Authors: Bohan Hou, Gen Li, Jindou Jia, Tuo An, Xinying Guo, Sicong Leng, Haoran Geng, Yanjie Ze, Tatsuya Harada, Philip Torr, Oier Mees, Marc Pollefeys, Zhuang Liu, Jiajun Wu, Pieter Abbeel, Jitendra Malik, Yilun Du, Jianfei Yang
Paper: https://arxiv.org/abs/2605.00080v1
Site: https://ntumars.github.io/wm-robot-survey/
Code: https://github.com/NTUMARS/Awesome-World-Model-for-Robotics-Policy
TL;DR
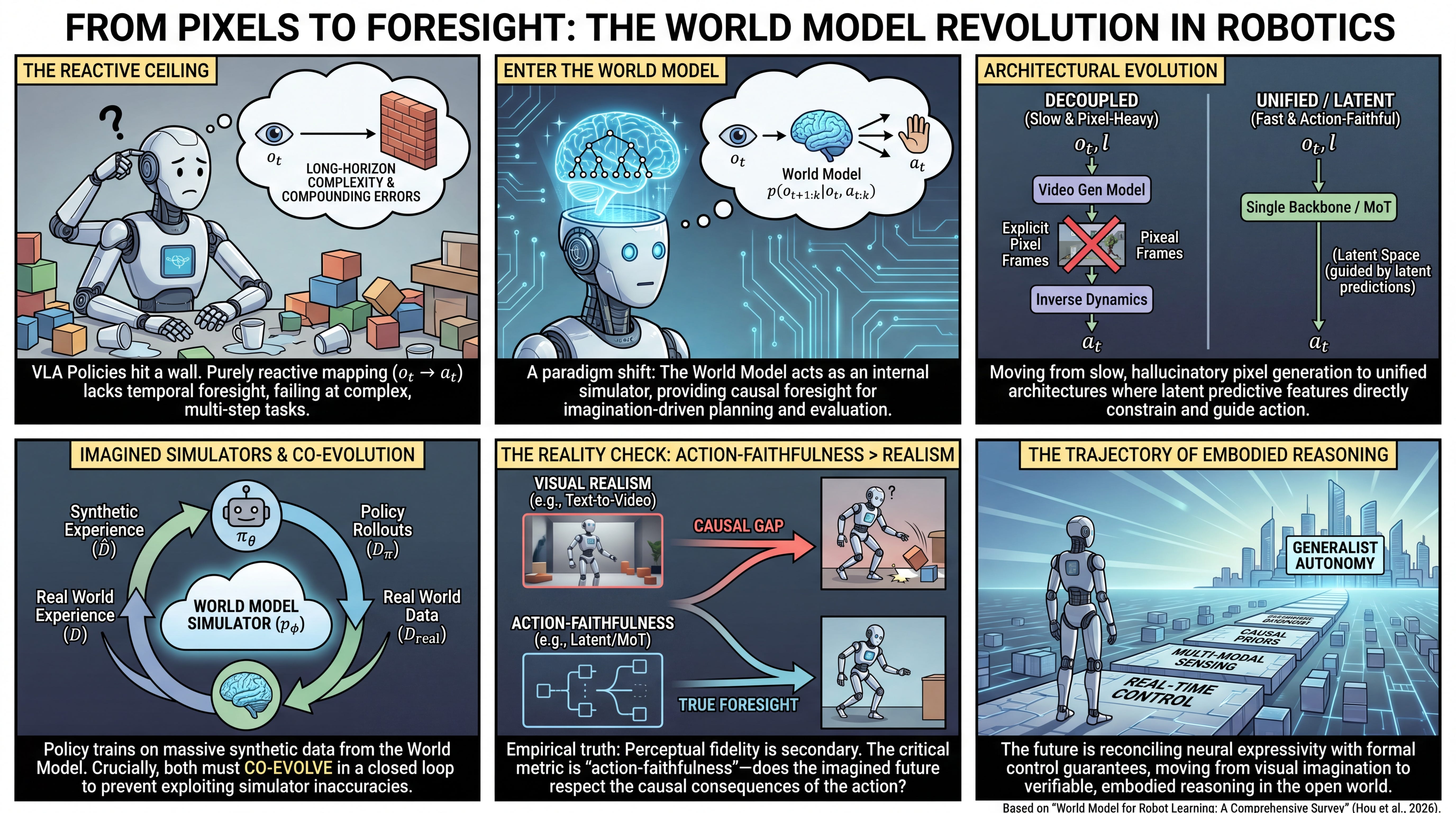
WHAT was done? This paper provides a comprehensive, policy-centric taxonomy of how world models are integrated into robotic learning. It systematically categorizes the field across architectural paradigms (from decoupled pipelines to unified single-backbones) and functional roles (from passive video predictors to interactive reinforcement learning simulators), with a specific emphasis on the emergence of Multimodal Large Language Models (MLLMs) as internal dynamics engines.
WHY it matters? Purely reactive Vision-Language-Action (VLA) models are reaching a performance ceiling in long-horizon reasoning and robustness against compounding errors. By injecting explicit predictive structures, world models—particularly those internalizing "what happens next" logic within MLLM transformer layers—provide the necessary causal foresight, physical grounding, and synthetic data amplification required to push embodied intelligence toward reliable, closed-loop deployment in complex real-world environments.
Executive summary: The survey fundamentally redefines the utility of world models in robotics. It argues that perceptual realism is secondary to action-conditioned consistency and functional utility. By unifying disparate modeling architectures under a shared probabilistic framework, the authors map out a strategic transition: we are moving away from isolated video generation models toward internalized cognitive substrates that allow robots to imagine, plan, and self-correct before committing to physical action.
Details
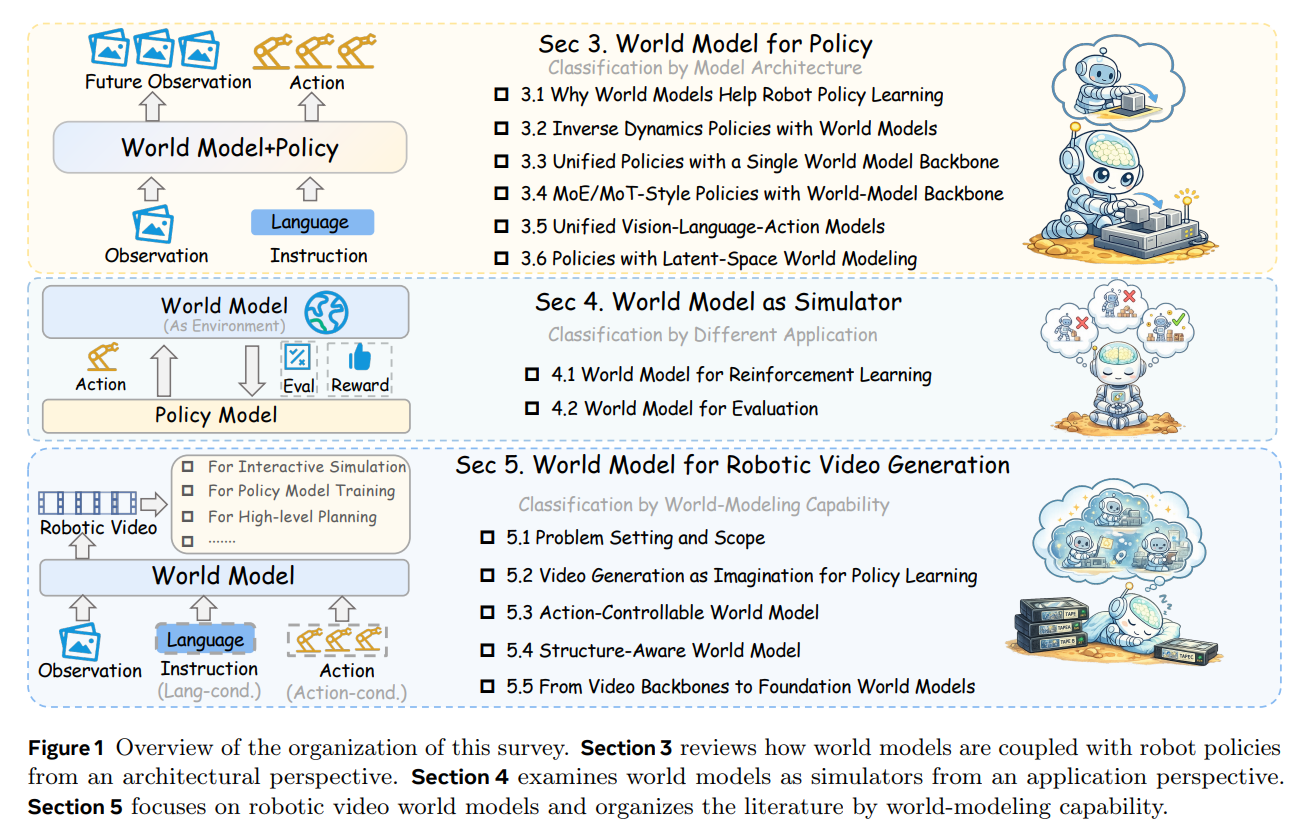
The Reactive Ceiling in Embodied Control
The rapid scaling of Vision-Language-Action (VLA) models, increasingly powered by Multimodal Large Language Model (MLLM) backbones, has undeniably advanced cross-task generalization in embodied agents. However, as these policies encounter increasingly complex physical environments, a structural bottleneck emerges: purely reactive policies map current observations directly to immediate actions. This limits their capacity for temporal credit assignment and leaves them highly vulnerable to compounding execution errors over extended time horizons. The surveyed literature suggests that overcoming this barrier requires a transition from purely reactive mappings to predictive structures. By incorporating world models, agents gain the ability to anticipate how the environment will evolve under specific interventions, providing a physically grounded foundation for imagination-driven planning and targeted policy refinement. As illustrated in Figure 1, world models are no longer peripheral visualization tools; they are becoming the central simulator and evaluation engine for robotic decision-making.