
When Models Manipulate Manifolds: The Geometry of a Counting Task
Authors: Wes Gurnee, Emmanuel Ameisen, Isaac Kauvar, Julius Tarng, Adam Pearce, Chris Olah, Joshua Batson
Paper: https://arxiv.org/abs/2601.04480
Transformer Circuits: https://transformer-circuits.pub/2025/linebreaks/index.html
Code: N/A
Model: Claude 3.5 Haiku
Affiliation: Anthropic

TL;DR
WHAT was done? The authors successfully reverse-engineered the mechanistic circuitry responsible for line-wrapping in Claude 3.5 Haiku. They demonstrate that the model does not rely on integer registers to track line length; instead, it constructs a “character count manifold”—a spiraling geometric structure embedded in the residual stream. By manipulating the curvature and rotation of this manifold via attention heads, the model performs precise arithmetic operations to determine when to insert a newline.
WHY it matters? This work provides a concrete bridge between feature-based interpretability (sparse dictionaries) and geometric interpretability (manifolds). It reveals that tasks we consider “arithmetic” (counting, subtraction) are implemented in Transformers through “geometric” operations (rotation, projection) on low-dimensional curves. This challenges the notion that neural networks struggle with precise counting by showing they simply adopt a different, continuous mathematical substrate to solve the problem.
Details
The Perception Gap: Tokens vs. Characters
The task of linebreaking offers a unique window into the sensory processing of Large Language Models because it forces a confrontation between the model’s input modality and the task requirements. A Transformer receives a sequence of token IDs (integers), yet linebreaking requires precise knowledge of the character length of those tokens—a visual property abstracted away by the tokenizer. To correctly break a line at a fixed width (e.g., 50 characters), the model must reconstruct character counts from token embeddings, accumulate them, and compare the running total against an implicit limit.
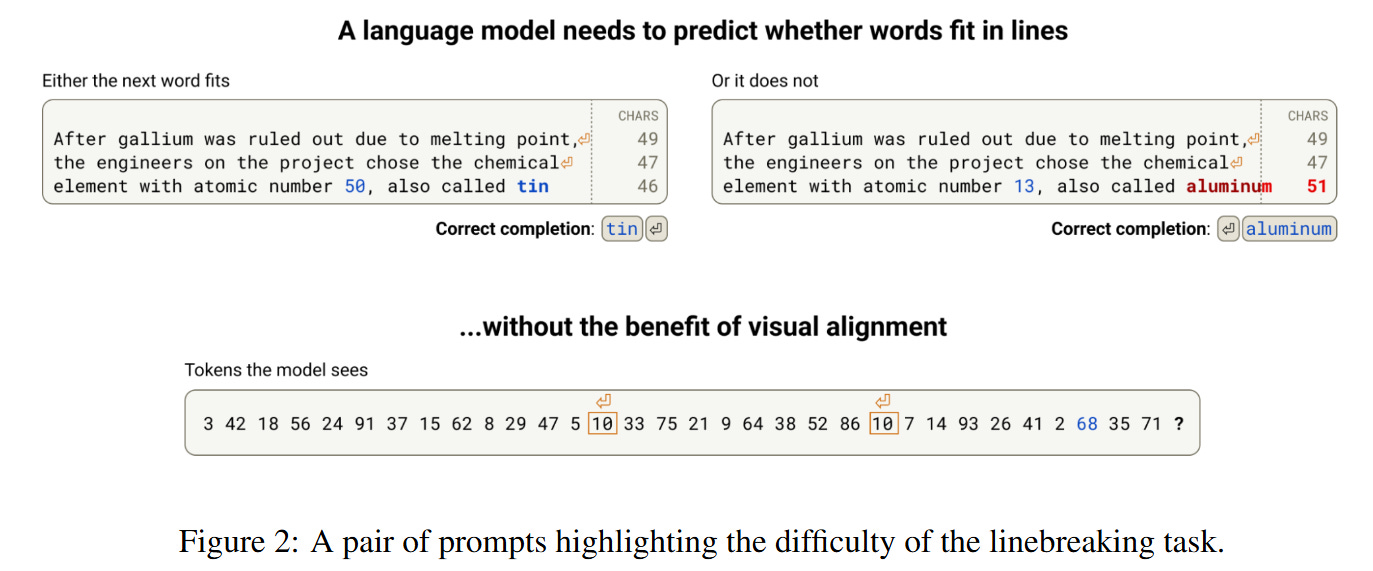
Previous work has identified that models possess “quanta” of capability for this task, but the mechanism remained opaque. The authors analyze Claude 3.5 Haiku and identify a sophisticated circuit that solves this not by counting integers 1,2,3…, but by navigating a continuous geometric space. The model treats position not as a discrete index, but as a location on a curve, allowing it to utilize linear algebra operations—specifically rotations in the Query-Key (QK) circuits—to perform the necessary comparison operators required for the decision boundary.
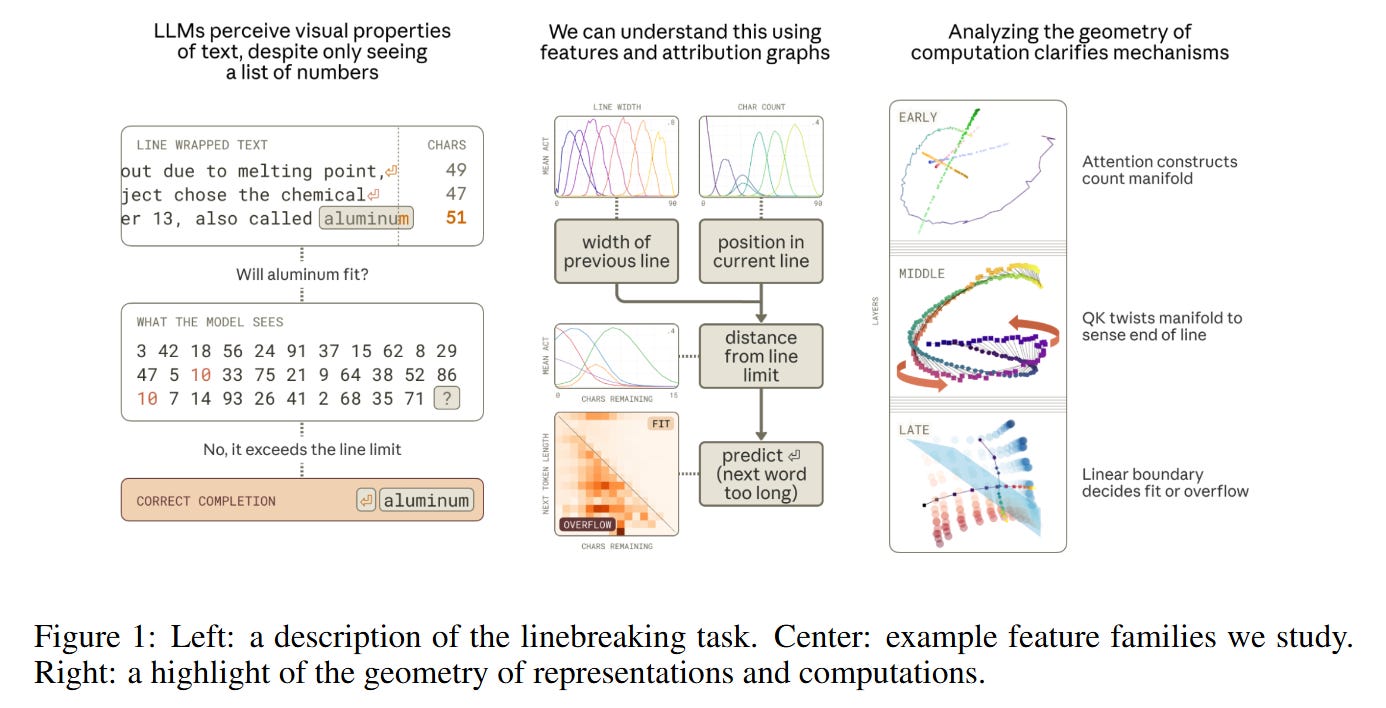
The Character Count Manifold
The core theoretical object discovered in this paper is the Character Count Manifold. If one were designing this system manually, one might allocate orthogonal dimensions for each integer count (e1,e2,…,eN). However, this is inefficient for high N. Conversely, compressing the count into a single scalar magnitude (like a thermometer) lacks the resolution required to distinguish 41 from 42 amidst high-dimensional noise.
Instead, the model learns a compromise: it embeds the scalar count c onto a 1D curve that “spirals” or “ripples” through a low-dimensional subspace (specifically, a 6-dimensional subspace captures 95% of the variance). The geometry of this curve is reminiscent of a helix. As shown in Figure 6, the manifold twists through space, allowing points that are far apart in sequence to be orthogonal, while maintaining local continuity.

A critical mathematical property of this embedding is “ringing.” When analyzing the cosine similarity between the representation of count i and count j, the plot resembles a sinc function (sin(x)/x). The authors demonstrate via a physical simulation that this rippled structure is actually the optimal solution for packing a sequence of vectors into low dimensions such that neighbors are similar and distant points are orthogonal. This suggests the “ripples” seen in positional embeddings in earlier models (like GPT-2) were not artifacts, but optimal packing strategies for continuous variables.
Arithmetic via Geometric Rotation
The most striking mechanistic insight is how the model compares the current count to the line limit. To detect if a line break is needed, the model must compute if current_count≈line_limit. In a standard programming language, this is a subtraction. In the residual stream, the authors find that specific “Boundary Heads” perform this comparison using geometric rotation.
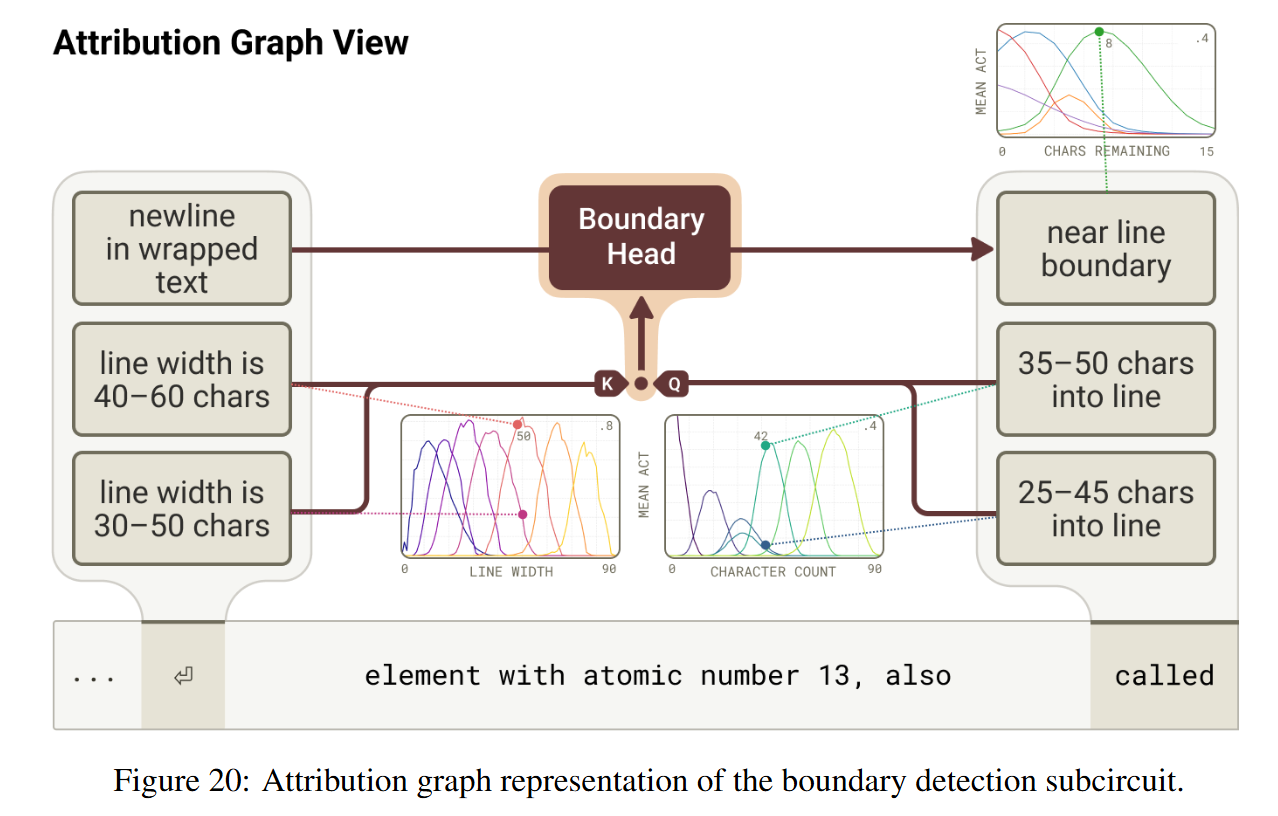
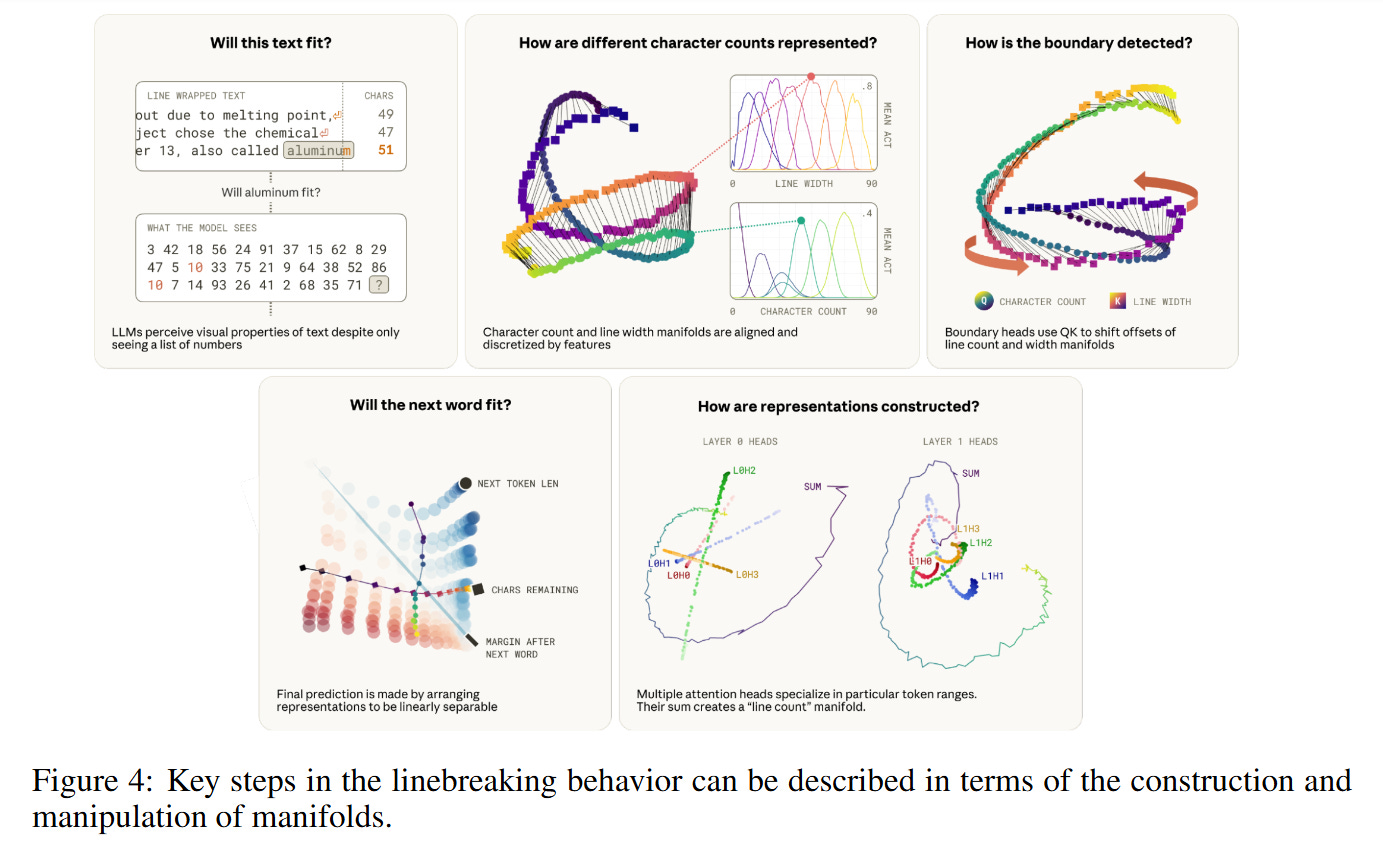
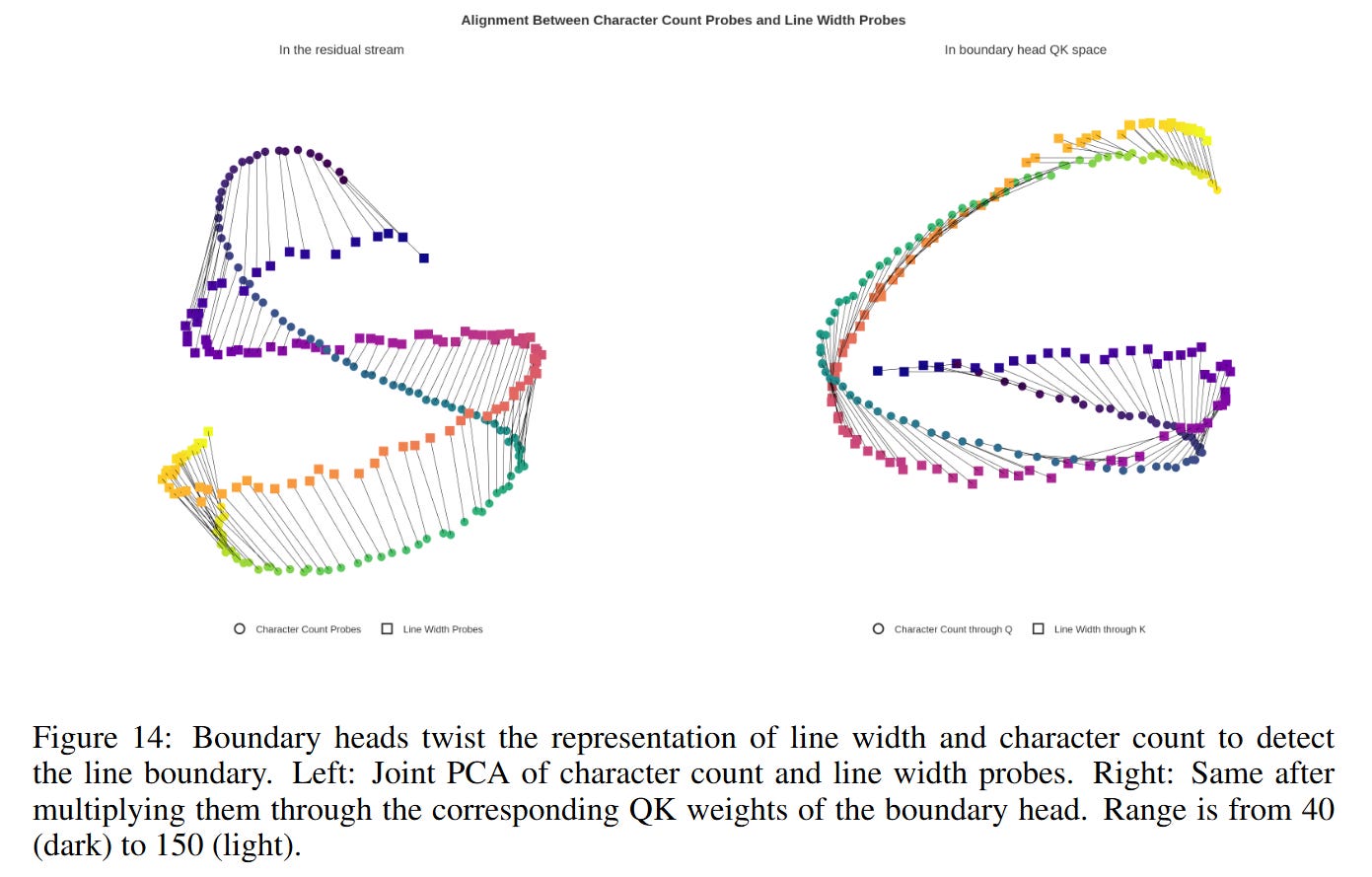
The attention mechanism computes inner products between queries and keys: score=xQTWQKTWQKxK. The authors visualize this interaction and find that the WQK matrix effectively “twists” the character count manifold. Specifically, the head rotates the manifold such that the vector for character count i aligns with the vector for line width k when i≈k−ϵ. This turns a subtraction problem into an alignment problem: the attention score peaks when the rotated “current position” vector overlaps with the “line limit” vector. This allows the model to attend to the newline token exactly when the remaining space in the line is critically low, as illustrated in the QK probe visualizations in Figure 14.
A Distributed Counting Algorithm
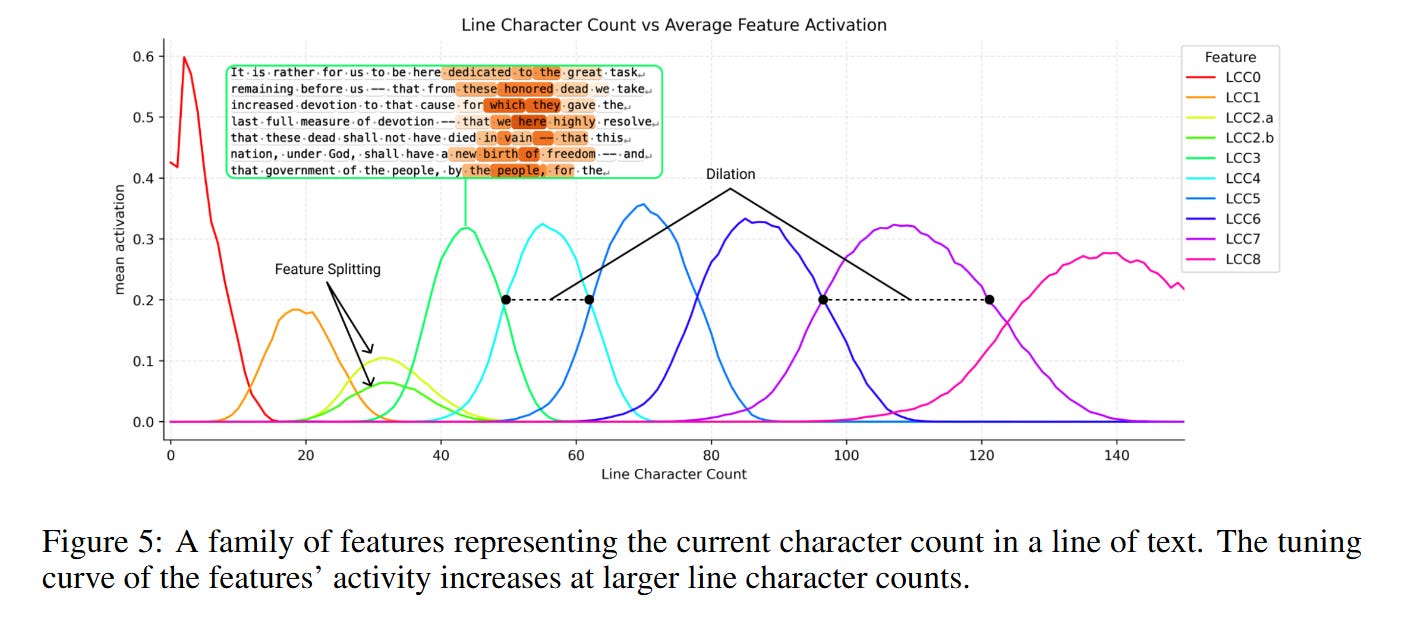
The construction of this manifold is not the work of a single component but a distributed algorithm across layers. The review reveals a “stereoscopic” approach to counting. Layer 0 attention heads act as the primary sensors; they attend to the previous newline token (treating it as an “attention sink”) and output vectors that roughly approximate the distance from that sink. However, a single head cannot provide the necessary resolution across the entire 0-150 character range due to the “softmax bottleneck”—it cannot be sharp everywhere.
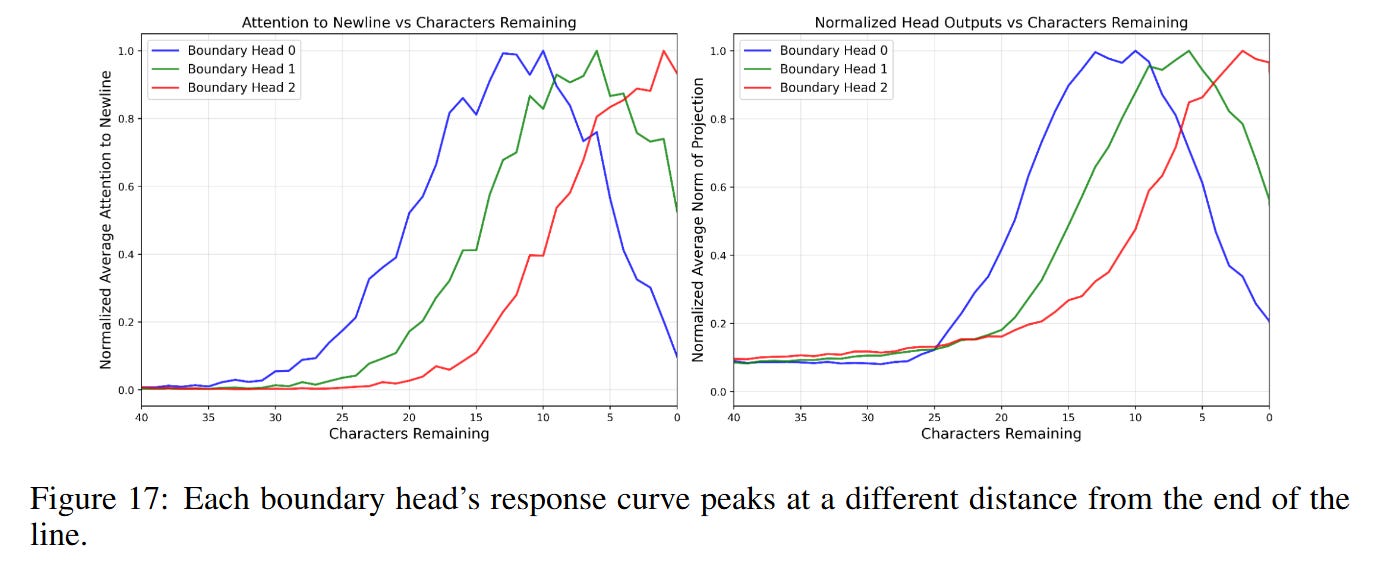
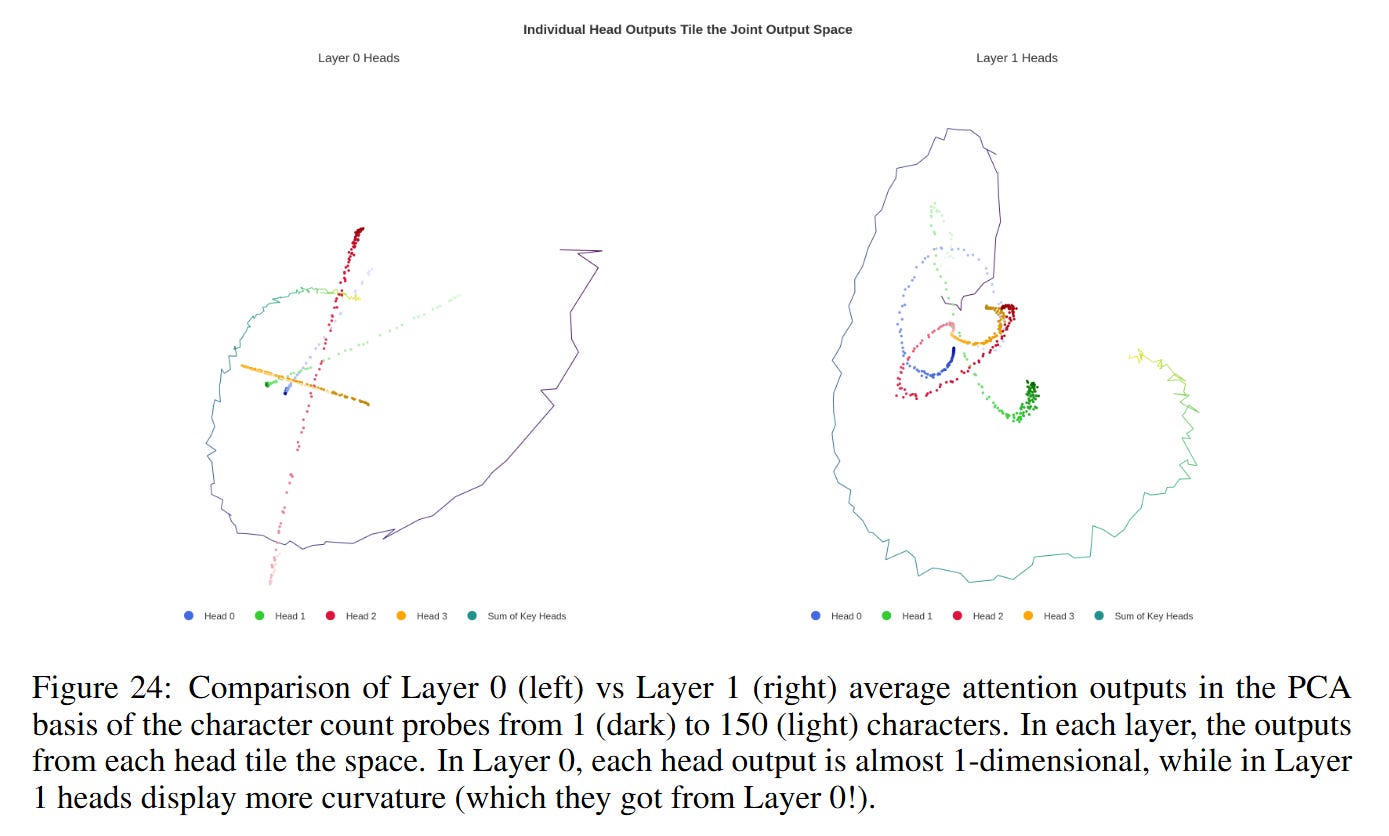
Consequently, the model utilizes a choir of heads with different receptive field offsets. As shown in Figure 24, Layer 0 heads produce relatively straight “rays” in the principal component space. Layer 1 heads then aggregate these inputs to construct the high-curvature, helical structure of the mature manifold. This layering sharpens the resolution, allowing the model to distinguish between 49 and 50 characters—a necessary precision for the binary decision of whether to break a line.
Adversarial Geometry: Visual Illusions in Text
To validate that these geometric structures are causal and not merely correlative, the authors introduce a set of “visual illusions” for text. They hypothesized that since the counting relies on attention heads tracking back to specific “anchor” tokens (like newlines), introducing distractor tokens that mimic these anchors could hijack the mechanism.
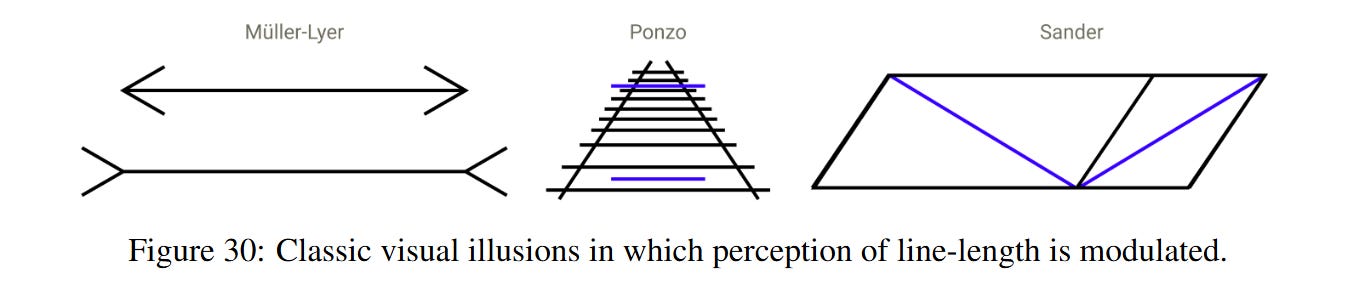
They found that inserting specific character sequences, such as @@ (often used as delimiters in code/git diffs), causes the counting heads to misattribute the start of the line. This effectively resets or shifts the model’s internal “odometer,” causing it to miscount the line length and fail to break the line at the correct position (Figure 31). This parallels optical illusions in biological vision, where contextual cues (like arrows in the Müller-Lyer illusion) distort the perception of length. This failure mode provides strong evidence that the geometric mechanism described is indeed the one driving the model’s behavior.

Connection to Biological and Synthetic Models
The representations uncovered here bear a striking resemblance to biological neural circuits. The “character count features”—sparse features that activate for specific ranges of counts (e.g., 35-45 characters)—are analogous to place cells in the mammalian hippocampus. Similarly, the “boundary detecting features” behave like boundary cells that fire at specific distances from environmental walls.
Furthermore, this work connects deeply with recent theoretical work on Feature Manifolds by Modell et al. It reinforces the duality of interpretability: the system can be viewed as discrete features (sparse autoencoder latents) or as continuous geometric transformations. The authors argue that while the discrete view is helpful for cataloging, the geometric view is often more parsimonious for tasks involving continuous variables like position and magnitude.
The Complexity Tax
Despite the elegance of the manifold description, the authors note a “Complexity Tax.” Discovering these manifolds required significant manual effort and hypothesis testing. While sparse dictionary learning (using Crosscoders in this case) automatically surfaced the relevant features, stitching them together into a coherent geometric narrative was not automated. The field currently lacks unsupervised methods that can automatically detect that a cluster of 100 discrete features actually represents a discretized helix. Bridging this gap—automating the discovery of geometric primitives—remains a critical open problem.
Strategic Implications
This paper moves the needle on our understanding of how Transformers handle arithmetic and logic. It suggests that we should stop looking for “registers” and “ALUs” in the traditional Von Neumann sense. Instead, Transformers solve logic problems by embedding discrete states onto continuous manifolds and performing linear-algebraic manipulations (rotations, reflections) to execute operations. For AI researchers, this implies that the “reasoning” capabilities of future models might be best optimized by architectures that explicitly support or regularize these specific types of high-dimensional geometric manipulations.
Great analysis, which I am still digesting, but "a visual property abstracted away by the tokenizer." isn't quite right. At least if the tokens are composed of UTF-8 encoded characters. Do you mean base characters, which take combining characters? Being mindful that all Unicode text is "written" from left to right, even if displayed right to left, placing the line breaks at the right margin. See: https://www.unicode.org/versions/Unicode17.0.0/core-spec/
If a transformer knew the character rules for Unicode characters, could it be instructed to use those rules, including the language-specific ones?
Line breaks are complicated but extensively covered by both literature and code (TeX is only one example). So if the Anthropic model is "learning," why didn't it choose some known method for performing line breaks?