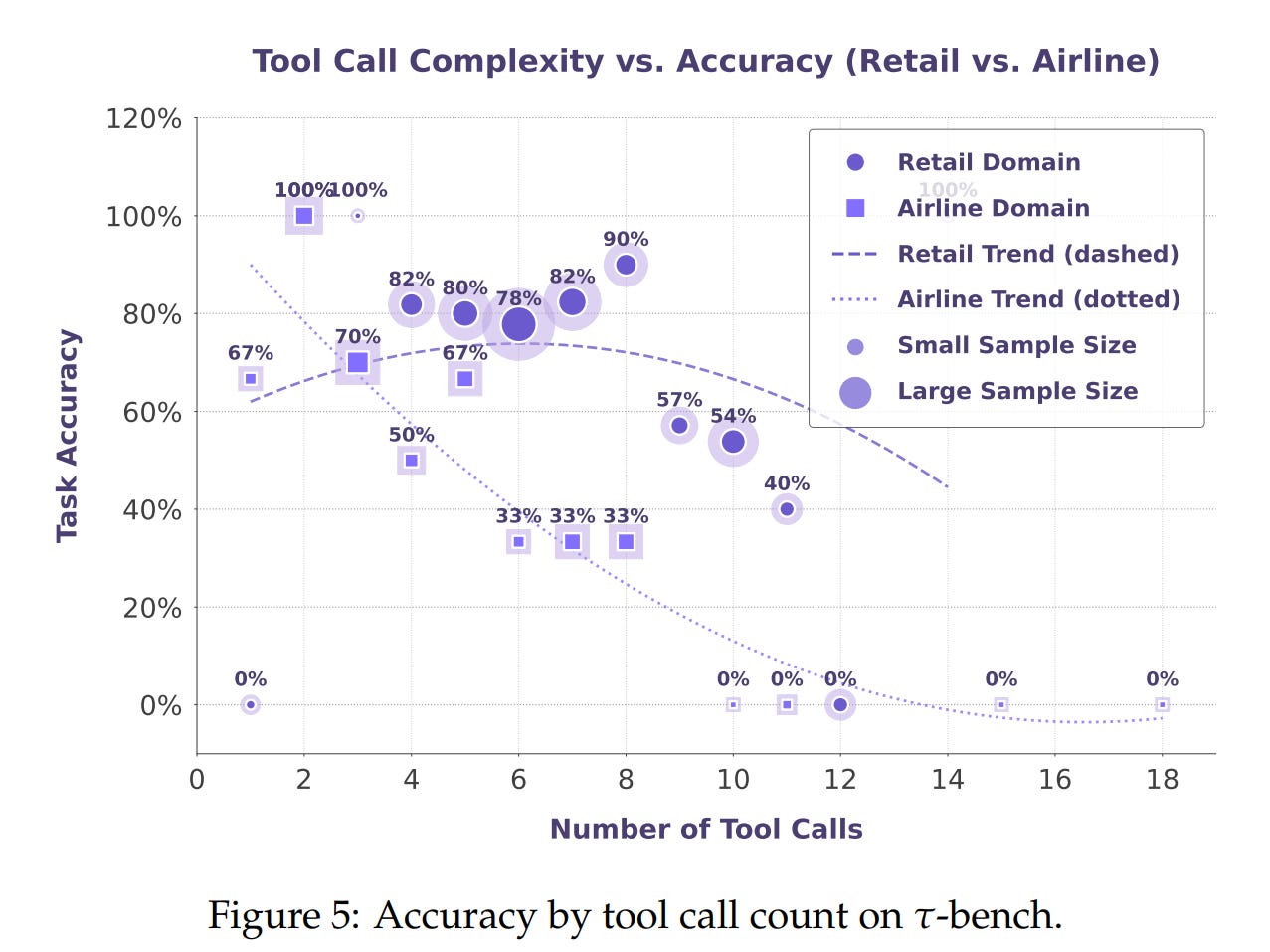
Despite these strong results, the authors transparently highlight that long-horizon tool calling—executing long chains of sequential tool calls—remains a fundamental challenge, as performance degrades with an increasing number of tools (Figure 5).
Discussion and Future Directions
This work makes a significant contribution by providing a scalable and verifiable solution to the agent data bottleneck. The experimental findings have profound implications for the field:
Democratizing Agentic AI: By showing that smaller models can be trained to be highly capable agents, this research paves the way for deploying powerful AI in resource-constrained environments. Imagine a small, efficient customer service agent running on a company’s local server to maintain data privacy, or a smart assistant on your phone that can reliably book a multi-step travel itinerary without needing to connect to a massive cloud-based model for every single step. This work makes that future far more attainable.
A Blueprint for Agent Development: The systematic pipeline for environment construction and agent training serves as a robust blueprint for future research. The verifiable nature of the simulated environments makes them an ideal testbed for more advanced training paradigms.
Future Work in Reinforcement Learning: The authors explicitly note that their simulated environments are inherently well-suited for Reinforcement Learning (RL). Integrating RL on top of this framework is a promising future direction to potentially overcome the limitations of supervised learning and further enhance agentic reasoning and planning.
Limitations
The authors acknowledge two primary limitations. First, the current work relies on supervised fine-tuning, leaving the integration of reinforcement learning for future exploration. Second, the methodology has so far only been validated on models up to the 30B scale, with its effects on trillion-parameter models remaining an open question.
Conclusion
“Towards General Agentic Intelligence via Environment Scaling” offers a valuable and practical contribution to the field of agentic AI. By shifting the focus from simply scaling model size to systematically scaling the training environment, the paper provides a powerful and efficient methodology for developing robust, generalizable, and highly capable language agents. The strong empirical results, particularly the performance of the compact models, suggest that this approach is a significant step towards making advanced agentic intelligence more accessible and deployable in the real world.