
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
Authors: Amir Zandieh, Majid Daliri, Majid Hadian, Vahab Mirrokni
Paper: https://arxiv.org/abs/2504.19874v1
Blog: https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
Code: N/A + Unofficial
It’s never too late to review an important work!
TL;DR
WHAT was done? Researchers from Google and NYU introduced TurboQuant, a two-stage, data-oblivious vector quantization algorithm. It achieves near-optimal distortion rates by randomly rotating high-dimensional vectors to induce a stable Beta distribution, applying optimal scalar quantization, and utilizing a 1-bit sketch on the residual to ensure unbiased inner product estimation.
WHY it matters? For memory-bound AI infrastructure—specifically Large Language Model (LLM) KV caches and massive-scale vector databases—offline preprocessing and data-dependent codebook training are paralyzing bottlenecks. TurboQuant provides a highly vectorized, zero-overhead indexing alternative that matches information-theoretic limits, allowing for aggressive compression without sacrificing long-context retrieval or retrieval-augmented generation (RAG) performance.

Details
The Latency and Adaptability Bottleneck
Scaling modern AI capabilities frequently hits a hard memory wall, primarily driven by the communication bottlenecks between High Bandwidth Memory (HBM) and SRAM on accelerators. In transformer architectures, serving large contexts requires maintaining massive key/value (KV) caches. Concurrently, dense retrieval systems demand high-throughput nearest neighbor (NN) searches across billions of embeddings. The conventional approach to compressing these dense vectors relies on algorithms like Product Quantization (PQ), an inherently offline, data-dependent process that requires expensive clustering (e.g., k-means) to construct codebooks.
While recent token-level compression techniques such as SnapKV and PyramidKV attempt to reduce memory by evicting redundant tokens, they inherently discard information. Alternative quantization methods like KIVI lack formal theoretical guarantees, and grid-based techniques like RabitQ struggle with hardware compatibility due to a lack of vectorization. The core challenge in the field has been designing an online (data-oblivious) quantization scheme that applies instantly, utilizes hardware-friendly operations, and mathematically guarantees minimal distortion.
Geometric First Principles: The Rotation Matrix Substrate
To design an online quantizer without prior knowledge of the data distribution, one must force the data into a predictable statistical shape. The theoretical foundation of this paper rests on the concentration of measure phenomenon in high-dimensional spaces. Let x∈Rd be a high-dimensional input vector with unit norm, and let Q:Rd→{0,1}B denote a quantization map that compresses the vector into B bits. The average bit-width per coordinate is defined as b=B/d. The corresponding dequantization map, which attempts to reconstruct the vector, is Q−1:{0,1}B→Rd.
The authors demonstrate that by multiplying the input vector x by a random rotation matrix Π∈Rd×d, the resulting vector Πx is uniformly distributed on the unit hypersphere. More importantly, in high dimensions, every distinct coordinate of Πx converges to a specific, nearly independent Beta distribution, denoted by a probability density function fX(x). This geometric trick is profound: by randomizing the basis, the algorithm strips away arbitrary data correlations. Because the coordinates are now nearly independent and predictably distributed, the formidable challenge of multidimensional vector quantization collapses into a dramatically simpler problem of one-dimensional scalar quantization.
The Quantization Mechanism Walkthrough
With the statistical distribution of the coordinates known, the system optimizes for Mean Squared Error (MSE), defined as the expected distance between the original and reconstructed vectors:
To minimize this distortion, the algorithm computes optimal codebook centroids offline for the continuous Beta distribution fX(x) using the Max-Lloyd algorithm.
The mathematical objective is to find the sorted centroids ci that minimize the continuous k-means cost function for a given bit-width b:
Because this calculation depends solely on the mathematically fixed Beta distribution and not on a specific user dataset, the optimal codebook is computed exactly once and hardcoded into the system.

When a new activation vector x flows through the system, the primary TurboQuant_mse algorithm executes a highly vectorized sequence. First, it computes the rotated vector y=Πx. Second, for each coordinate yj in the rotated vector, it performs a simple argmin search against the precomputed 1D centroids ci, storing only the b-bit integer index of the nearest centroid. To reconstruct the vector, the system retrieves the coordinates from the codebook and applies the inverse rotation Π⊤.
Correcting the Inner Product Bias
While TurboQuant_mse is provably optimal for minimizing geometric distance, modern AI pipelines (like attention mechanisms and vector searches) rely heavily on inner products. The inner product distortion is defined as
As illustrated in Figure 1, purely MSE-optimized quantizers introduce a significant statistical bias when estimating inner products, skewing the expected similarity values.
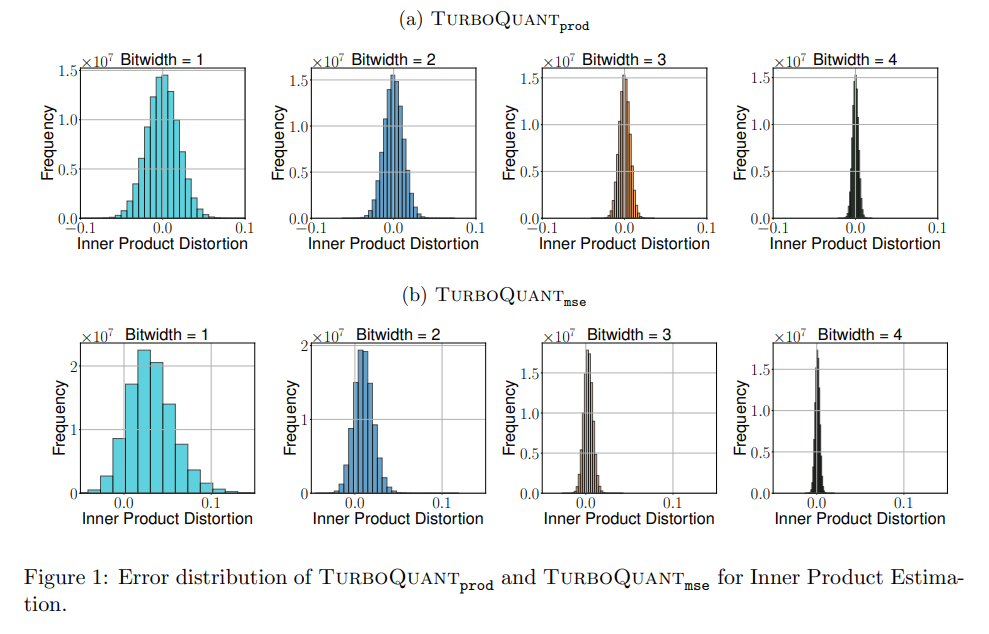
Figure 2 further highlights that the variance of the inner-product error in standard MSE quantizers scales unfavorably with the magnitude of the actual inner product.
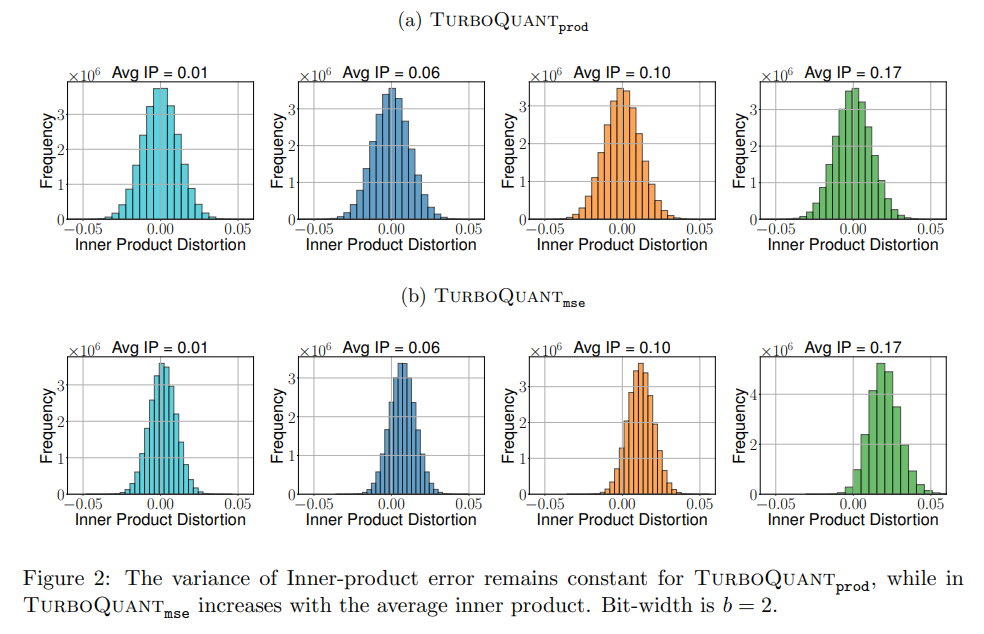
To eliminate this bias, the authors introduce a two-stage composite algorithm called TurboQuant_prod. First, the input vector is quantized using the MSE method, but with an intentionally restricted budget of b−1 bits. The system then calculates the residual vector r, which is the exact mathematical difference between the original vector x and the initial b−1 bit reconstruction. Finally, the algorithm applies the Quantized Johnson-Lindenstrauss (QJL) transform to this residual. The QJL transform generates a 1-bit sketch using a random projection matrix S∈Rd×d and an entry-wise sign function. By adding this unbiased 1-bit sketch of the residual back into the primary estimate, the system mathematically guarantees an unbiased expectation for the inner product without exceeding the total bit-width budget b.

Hardware Execution and Scale
The design choices of TurboQuant yield massive engineering dividends on modern hardware, specifically evaluated on an NVIDIA A100 GPU. Because the algorithm requires no dataset-specific clustering passes, it practically eliminates preprocessing overhead. As shown in Table 2, for a dataset of 1536-dimensional embeddings, standard Product Quantization requires over 239 seconds to build its index. In stark contrast, TurboQuant indexes the same dataset in just 0.0013 seconds—a reduction to virtually zero overhead.
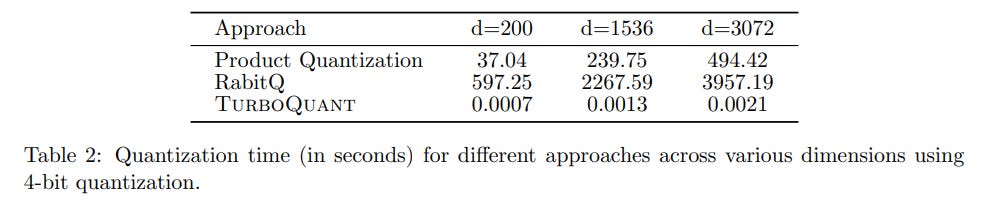
The algorithm also easily handles vectors that do not naturally reside on the unit hypersphere. The system simply computes the L2 norm of the original vector, stores it as a separate floating-point scalar, and uses it to rescale the vector post-dequantization. Furthermore, compared to algorithms like RabitQ that rely on sequential grid searches and suffer from poor GPU utilization, TurboQuant’s operations are purely matrix multiplications and simple register lookups, unlocking massive parallel throughput.
Empirical Validation in Serving Constraints
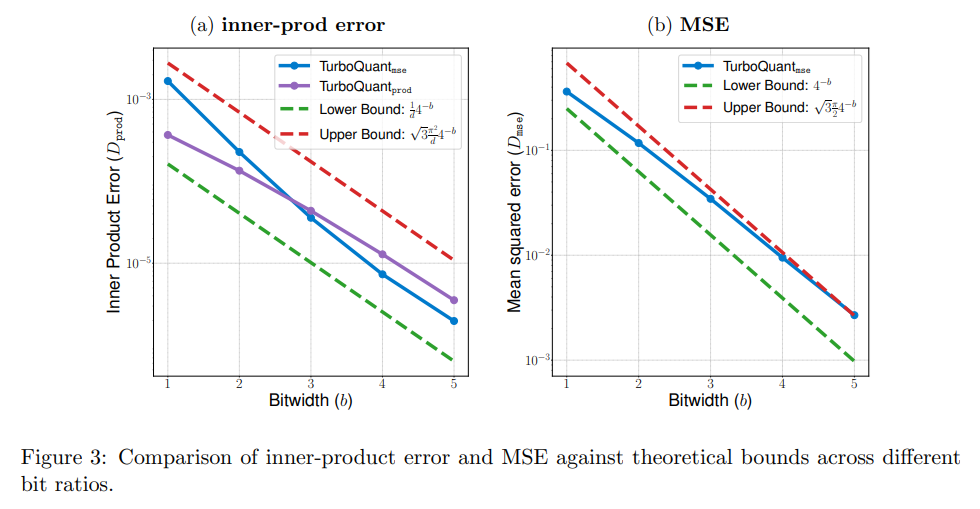
The theoretical rigors of the algorithm align seamlessly with its empirical execution, as evidenced in Figure 3, where the observed inner-product error and MSE tightly track the mathematical upper and lower bounds.
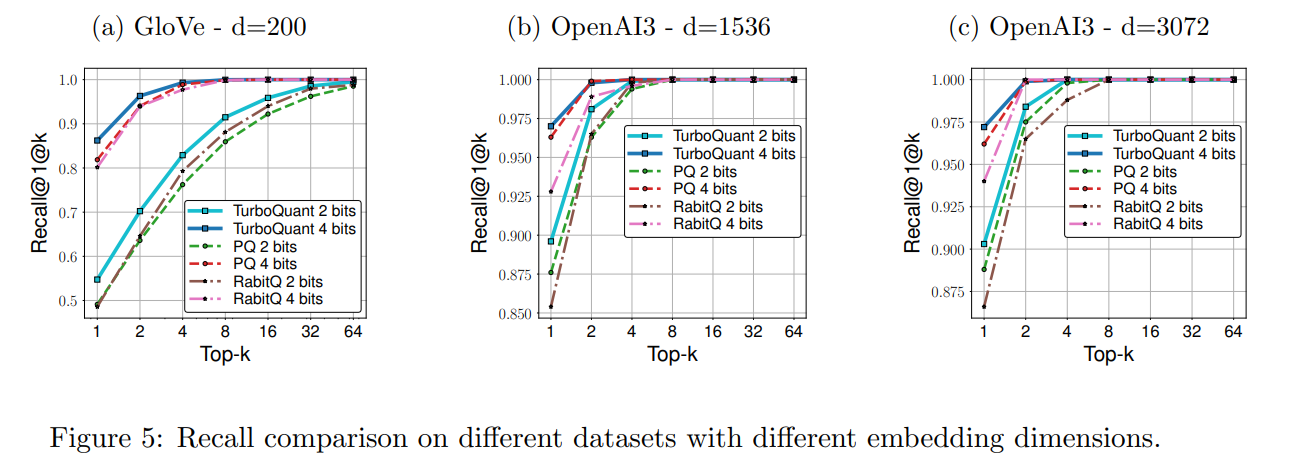
Beyond isolated metrics, the algorithm proves its resilience in downstream generative tasks. On the rigorous LongBench-V1 benchmark, utilizing the Llama-3.1-8B-Instruct model, TurboQuant paired with an outlier-aware mixed-precision strategy achieves an average score of 50.06 at 3.5 bits per channel—identical to the full uncompressed cache, as detailed in Table 1.
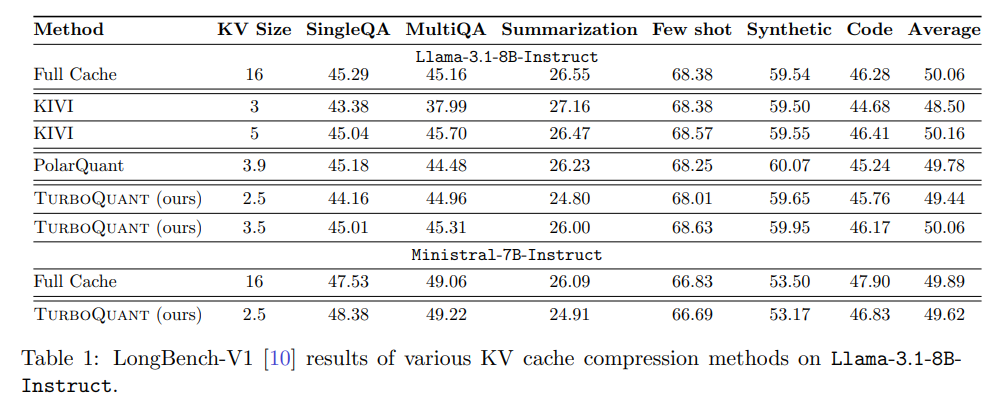
The most striking validation occurs in the long-context “Needle-In-A-Haystack” retrieval task. Visualized as heatmaps in Figure 4, several baseline methods begin to drop the hidden context as sequence lengths grow. However, TurboQuant, even when compressing the KV cache by more than 4×, maintains an absolutely perfect retrieval rate across all sequence depths and token limits, entirely indistinguishable from the full-precision model.
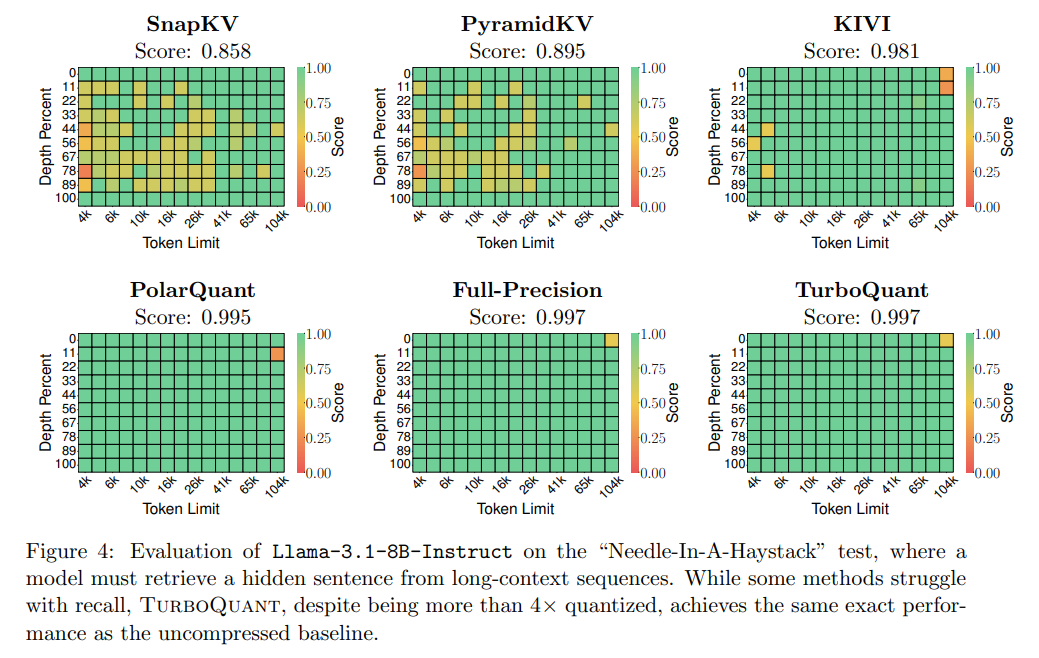
Furthermore, in nearest neighbor search tasks against competitors like PQ and RabitQ, Figure 5 demonstrates that TurboQuant consistently achieves superior Recall@1@k across varying dataset dimensions.
Theoretical Trade-offs and Limitations
While the architecture approaches the Shannon Lower Bound for distortion, it carries distinct engineering trade-offs. The random rotation matrix Π requires O(d2) compute for both quantization and dequantization. While this is easily parallelized on GPUs, it introduces strict computational overhead that may be noticeable in highly latency-sensitive, low-compute edge environments. Additionally, the authors noted that applying entropy encoding to the centroid indices could theoretically reduce the average bit-width by an additional 5%. However, they explicitly chose to abandon this step, trading marginal compression gains to preserve raw algorithmic speed and execution simplicity. Finally, the assumption that coordinates become perfectly independent heavily relies on the input dimension d being sufficiently large; performance guarantees weaken in low-dimensional spaces.
Strategic Verdict
TurboQuant represents a highly pragmatic evolution in vector compression. By leveraging the geometric properties of random rotations alongside established source coding theory, the paper bridges the gap between theoretical optimality and hardware-level execution. For research labs and enterprises scaling RAG pipelines or serving long-context LLMs, shifting from data-dependent clustering to data-oblivious, mathematical transformations provides a clear pathway to mitigating memory bottlenecks without paying the traditional penalties in latency or context degradation.