
What do Language Models Learn and When? The Implicit Curriculum Hypothesis
Authors: Emmy Liu, Kaiser Sun, Millicent Li, Isabelle Lee, Lindia Tjuatja, Jen-tse Huang, Graham Neubig
Paper: https://arxiv.org/abs/2604.08510
Code: https://github.com/KaiserWhoLearns/ElementalTask
Model: N/A
TL;DR
WHAT was done? The authors propose and validate the Implicit Curriculum Hypothesis, demonstrating that language models acquire skills during pretraining in a highly stable, compositional, and predictable order across different model families, sizes, and training data mixtures. To verify this, they design a custom suite of 91 simple and compositional tasks, mapping the developmental trajectories of 9 models from 4 major open-weight families spanning 410M to 13B parameters.
WHY it matters? This research shifts the paradigm of pretraining diagnostics away from uninterpretable, smooth validation loss curves and coarse downstream benchmarks toward a structured approach where skill acquisition is predictable and legible. Most remarkably, it proves that the pretraining trajectory of a completely unseen, out-of-distribution compositional task can be predicted solely from the geometric proximity of its task representation (function vector) in the model’s residual stream.

Details
Beyond the Smooth Facade of Aggregate Scaling Laws
Traditional pretraining diagnostics are severely bottlenecked by a reliance on global, aggregate metrics. Developers typically monitor large-scale training runs via next-token validation cross-entropy loss or by evaluating at periodic intervals on composite downstream benchmarks. However, aggregate loss decreases smoothly even as models undergo sudden, qualitative phase transitions, masking the discrete moments when specific skills are mastered. Conversely, downstream benchmarks compose many prerequisite skills simultaneously, making failures opaque; when a model stalls on a complex dataset, it is difficult to isolate whether the bottleneck is basic syntactic parsing, numerical fluency, or multi-step reasoning. While theoretical frameworks like the Quantization Hypothesis suggest that scaling curves are composed of discrete learning units, they often treat these skills as independent and additive. This paper addresses this gap by defining a structured, compositional evaluation suite that explicitly maps the developmental dependencies and cross-model consistency of skill acquisition during pretraining, moving beyond the limitations of aggregate scaling metrics.
Formalizing the Implicit Curriculum and Representational Units
To mathematically formalize the Implicit Curriculum Hypothesis, the authors construct a set of tasks T equipped with a design-level dependency relation ≺. Here, τi≺τj indicates that task τj is explicitly constructed to compositionally depend on task τi. The prerequisite set of a given task τ is denoted as P(τ)={τ′∈T:τ′≺τ}. Let the empirical emergence time of a task on a model m be denoted by tτ∗(m), defined as the first training checkpoint at which performance exceeds an absolute accuracy threshold θ. The hypothesis is evaluated on three core claims.
First, compositional ordering (H1) states that tasks emerge no later than the tasks constructed to depend on them:
∀τj∈T,∀τi∈P(τj):tτi∗(m)≤tτj∗(m)
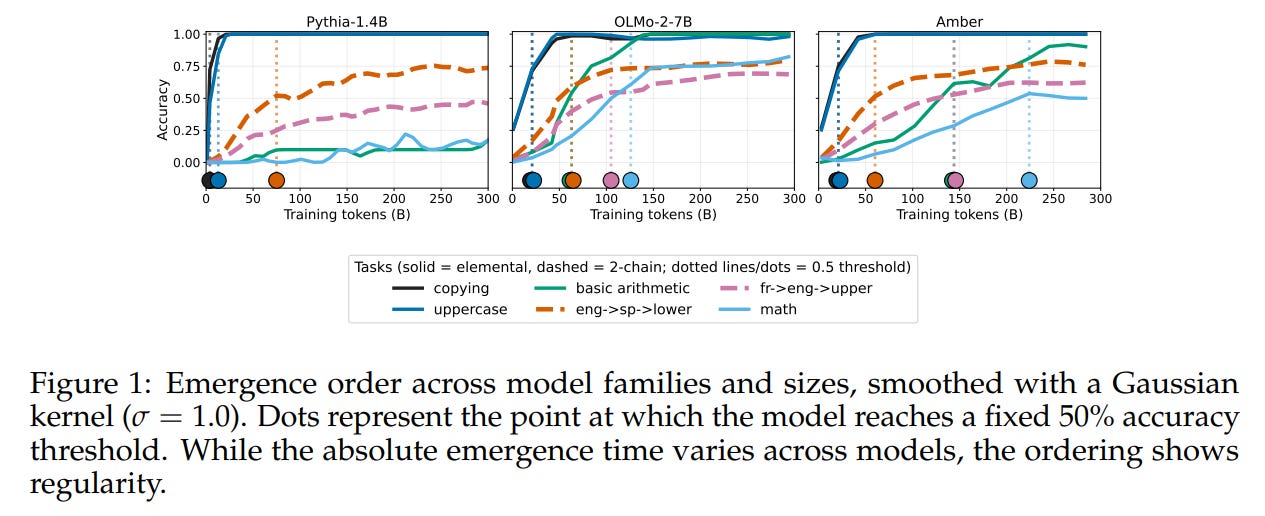
Second, cross-model stability (H2) asserts that the emergence ordering induces a partial order ⪯T over tasks that is highly consistent across distinct model architectures and data mixtures.
Third, representational alignment (H3) posits that tasks with similar internal representations exhibit similar learning trajectories. These representations are captured as function vectors vi,vj in the model’s residual stream, acting as the atomic units of task execution. If the similarity between these vectors is high, the distance d between their pretraining learning trajectories aτi(⋅),aτj(⋅) is bounded by a small threshold ϵ:
Sim(vi,vj) high⟹d(aτi(⋅),aτj(⋅))<ϵ

Constructing and Predicting Trajectories via Kernel Ridge Regression
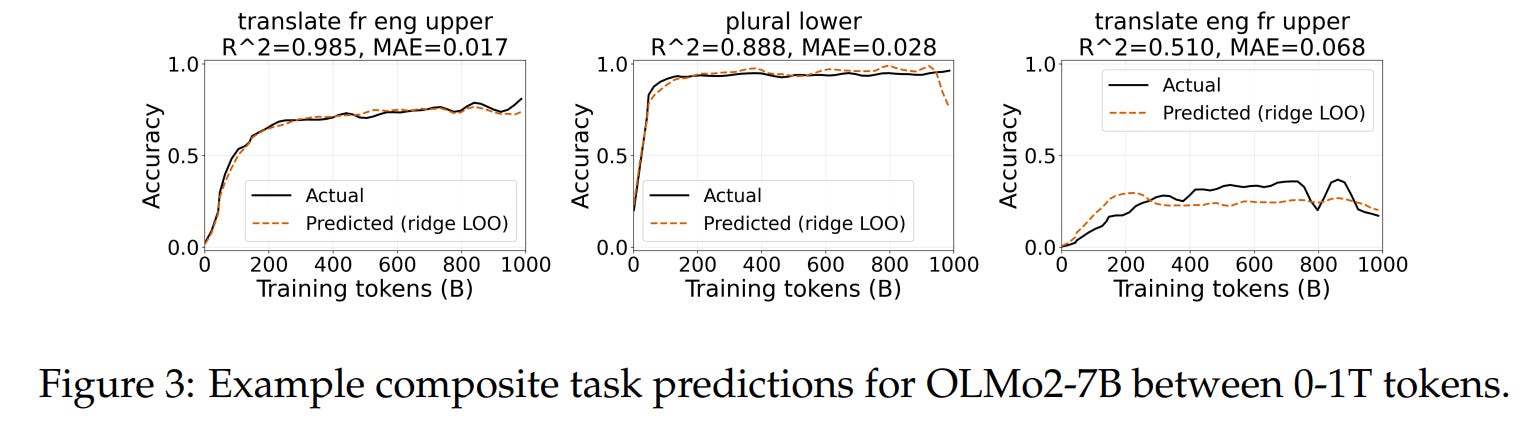
The core mechanism of the paper utilizes the geometry of the task representation space to predict the learning curves of unseen tasks. To illustrate this process, let us consider a concrete running example: predicting the pretraining trajectory of a held-out composite task like Spanish-to-English translation followed by string reversal (e.g., inputting “hola” to get “hello” and then reversing it to output “olleh”, listed as translate_sp_eng_reverse in Table 5).
First, the function vector vc is extracted for this held-out task c at a calibrated layer of a model checkpoint. Next, we define a basis set S consisting of other evaluated tasks (such as Spanish-to-English translation, string reversal, and uppercase formatting) alongside their respective function vectors {vτj}j∈S and their smoothed pretraining trajectories yt at each checkpoint step t. Pairwise similarities between these task representations are computed using a Radial Basis Function (RBF) kernel:
where σk is the kernel bandwidth parameter. This yields a kernel similarity matrix KS∈R∣S∣×∣S∣ over the training tasks, and a vector of similarities between the held-out task and the basis set kc=[K(vc,vτj)]j∈S. Kernel ridge regression is then solved analytically at each training step t using the closed-form update rule:
αt=(KS+λI)−1yt
where λ is a ridge regularization parameter to stabilize the matrix inversion. The predicted trajectory value for the held-out composite task c at training step t is computed as:
âc(t)=kc⊤αt
As shown in Figure 3, this predicted curve âc(t) is mapped out across the entire pretraining token timeline, capturing both the initial emergence onset and the subsequent rate of performance improvement without ever directly evaluating the model on the held-out task during training.
Function Vector Extraction and Trajectory Smoothing Protocols
To ensure reproducibility, the task representations are extracted using precise mechanistic protocols across different transformer block structures. Let a transformer block ℓ have hidden state hℓ and post-attention state hℓattn, such that hℓ=hℓattn+MLP(LN(hℓattn)). The paper compares two extraction techniques at the last non-pad token position tlast on correct prompts. The first is head-based extraction, which isolates a causal set of attention heads H using causal indirect effect (CIE) analysis, defining the function vector as:
where ahj(xi) is the output of attention head h in block j, and Dτ+ is the set of correctly answered prompts. The second is hidden-state extraction, which directly averages the post-MLP hidden state at block ℓ:
The specific hyperparameters chosen for each evaluated architecture are listed in Table 11. For example, the full residual stream was extracted at layer 21 for LLM360 Amber, layer 12 for Pythia-1.4B, and layer 16 for OLMo-2 7B.
To stabilize representational similarity, function vectors are unit-normalized prior to computing the pairwise kernel matrix. Raw task performance trajectories (exact-match accuracy across 20 intermediate checkpoints sampled up to 1T tokens) are smoothed using a Gaussian kernel with σ=1.0, and any trajectory showing near-zero variance is discarded to avoid numerical instability.
Empirical Proof: Cross-Model Stability and the Compositional Bottleneck
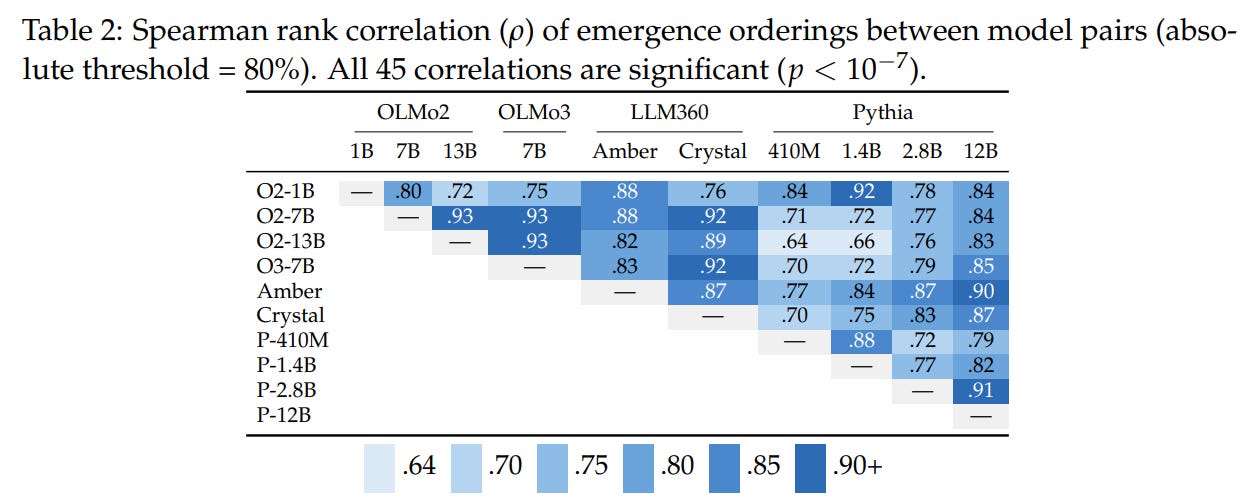
The experimental findings strongly support the Implicit Curriculum Hypothesis. Under the absolute threshold definition (θ=0.8), cross-model Spearman rank correlations are remarkably high and statistically significant (p<10−7) across all 45 model pairs, as detailed in Table 2. The correlations remain high even when comparing entirely different families trained on different data mixtures, such as OLMo2-1B and Pythia-12B (ρ=0.84), with an overall mean correlation of ρ=0.81.
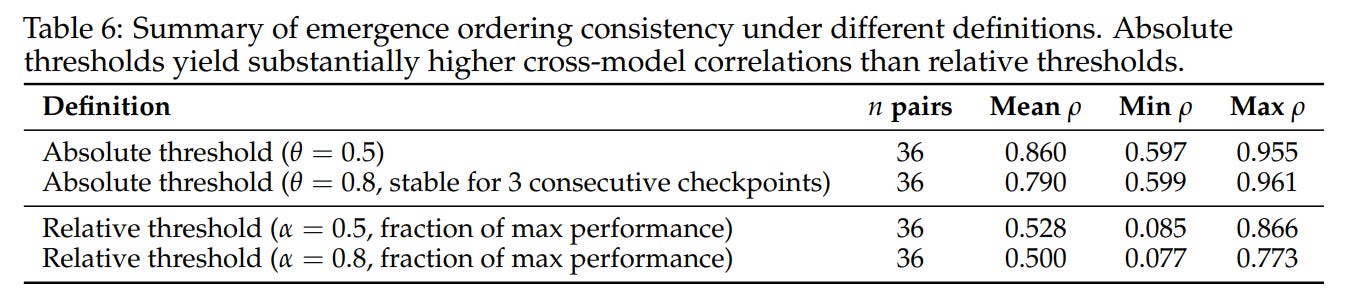
Interestingly, this consistency drops substantially when using relative thresholds (as shown in Table 6), demonstrating that absolute functional circuits emerge in a fixed sequence, whereas relative thresholds are heavily biased by a model’s maximum performance capacity.
Furthermore, leave-one-out trajectory prediction on the 26 composite tasks yields strong performance, with the mean R2 ranging from 0.68 to 0.84 across all 9 models, as recorded in Table 3.
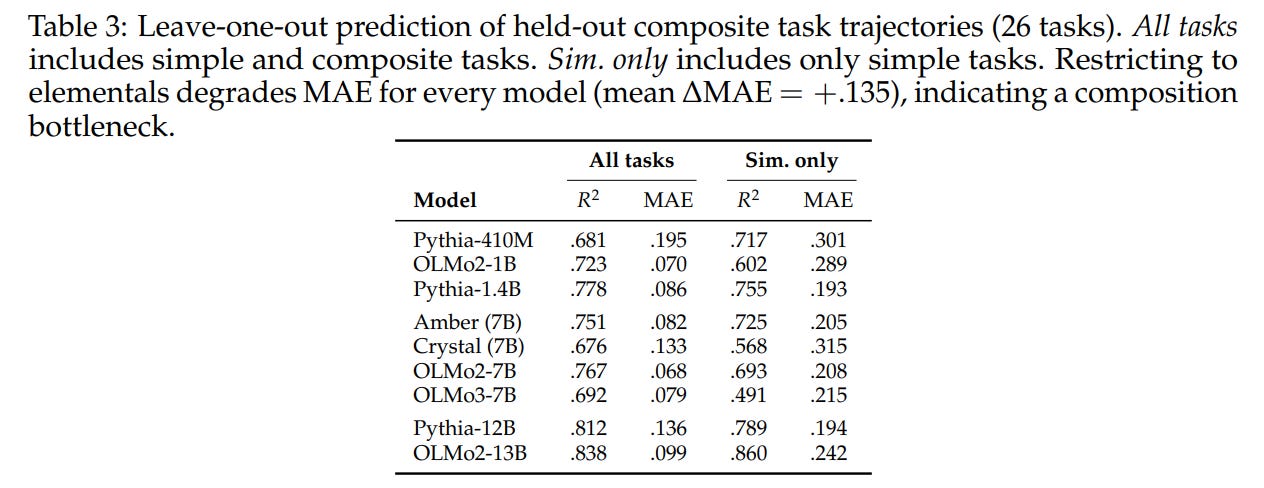
To understand the source of this performance, the authors conducted an ablation study testing the “composition bottleneck.” When restricting the regression basis to elemental tasks only (”Sim. only” in Table 3), prediction accuracy degraded significantly across every single model, leading to a mean increase in Mean Absolute Error of ΔMAE=+0.135. This degradation indicates that composite tasks possess high-order representational structure in the residual stream that is not easily captured by their elemental components alone, suggesting a compositional bottleneck where models must synthesize unique task representation geometry to execute chained operations.
Integrating Mechanics: Quanta, Task Vectors, and Simplicity Bias
This study unifies and extends several distinct lines of research in mechanistic interpretability and learning theory. It builds directly on the Quantization Hypothesis proposed by Michaud et al. (2023), which explains smooth scaling curves through the learning of discrete capabilities. However, while prior work treated these capabilities as independent and required post-hoc, uninterpretable discovery methods, this work establishes that skills emerge in a highly structured, compositional sequence. It leverages the concept of Function Vectors (Todd et al., 2024) and Task Vectors (Hendel et al., 2023) to show that these internal task representation structures can be used as a legible map of training trajectories. Additionally, the observed ordering of simple skills (such as copying and casing) preceding complex logic and arithmetic aligns with gradient-descent Simplicity Bias (Nakkiran et al., 2019) and mirrors post-training curriculum strategies like Skill-it! (Chen et al., 2023b), showing that pretraining implicitly organizes itself along similar compositional pathways.
Unresolved Inversions and the Challenge of Non-Synthetic Complexity
Despite its rigorous empirical backing, this framework faces key challenges. First, the consistency of the emergence ordering depends heavily on utilizing absolute thresholds, which require prior task calibration and cannot easily adapt to changing task formats.
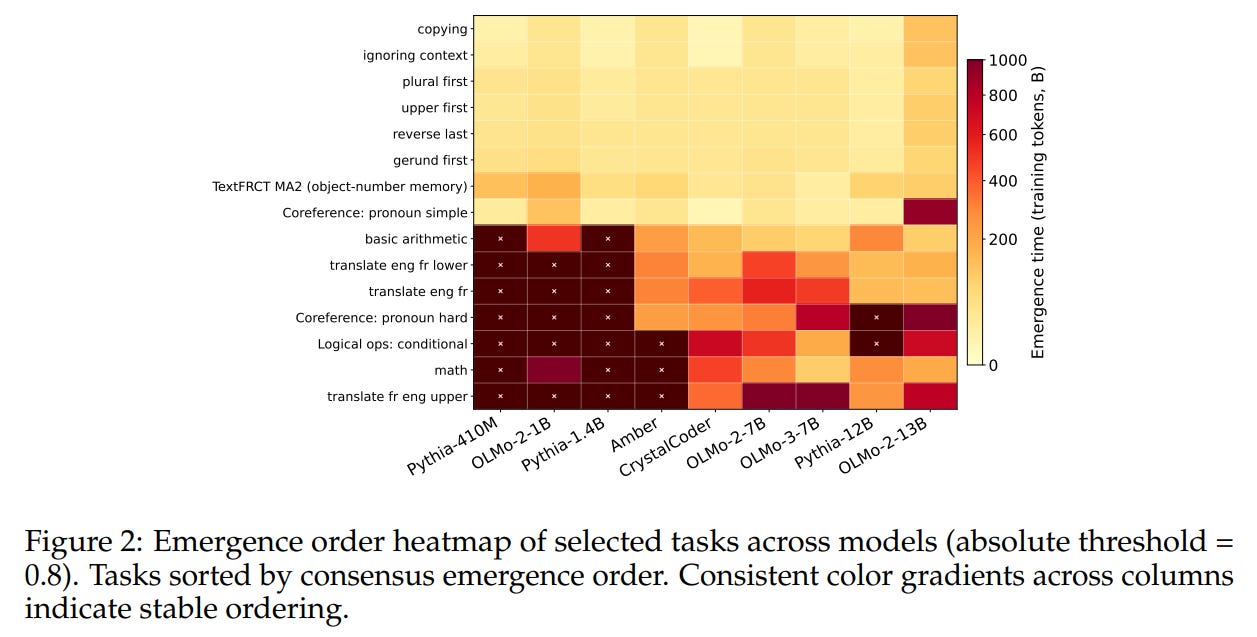
Second, the evaluation is performed on relatively simple, synthetic, and rule-based tasks (e.g., string operations, basic arithmetic) where compositional boundaries are artificially defined. It remains an open question whether highly complex, fuzzy, or non-linear real-world reasoning tasks can be cleanly decomposed into directed acyclic graphs. Furthermore, the authors observe a small number of “task inversions” where a composite task appears to emerge prior to one or both of its designated elemental prerequisites. Most notably, all three strong inversions involved the first_letter component task, suggesting that models may occasionally bypass designed prerequisite structures by learning shortcut heuristics or alternative token-retrieval mechanisms.
Paradigm Shift: Reading the Future from Representational Geometry
This research marks a significant step forward in pretraining transparency and safety diagnostics. By demonstrating that the developmental progression of capabilities is highly structured and encoded directly in internal activations, this work moves us away from treating neural networks as opaque, black-box optimizers. From a practical standpoint, the stability of the implicit curriculum allows engineering teams to construct standardized, lightweight diagnostic suites to actively monitor large-scale training runs, verifying if model capabilities are emerging on-schedule long before expensive training runs conclude. On a theoretical level, the ability to predict future, out-of-distribution training trajectories solely from the geometric proximity of function vectors suggests that a model’s representation space contains a legible map of its future developmental path, paving the way for advanced techniques to predict, optimize, and steer what language models learn.