
What Characterizes Effective Reasoning? Revisiting Length, Review, and Structure of CoT
Authors: Yunzhen Feng, Julia Kempe, Cheng Zhang, Parag Jain, Anthony Hartshorn
Paper: https://arxiv.org/abs/2509.19284
TL;DR
WHAT was done? The authors conduct a systematic re-examination of what makes Chain-of-Thought (CoT) reasoning effective across ten large reasoning models. They challenge the “longer-is-better” narrative by showing that shorter CoTs and less review are generally associated with higher accuracy. The core contribution is the introduction of a novel structural metric, the Failed-Step Fraction (FSF), which is the proportion of steps in abandoned reasoning branches. This metric is derived from a new, simplified method for extracting a reasoning graph directly from a CoT trace.
WHY it matters? This work fundamentally shifts the focus from the quantity of reasoning (more tokens) to its structural quality. FSF consistently outpredicts traditional metrics for correctness. Crucially, the authors provide strong causal evidence for its importance: 1) test-time selection using FSF yields significant accuracy gains (up to 13%), and 2) editing CoTs to remove failed branches improves accuracy on incorrect traces by 8-14%. This latter finding suggests that current models don’t fully “unsee” their mistakes; the presence of a failed path appears to poison subsequent reasoning. The paper makes a compelling case that future efforts should prioritize structure-aware scaling and context control over indiscriminate generation.

Details
The Evolving Narrative of AI Reasoning
The quest to enhance the reasoning capabilities of Large Language Models (LLMs) has led to a focus on Chain-of-Thought (CoT) prompting. An influential line of work, starting with S1 (https://arxiv.org/abs/2501.19393, review is here), suggested that increasing test-time compute by generating longer reasoning traces could improve performance. This “longer-is-better” narrative, however, has recently been met with conflicting findings. This paper provides a rigorous, systematic investigation to settle the debate and uncover what truly characterizes effective reasoning.
Methodology: From Tokens to Structure
The authors analyze the performance of ten diverse LLMs—including proprietary and open-source models—on mathematical (HARP) and scientific (GPQA-Diamond) reasoning tasks. Their methodology moves beyond superficial metrics to dissect the underlying structure of thought.
Models investigated:
Proprietary models with CoT access: Claude 3.7 Sonnet Thinking, Grok 3 mini.
Open Sourced Families: Deepseek R1 (20250120), Deepseek Distill Qwen 32B (Deepseek 32B), Deepseek Distill Qwen 7B (Deepseek 7B), Qwen 3 235B, Qwen 3 32B, Qwen 3 8B, GPT oss 120B, GPT oss 20B.
The authors argue that simple token-level metrics like length are one-dimensional and can mistakenly penalize a lengthy but correct thought process or fail to capture the inefficiency of a short but flawed one. By extracting a reasoning graph, they move from a linear sequence of tokens to a structured representation, allowing for a more nuanced analysis of its quality. This led to the evaluation of three key properties:
Length: The total character count.
Review Ratio: The fraction of the CoT dedicated to reviewing, checking, or backtracking.
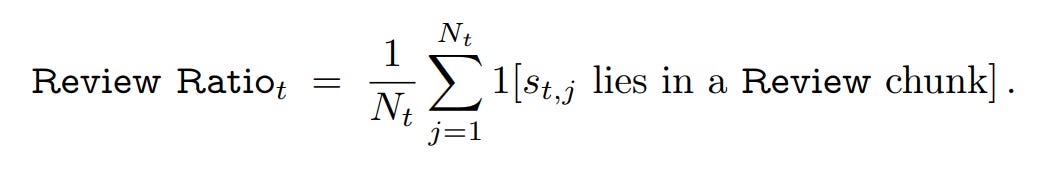
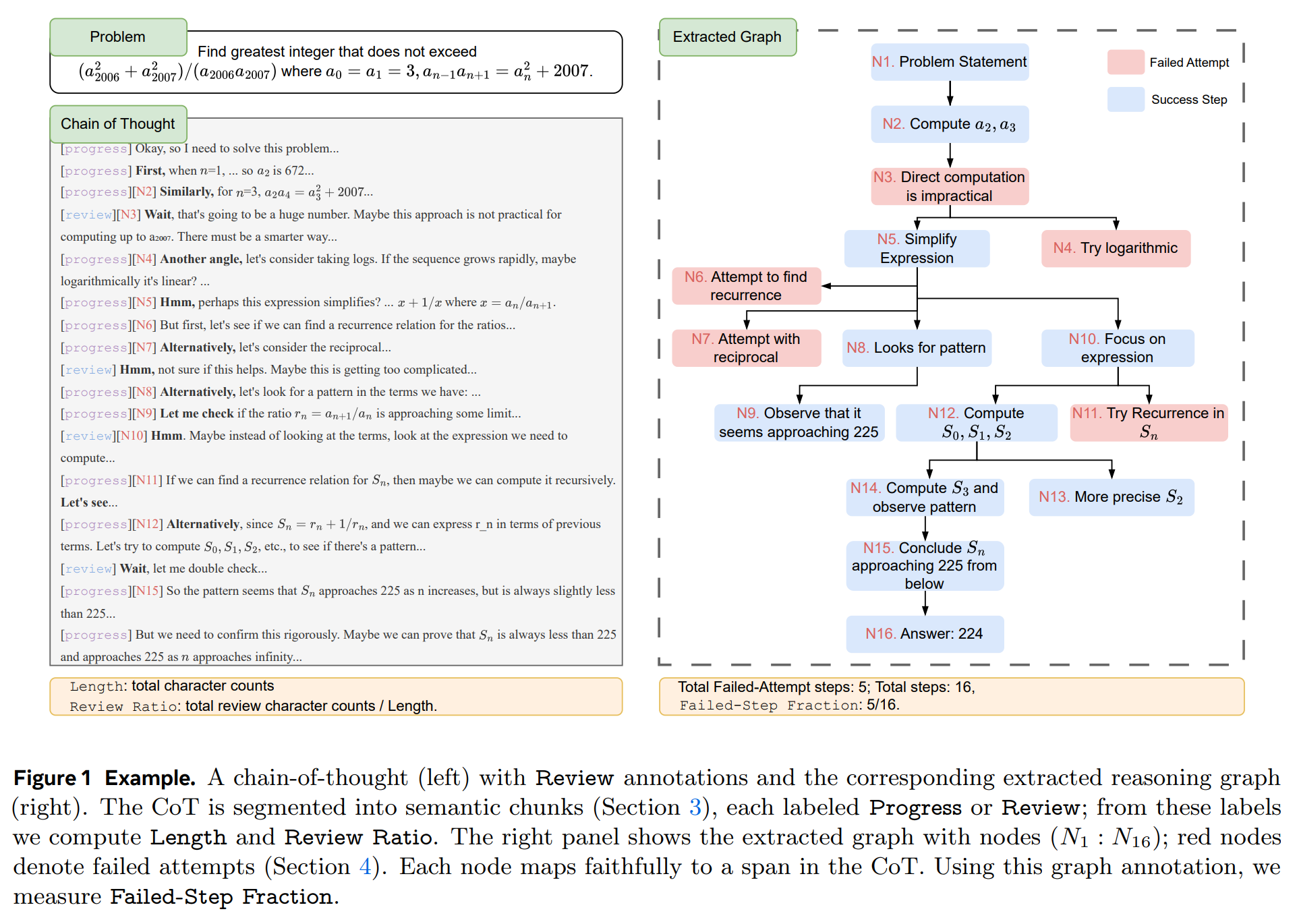
Failed-Step Fraction (FSF): This novel metric required a new approach. It’s worth noting the elegance of their method: instead of relying on complex multi-stage prompting or embedding-based clustering, the authors leverage the innate capability of a modern LLM (Claude 3.7) to directly translate natural language reasoning into a formal Graphviz structure (Figure 1).
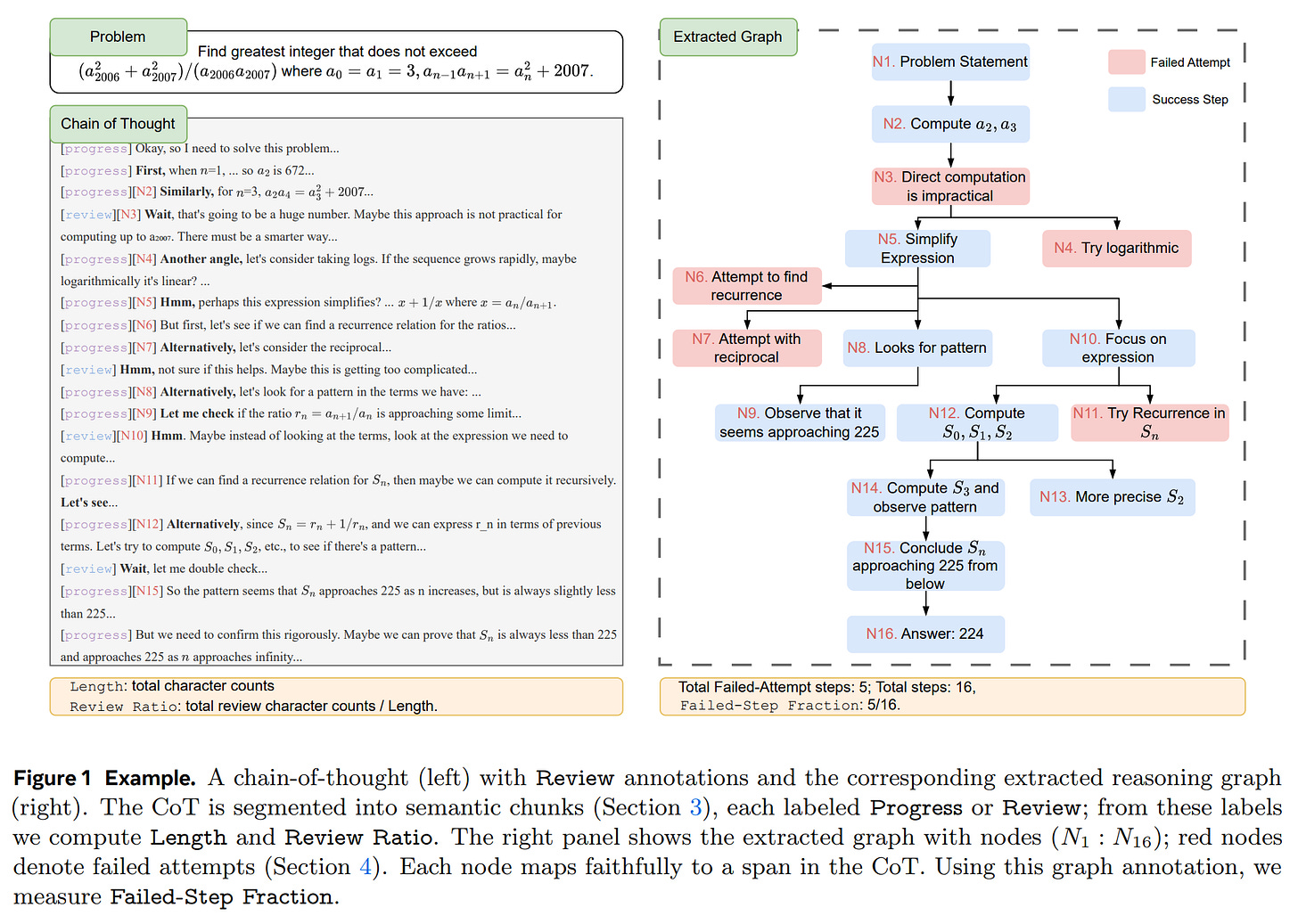
FSF is then defined as:
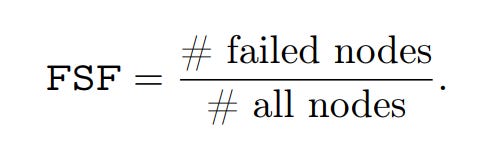
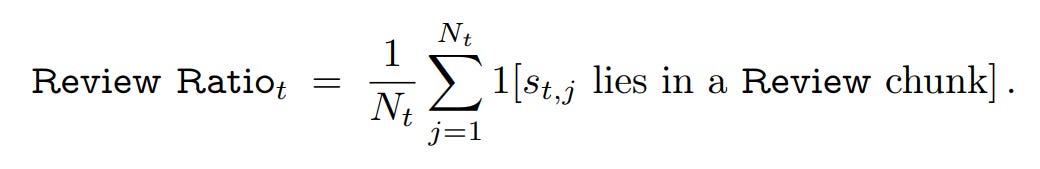
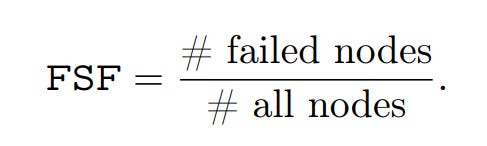
To ensure the reliability of their findings, the authors employ a conditional correlation analysis and a Bayesian Generalized Linear Mixed-Effects Model (GLMM). This statistical rigor controls for confounding variables like question difficulty, isolating the true relationship between each metric and correctness.
Key Findings and Causal Evidence
The experimental results offer a clear and compelling counter-narrative to the idea that more thinking is always better.
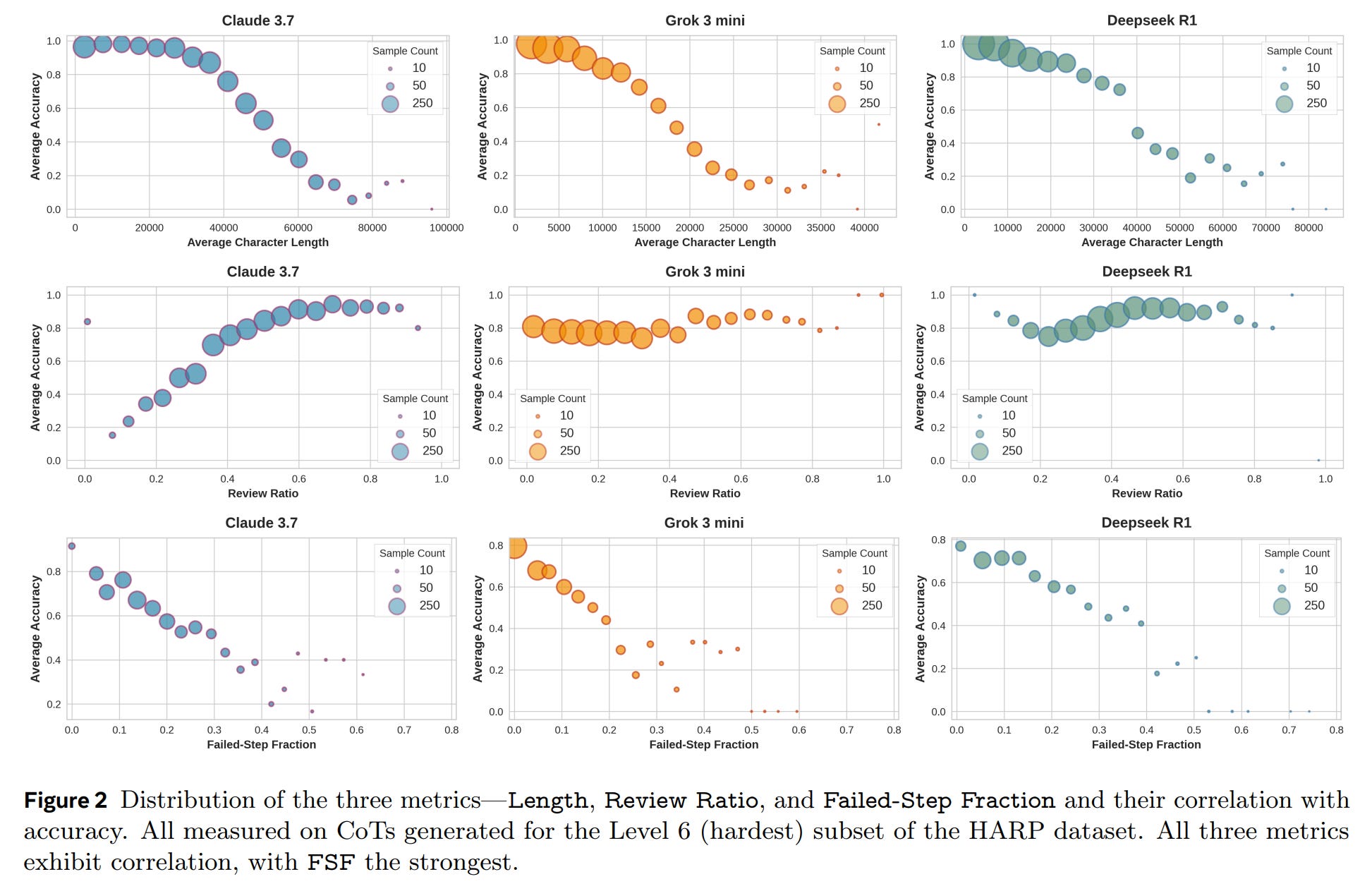
Correlations: Quality Over Quantity
When controlling for question-level effects, the analysis reveals consistent patterns across models and datasets (Figure 3, Figure 4):
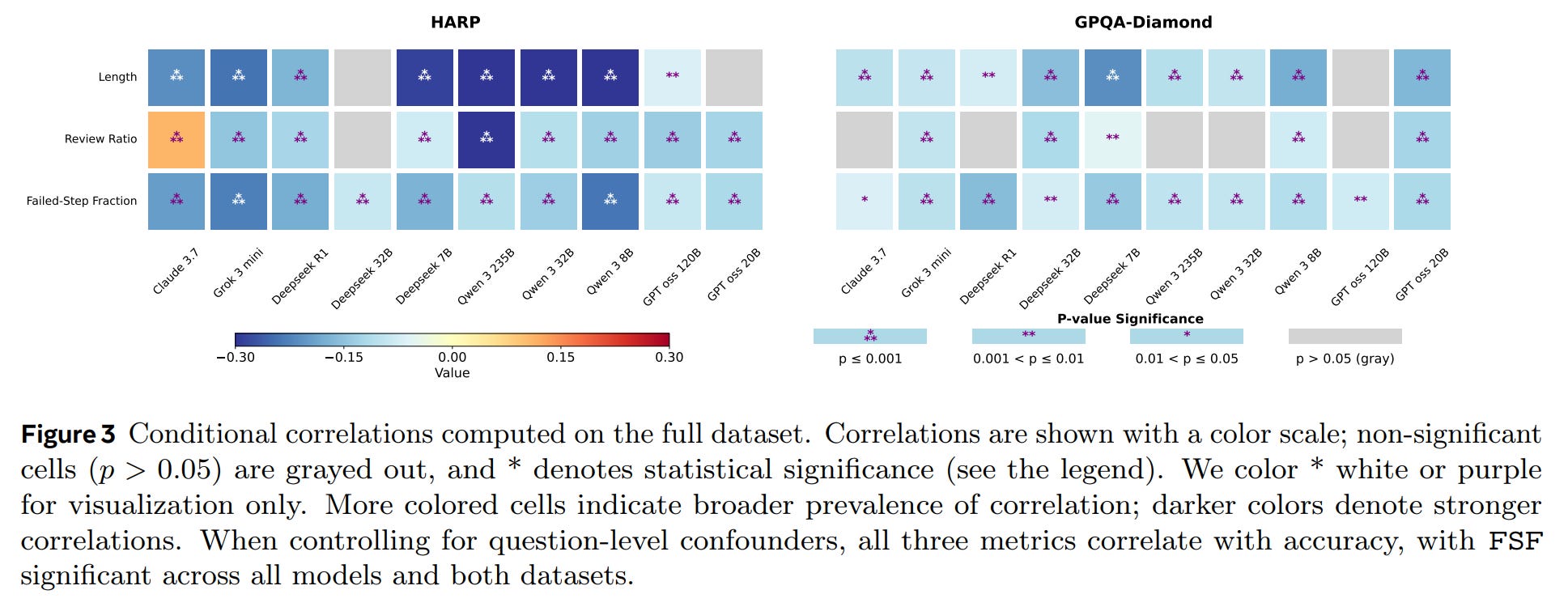
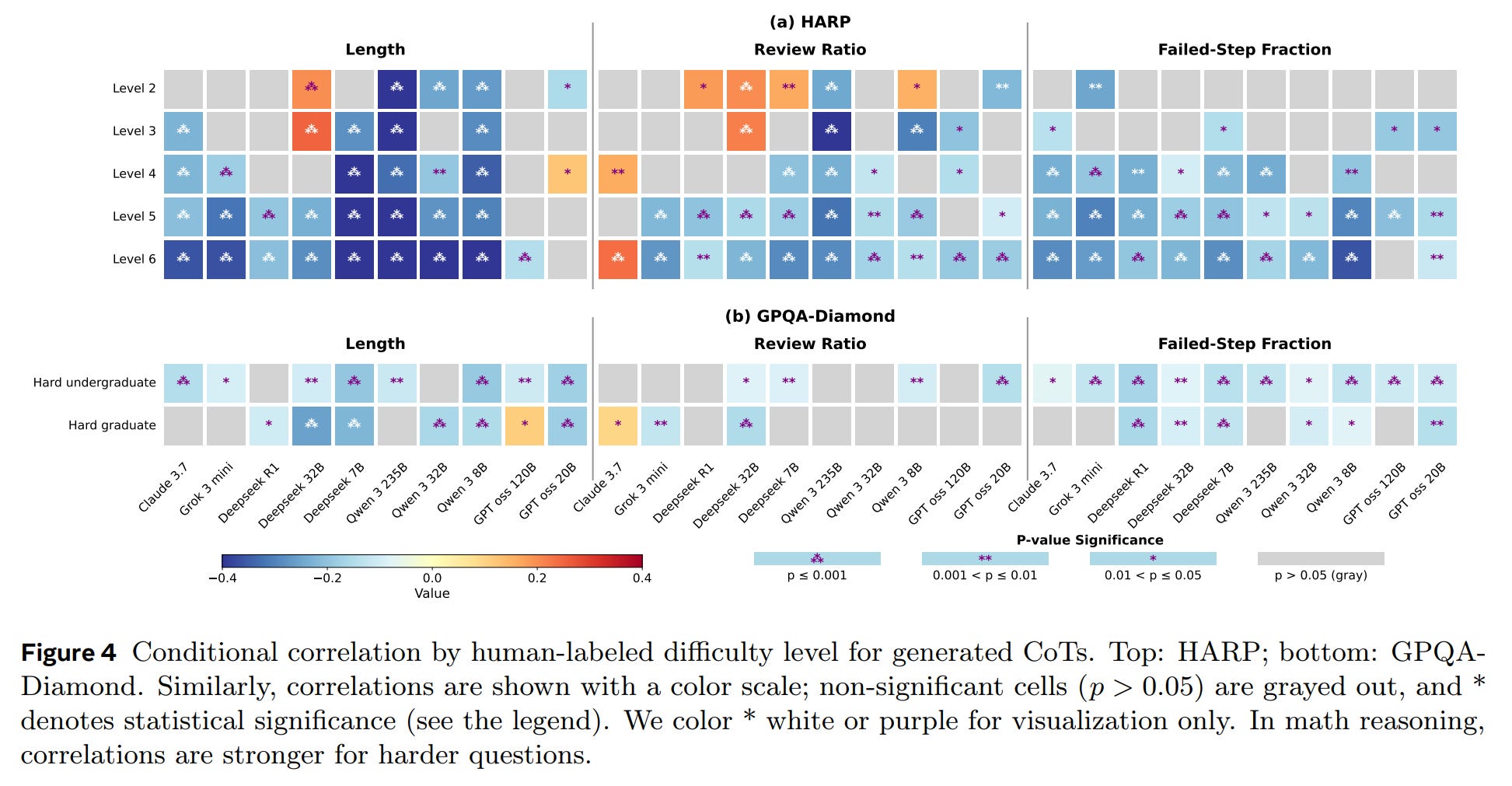
Both Length and Review Ratio show a consistent negative correlation with accuracy. For a given problem, shorter and less review-heavy CoTs are more likely to be correct.
The Failed-Step Fraction (FSF) emerges as the most robust predictor. A lower FSF—indicating a more direct and less error-prone reasoning path—consistently and significantly correlates with higher accuracy across all ten models. It proves to be a far more reliable indicator of reasoning quality.
Beyond Correlation: Proving Causality
To establish that FSF is not merely predictive but causal, the authors designed two powerful interventions:
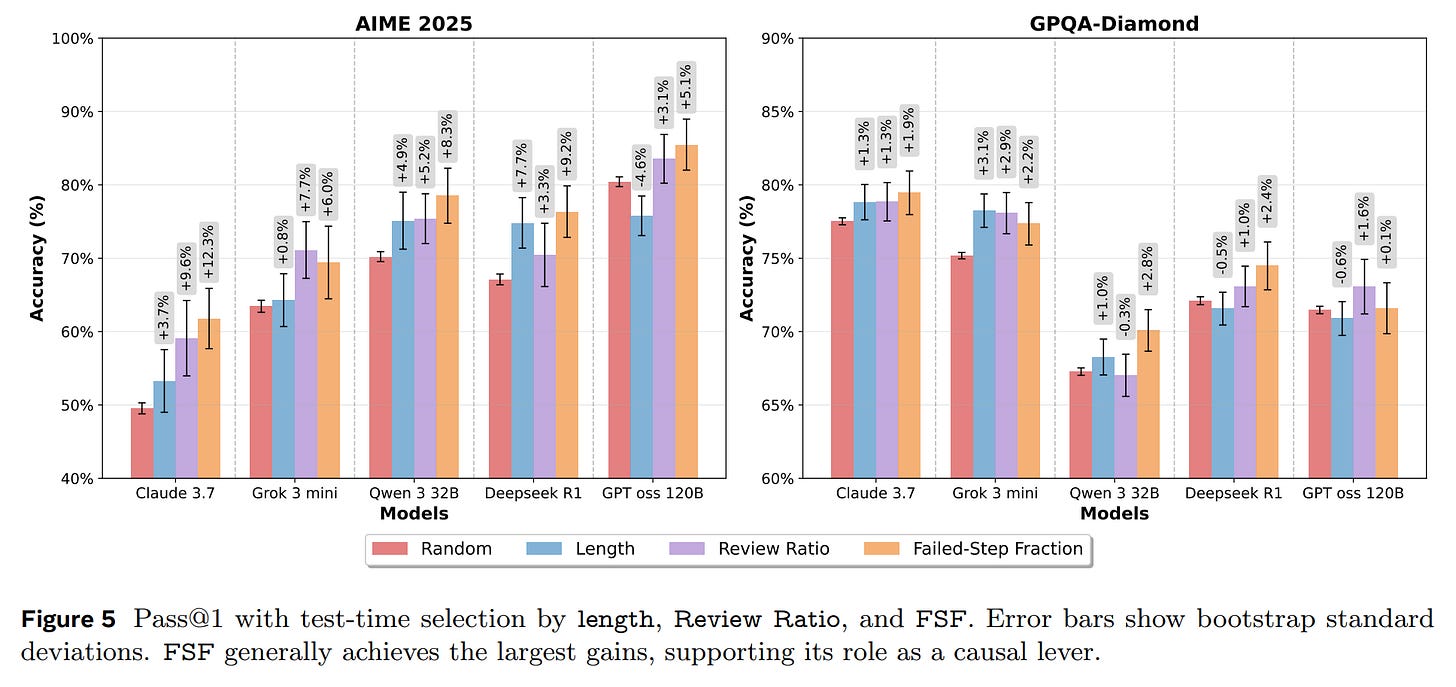
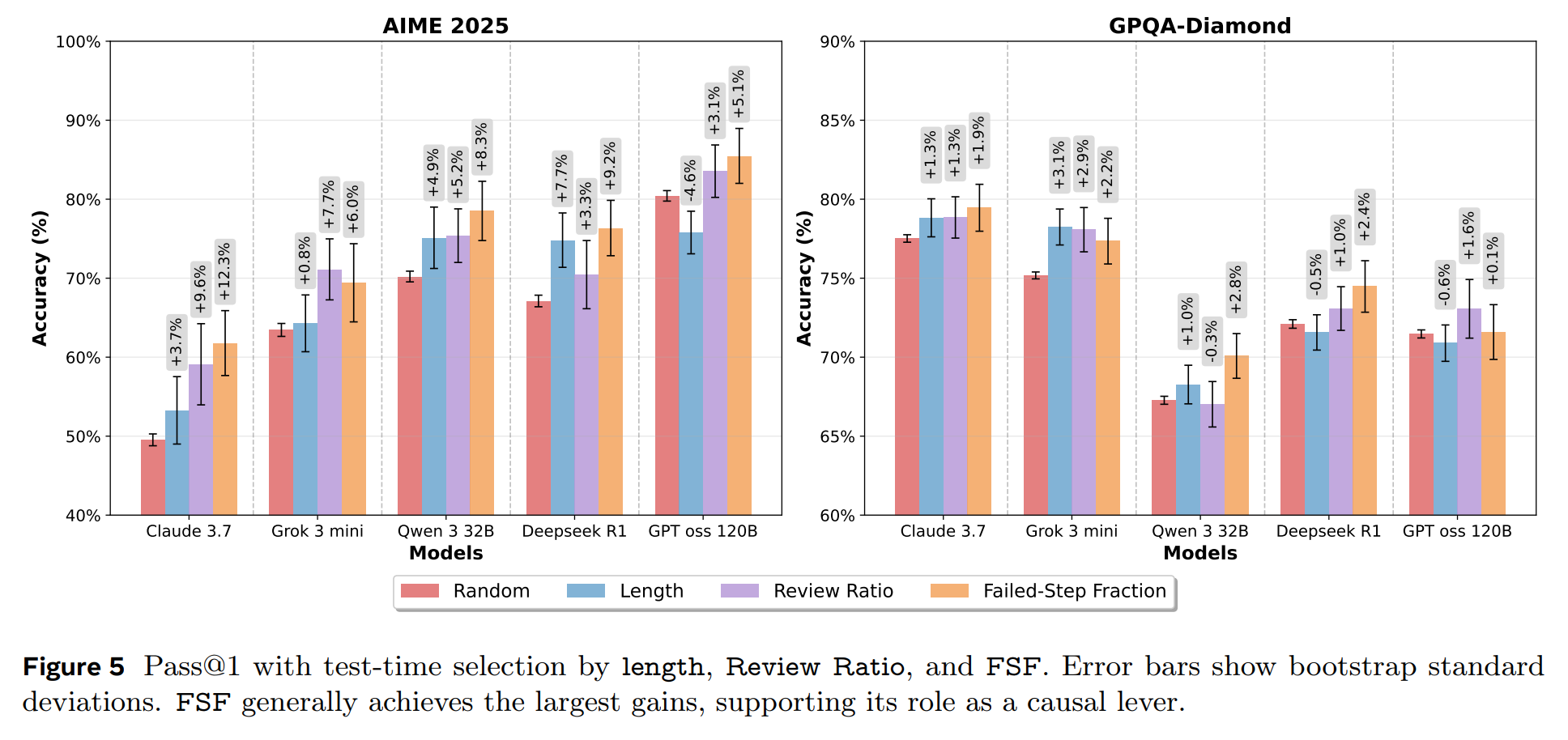
Test-Time Selection: For a given problem, they generated 64 candidate solutions and used different metrics to select the single best one. FSF-based selection consistently delivered the largest accuracy improvements, boosting performance by 5-13% over a random baseline (Figure 5). This demonstrates its practical value as a selection criterion.
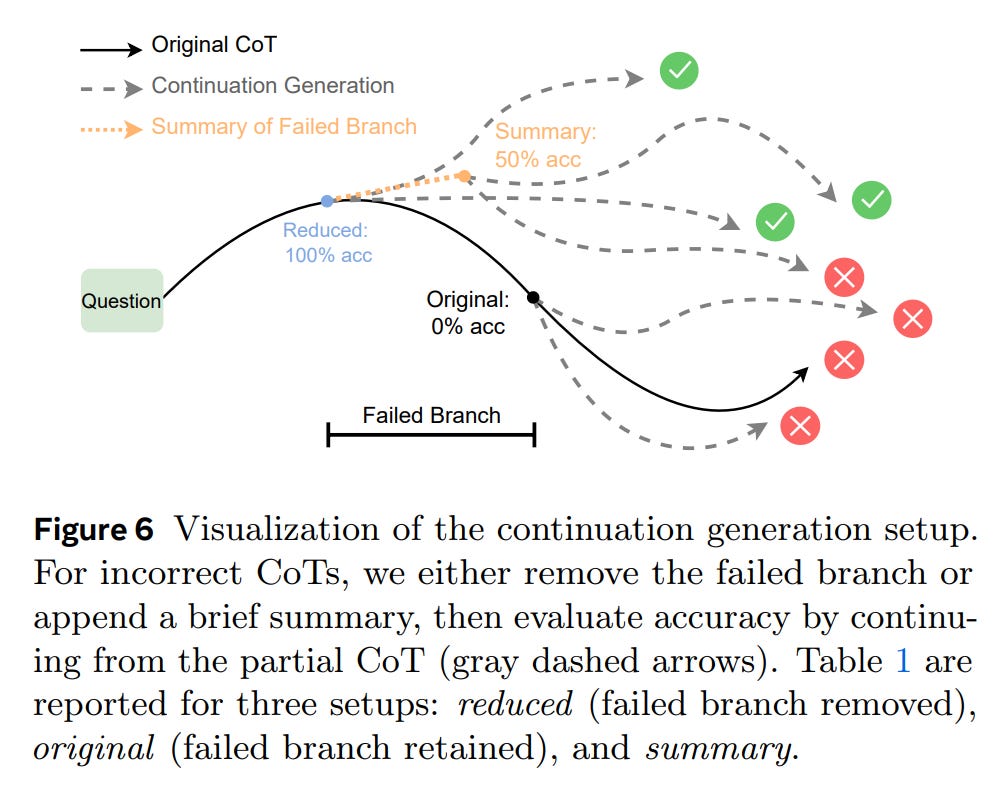
Controlled CoT Editing: In a direct causal probe, the authors took incorrect reasoning traces and edited them to remove the identified failed branches.
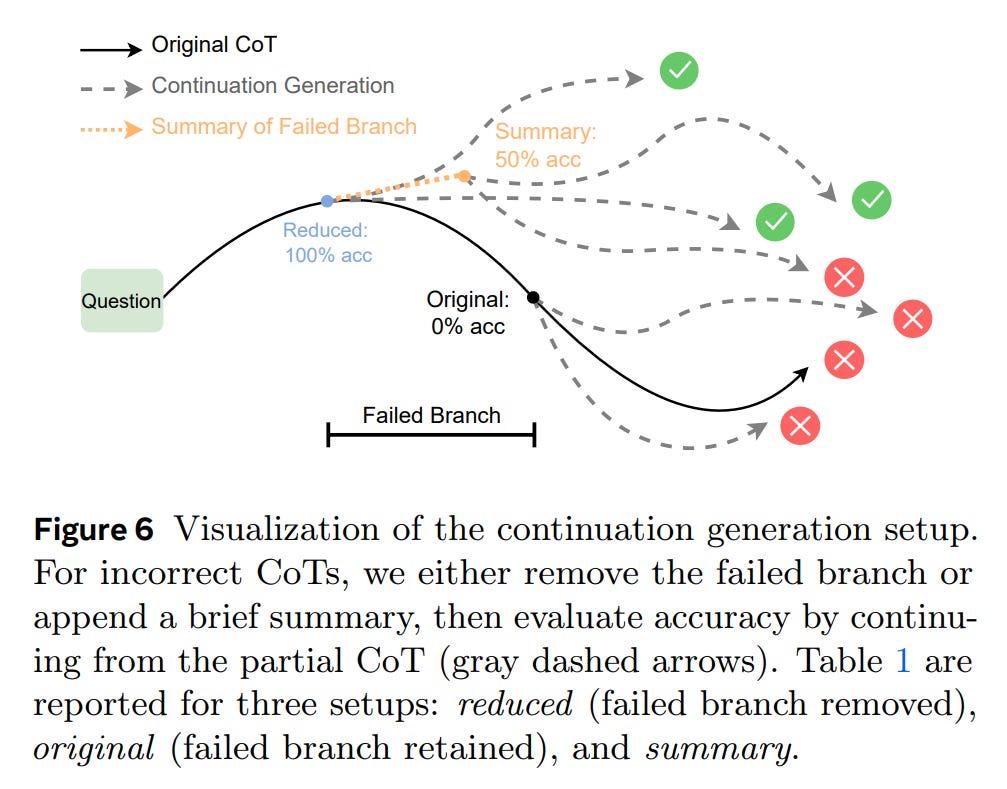
When the models continued generating from these “cleaned” traces, their accuracy improved substantially, by roughly 8-14% (Table 1). This crucial finding indicates that current models do not fully “unsee” their mistakes. The lingering presence of a failed path biases subsequent reasoning, reducing the probability of reaching a correct answer.


What’s Next? From Scaling Tokens to Scaling Quality
The implications of this work extend beyond just evaluating CoT. The authors’ findings serve as a course correction for the field, suggesting that the relentless pursuit of longer reasoning traces may be misguided. The future of advanced reasoning may lie not in indiscriminately generating more tokens, but in developing “structure-aware” methods that focus on quality.
This could involve techniques for targeted branch pruning during inference, early detection of failing reasoning paths, or managing the model’s context to minimize the negative influence of past mistakes. This paper makes a compelling case that the next frontier in AI reasoning is not about thinking longer, but about thinking smarter.