


Vision-Language Models Create Cross-Modal Task Representations
Authors: Grace Luo, Trevor Darrell, Amir Bar
Paper: [ICML 2025] https://openreview.net/forum?id=77ziPGdQct, https://arxiv.org/abs/2410.22330
Code: https://vlm-cross-modal-reps.github.io/
TL;DR
This paper provides compelling empirical evidence that Vision-Language Models (VLMs) develop a shared, abstract "task vector" to represent tasks internally. This representation is invariant to the input modality (image or text) and format (examples or instructions). The authors demonstrate this through a technique called "cross-modal patching," where this compressed task vector is extracted from one modality and injected into the model's processing of another. This method is shown to be more effective than traditional few-shot prompting for steering model behavior across modalities. For example, a task learned from text examples can be successfully applied to an image query, often with higher accuracy and lower resource usage due to the ability to cache and reuse the compact task vector.
These findings are significant because they reveal a deeper, more generalized form of task understanding within VLMs, moving the field beyond simple prompt engineering toward more direct and precise control over model behavior. The discovery of these transferable task vectors—which can even be passed from a base language model to its fine-tuned VLM counterpart—opens new avenues for mechanistic interpretability, model efficiency, and building more flexible and intuitive AI systems.

Details
Autoregressive Vision-Language Models (VLMs) have demonstrated a remarkable ability to perform a wide variety of tasks based on context. However, the internal mechanisms that grant them this flexibility have remained largely opaque. A fundamental question is how these models handle the myriad ways a single task can be described—be it through text, images, examples, or direct instructions. Do these different specifications lead to siloed processing paths, or do they converge into a unified, abstract understanding?
This paper offers a clear answer, revealing that VLMs develop a shared, modality-invariant "task representation." This work sheds light on an emergent "task intelligence" within these models, showing they are not just mapping inputs to outputs but are building a generalized, internal concept of the task itself.

From Prompting to Patching: A New Way to Steer VLMs
The core of the paper's methodology is a technique termed "cross-modal patching," which builds on recent breakthroughs in language-only models that first identified how in-context learning creates "task vectors" (https://arxiv.org/abs/2310.15916) or "function vectors" (https://arxiv.org/abs/2310.15213). This paper's key contribution is uniquely exploring these vectors in a cross-modal setting.
The "task vector" is a specific, measurable artifact within the model: the hidden state activation at a special delimiter token at a specific intermediate layer of the transformer. Instead of relying on traditional few-shot prompting, the authors extract this task vector from one modality and directly inject, or "patch," it into the model while it processes a query from another modality (Figure 3a).

This method serves as a powerful analytical tool. The authors found that few-shot prompting across modalities often struggles; models tend to "regurgitate" the provided examples rather than apply the underlying task to the new input (Figure 4).

Consider the task of identifying a country's capital. The model is first given text examples like {Greece: Athens}. The authors extract the resulting task vector—the model's internal summary of the "country-to-capital" function. Then, they present the model with only an image of the French flag. Instead of a long text prompt, they simply "patch" the task vector into the model's processing pipeline. While standard prompting might fail, the patched model correctly outputs the answer: Paris. This demonstrates that the patched vector cleanly carries the concept of the task, divorced from the specific examples it was learned from.
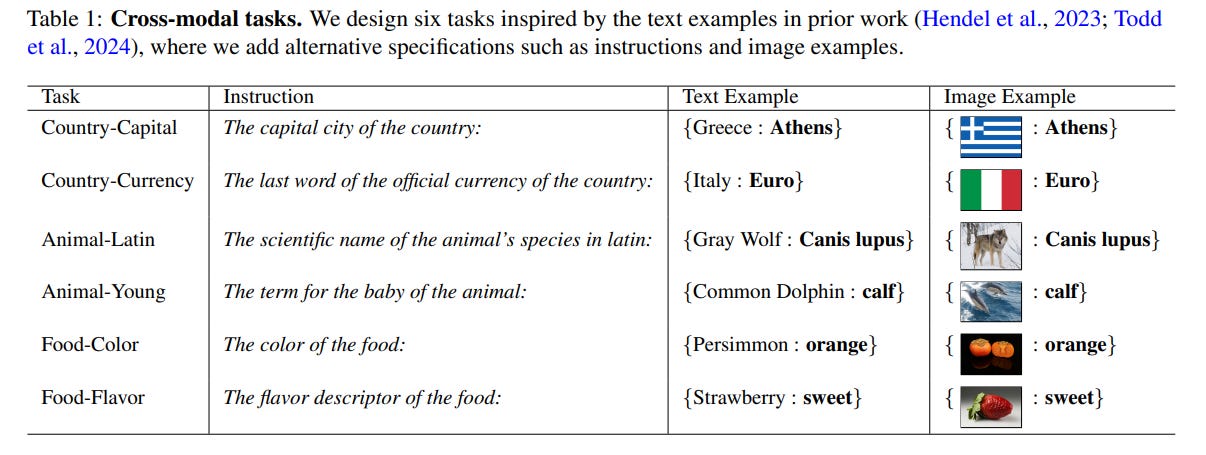
Across a range of tasks and models (including LLaVA, Mantis-Fuyu, and Idefics2), patching a task vector derived from text examples onto an image query significantly outperformed prompting with the full text examples, improving performance by 14-33% on average (Table 2). This efficiency gain also extends to computation; once computed, the task vector can be cached and reused for many queries, avoiding the costly re-processing of full examples required by prompting.

The Emergence of a Shared Task Language
The paper's findings consistently point to the existence of a shared semantic space for tasks that transcends input type. Key results include:
Clustering by Task, Not Modality: A t-SNE (http://jmlr.org/papers/v9/vandermaaten08a.html) visualization reveals that while raw context embeddings for images and text remain distinct, the derived task vectors cluster cleanly by the task they represent, regardless of whether they originated from image or text examples (Figure 2).

Knowledge Transfer from LLMs to VLMs: In one of the most surprising findings, the authors show that task vectors are highly preserved when a base Large Language Model (LLM) is fine-tuned into a VLM. Task vectors extracted from the base LLM could be patched into its VLM descendant to solve visual tasks, in some cases performing even better than vectors from the VLM itself (Table 3).

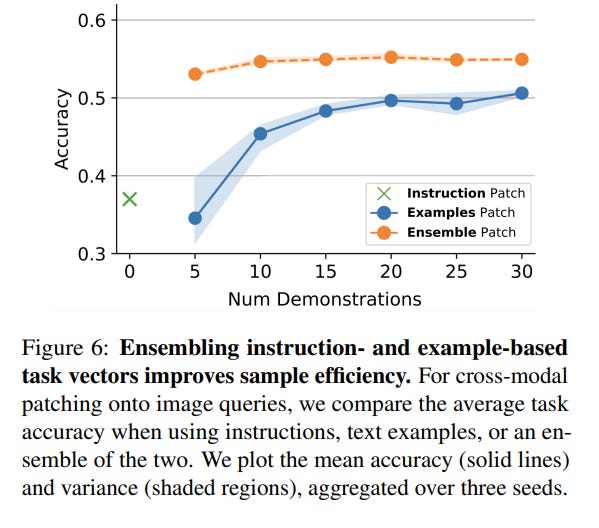
Instructions as Task Vectors: The research demonstrates that task vectors don't require lengthy examples. They can be derived from concise, natural language instructions, and ensembling these with example-based vectors improves sample efficiency and reduces performance variance (Figure 6).

Overriding Model Behavior: This method offers a new level of control. A patched task vector can effectively override a pre-existing task in the prompt, steering the model's behavior locally without changing the global context (Table 5).




Unveiling the Internal 'Thought Process'
By analyzing the representations across model layers, the authors provide a glimpse into how these task vectors are formed and utilized. They identify three distinct processing phases: an initial "input" phase encoding the raw query, a middle "task" phase where the abstract task summary emerges, and a final "answer" phase where the task is executed (Figure 8).

This structured internal process, consistent across both text and image inputs, reinforces the idea that VLMs are developing a systematic and generalized approach to problem-solving.
Limitations and Overall Assessment
The authors rightly acknowledge that while their work shows that VLMs create these cross-modal representations, a definitive explanation for why this phenomenon occurs remains an open question for future research. The evaluated tasks, while diverse, are also relatively simple, leaving room to explore how these findings generalize to more complex, multi-step reasoning.
Despite this, "Vision-Language Models Create Cross-Modal Task Representations" is a significant contribution to the field. It provides strong empirical evidence for an emergent, abstract task intelligence in VLMs and introduces a powerful methodology for probing and controlling it. By moving beyond the limitations of traditional prompting, this work paves the way for building more efficient, interpretable, and flexible multimodal AI systems. It offers a valuable look into the "mind" of these models, revealing a structured and shared language for tasks that is a crucial step toward more capable and understandable AI.