
Variable-Width Transformers (><former)
Authors: Zhaofeng Wu, Oliver Sieberling, Shawn Tan, Rameswar Panda, Yury Polyanskiy, Yoon Kim
Paper: https://arxiv.org/abs/2606.18246
Code: https://github.com/ZhaofengWu/variable-width-transformers
Model: N/A
TL;DR
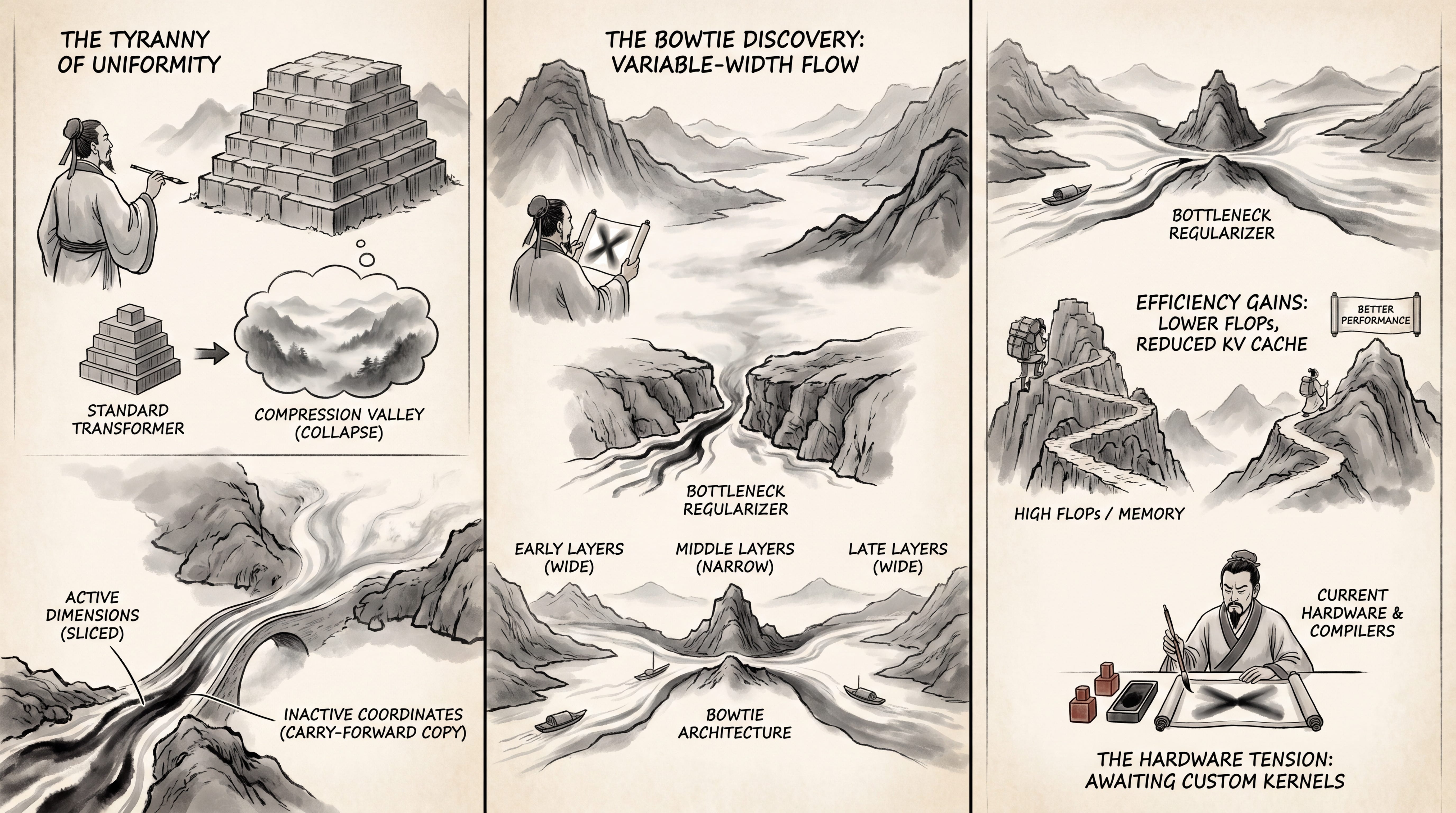
WHAT was done? The paper introduces the ><former (bowtie-former), a variable-width decoder-only transformer architecture that moves away from the traditional uniform-width layer design. It implements a ×-shaped capacity profile across network depth, keeping the early and late layers wide while narrowing the middle layers. It manages varying dimensions seamlessly using a parameter-free “carry-forward” residual resizing mechanism that copies inactive coordinates upstream, eliminating the need for trained projection layers.
WHY it matters? This work challenges the foundational, long-standing architectural assumption that transformer hidden dimensions must remain constant across all layers. By physically narrowing the middle layers, the architecture acts as a structural regularizer that mitigates representational collapse (”compression valleys”) and load-balances activation utilization. Empirically, the ><former achieves up to a 22% reduction in overall pre-training FLOPs and a 15% reduction in KV cache memory and I/O costs under fitted scaling curves, while consistently outperforming parameter-matched constant-width baselines on downstream natural language tasks.
Details
The Tyranny of the Homogeneous Hidden Dimension
Modern large language models are heavily constrained by scaling laws that dictate optimal balances of parameter count, dataset size, and compute. Since the inception of the Transformer, scaling has primarily occurred along three axes: depth, width, and attention heads. However, almost all standard architectures preserve the uniform-width assumption, allocating an identical parameter and FLOP budget to every single block across the network depth. This structural homogeneity is convenient for engineering and tensor layout but is computationally counterintuitive. Different layers play highly distinct computational roles, with intermediate layers frequently suffering from representational collapse or “compression valleys.” Prior attempts to distribute capacity non-uniformly across layers, such as DeLighT, OpenELM, or Crown, frame, reverse, have sought to vary the attention-head count, MLP expansion multipliers, or layer-wise depth allocation. Others, like Ikeda et al. (2025), focused strictly on the feed-forward network (FFN) intermediate dimension. The ><former addresses the core representation path itself by varying the full block hidden dimension across depth, showing that the optimal structural shape is a symmetric bottleneck.
