
Unchaining Language Models from Fixed Tokens
A Deep Dive into Autoregressive U-Nets
From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
Authors: Mathurin Videau, Badr Youbi Idrissi, Alessandro Leite, Marc Schoenauer, Olivier Teytaud, and David Lopez-Paz
Paper: https://arxiv.org/abs/2506.14761
Code: https://github.com/facebookresearch/lingua/tree/main/apps/aunet
TL;DR
WHAT was done? The paper introduces the Autoregressive U-Net (AU-Net), a novel architecture that learns to tokenize text internally as part of its training process. Instead of relying on a fixed, external tokenizer like Byte Pair Encoding (BPE), AU-Net operates directly on raw bytes. It uses a U-Net-like structure with contracting and expanding paths to dynamically pool bytes into hierarchical, multi-scale representations—from bytes to words, and then to multi-word chunks. This process is guided by adaptive pooling and skip connections that preserve information flow across granularities.
WHY it matters? This work challenges the fundamental reliance on static, pre-defined vocabularies in language modeling. By making tokenization a learned, internal process, AU-Net effectively achieves an "infinite vocabulary," eliminating out-of-vocabulary issues. Experiments show it matches or outperforms strong BPE baselines under controlled compute budgets, while demonstrating significant advantages in character-level reasoning and cross-lingual generalization, particularly for low-resource languages. The research presents a viable and scalable path toward more flexible, robust, and truly end-to-end language models that can adapt their own understanding of linguistic units.

Details
The Unseen Constraints of Tokenization
For years, the dominant paradigm in language modeling has relied on a crucial but often overlooked preprocessing step: tokenization. Methods like Byte Pair Encoding (BPE) have been instrumental in managing vocabulary size and computational load, but they impose a rigid, pre-defined structure on language before a model ever begins to learn. This raises a fundamental question: what if the model could learn its own "tokens," adapting its perception of linguistic units from the data itself?
A recent paper, "From Bytes to Ideas: Language Modeling with Autoregressive U-Nets," offers a compelling answer. The authors propose a novel architecture, the Autoregressive U-Net (AU-Net), that moves tokenization from an external preprocessing step to a dynamic, learned process inside the model. This work doesn't just tweak an existing model; it reimagines the very input pipeline of language models.
A Hierarchical Approach to Understanding Language
At its core, the AU-Net is an autoregressive model inspired by the U-Net architecture, widely known in computer vision (https://arxiv.org/abs/1505.04597). It operates directly on raw bytes and is designed to build a multi-scale understanding of the text. The architecture features a contracting path that progressively compresses the input sequence. For instance, the first stage might process raw bytes, the next stage could pool these bytes into word-level vectors, and a third stage could group those into two-word chunks (Figure 1). As the representation gets coarser, the model can reason about broader semantic patterns and predict further ahead in the sequence.
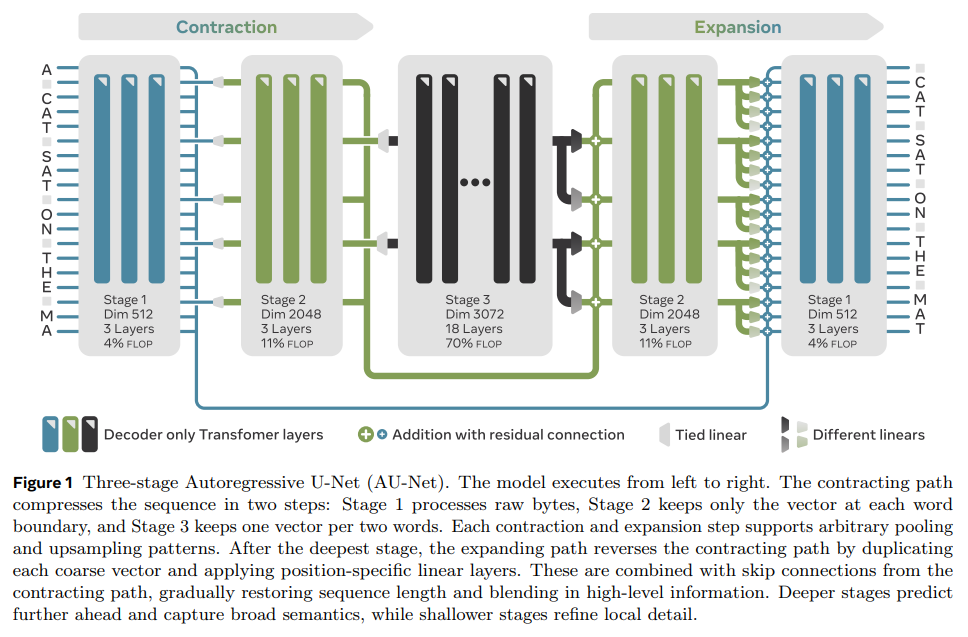
This compression is complemented by an expanding path that reconstructs the sequence, guided by information passed along skip connections from the corresponding contracting stages. This design ensures that fine-grained details (like spelling) from the byte-level stages are not lost while the model processes high-level semantic information.
The key mechanism enabling this is an adaptive pooling strategy. Unlike fixed-size windows, AU-Net uses a flexible splitting function—in this work, a rule-based regular expression—to define pooling points. This allows the model to form "tokens" based on linguistic structure (e.g., word boundaries) rather than arbitrary chunks. The authors also demonstrate methodological rigor by deriving new scaling laws for byte-level hierarchical models.

This acknowledges that shifting from token-level to byte-level training requires a fundamental rethinking of optimization. For example, they find that the optimal batch size for AU-Net scales with compute (C) as ~C^0.321, a significantly different exponent than for BPE models (~C^0.231). This kind of detailed analysis is crucial for ensuring that byte-level models can be scaled up as stably and efficiently as their token-based predecessors, making the approach practically viable.
It is important to place AU-Net within the context of other recent byte-level models. The authors distinguish their work from prior approaches like Megabytes (https://arxiv.org/abs/2305.07185) and Byte Latent Transformers (https://arxiv.org/abs/2412.09871, manual review here). The key differentiators for AU-Net are its multi-stage hierarchical structure combined with its use of global attention (or a sliding window) at each stage. This design allows it to process words and word groups as coherent units rather than isolated blocks, a limitation in some earlier designs.
Performance: Competitive, with Key Advantages
A new architecture is only as good as its performance, and AU-Net delivers compelling results. In controlled comparisons against strong BPE baselines, multi-stage AU-Nets match or exceed their performance on several standard benchmarks like Hellaswag and MMLU, with deeper hierarchies showing promising scaling trends (Figure 3).

The AU-Net 4 model, for instance, outperforms the BPE baseline on MMLU and GSM8k at a comparable scale (Table 2).

However, the true strengths of the AU-Net shine in areas requiring fine-grained text handling. On the CUTE benchmark (Table 7), AU-Net 2 demonstrates a clear advantage in character-level tasks, achieving an average accuracy of 42.7%.

Interestingly, the paper notes that the BPE baseline also performs surprisingly well on tasks like spelling and reverse spelling, despite lacking explicit character access. This highlights a key trade-off: while the BPE baseline is stronger on word-level manipulation, the byte-level AU-Net naturally excels at the character level, ultimately outperforming BPE on average for these fine-grained tasks.
By avoiding a fixed, often English-centric vocabulary, AU-Net shows superior performance in low-resource and cross-lingual settings. On the FLORES-200 translation benchmark, AU-Net consistently outperforms its BPE counterpart, demonstrating its ability to leverage shared morphological and orthographic patterns across languages (Table 3).

These results suggest that the benefits are not just theoretical. The model is practically efficient, maintaining GPU throughput comparable to traditional methods, making it a viable alternative for large-scale training.
Limitations and the Path Forward
The authors are transparent about the current limitations. The most significant is the reliance on a rule-based splitting function optimized for space-delimited, Latin-script languages. This is reflected in the model's lower performance on Chinese MMLU tasks. The natural next step, as the authors suggest, is to develop methods for learning this splitting function directly from data, making the architecture truly language-agnostic.
Furthermore, while deeper hierarchies show promise, the paper notes they may require more training data to realize their full potential. There are also software optimization challenges to overcome to efficiently scale models with many hierarchical stages.
Beyond the authors' own assessment, this line of research introduces new challenges. As models learn their own internal representations, interpreting their behavior and debugging failures may become more complex than with models that use human-readable tokens.
Conclusion: A Significant Step Towards Truly End-to-End Models
This paper presents a well-executed and thoughtfully designed study that successfully challenges a foundational component of modern language models. The Autoregressive U-Net is more than just another architecture; it's a proof of concept for a new paradigm where models learn their own linguistic building blocks from raw data.
By demonstrating competitive performance and clear advantages in robustness and cross-lingual generalization, the work provides a compelling case for moving "from bytes to ideas" directly. While challenges remain, particularly in generalizing the splitting mechanism, this paper offers a valuable and promising contribution, charting a clear path toward more flexible, capable, and truly end-to-end AI systems.