
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Go DeepSeek!
Authors: Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, Wenfeng Liang
Paper: https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
Code: https://github.com/deepseek-ai/Engram
TL;DR
WHAT was done? The authors introduce Engram, a “conditional memory” module that injects massive, static N-gram embedding tables into Transformer layers. By decoupling knowledge storage from neural computation, they formulate a Sparsity Allocation law, demonstrating that replacing roughly 20% of Mixture-of-Experts (MoE) parameters with these hash-based lookups significantly improves performance across reasoning and knowledge tasks.
WHY it matters? This work challenges the “all-neural” paradigm of LLMs. It proves that specialized lookups are more efficient than attention for static patterns (entities, idioms), effectively “deepening” the network and freeing up attention heads for complex reasoning. Furthermore, because retrieval indices are deterministic, the memory tables can be offloaded to CPU RAM with negligible latency, offering a path to scale models far beyond GPU HBM limits.
Another recent interesting approach with trading computation for memory was described here.

Details
The Simulation Bottleneck
The prevailing scaling paradigm for Large Language Models relies heavily on Conditional Computation, primarily realized through Mixture-of-Experts (MoE) architectures like DeepSeekMoE. While MoE scales capacity by activating only a subset of parameters per token, it still forces the network to simulate memory retrieval through expensive floating-point operations. When a model encounters a static entity like “Diana, Princess of Wales,” it typically consumes multiple layers of Attention and Feed-Forward Networks (FFNs) just to reconstruct this fixed association. This process is computationally wasteful; it utilizes deep, dynamic logic circuits to perform what is essentially a static hash map lookup. The authors argue that language modeling entails two distinct sub-tasks: compositional reasoning (which requires depth) and knowledge retrieval (which requires capacity). Standard Transformers lack a native primitive for the latter, creating a structural inefficiency where “neural RAM” is simulated by “neural CPU.”

Engram First Principles: Conditional Memory
To address this duality, the paper proposes Conditional Memory as a complementary axis of sparsity. The core theoretical object here is the Engram, a module designed to handle the “knowledge retrieval” sub-task via O(1) lookups. Unlike standard embedding layers that sit only at the input, Engram modules are inserted deep within the network (e.g., layers 2 and 15). The fundamental assumption is that a significant portion of linguistic signals—named entities, formulaic phrases, and idioms—follows a Zipfian distribution and is sufficiently static to be offloaded to a lookup table.
This requires redefining the vocabulary space. Standard subword tokenizers optimize for reconstruction, often creating disjoint IDs for semantically identical terms (e.g., “Apple” vs. “ apple”). To maximize semantic density for memory retrieval, the authors introduce a surjective function P:V→V′ that collapses raw token IDs into canonical identifiers (normalizing case and spacing). This ensures that the memory key represents the semantic concept rather than the surface form.
The Retrieval and Gating Mechanism
The flow of a single input through the Engram module illustrates the decoupling of memory from logic. Consider the phrase “Alexander the Great”. As the token “Great” is processed at position t, the system first extracts suffix N-grams (e.g., 2-gram “the Great”, 3-gram “Alexander the Great”). Instead of maintaining a distinct embedding for every possible combination—which is combinatorially intractable—the system uses Multi-Head Hashing. The compressed context is mapped to indices via K distinct hash heads, retrieving embeddings et,n,k from a table E. These are concatenated to form a raw memory vector et.

Crucially, raw retrieval is noisy due to potential hash collisions and polysemy. To filter this, the authors implement Context-Aware Gating, effectively using the Transformer’s hidden state as a query filter. As shown in Figure 1, the current hidden state ht serves as the Query, while the retrieved memory et acts as both Key and Value. The system computes a scalar gate αt:
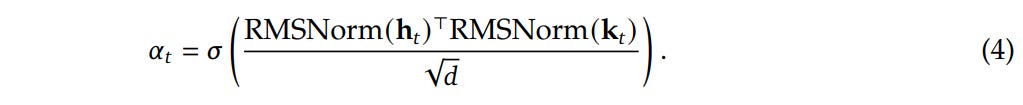
This gate determines if the retrieved memory is relevant to the current semantic context. If the retrieved pattern matches the context accumulated in ht, the gate opens, and the memory is fused into the residual stream. This mechanism allows the model to selectively “listen” to the lookup table only when a valid static pattern (like an idiom or entity) is recognized, suppressing noise from hash collisions.

The U-Shaped Sparsity Allocation Law
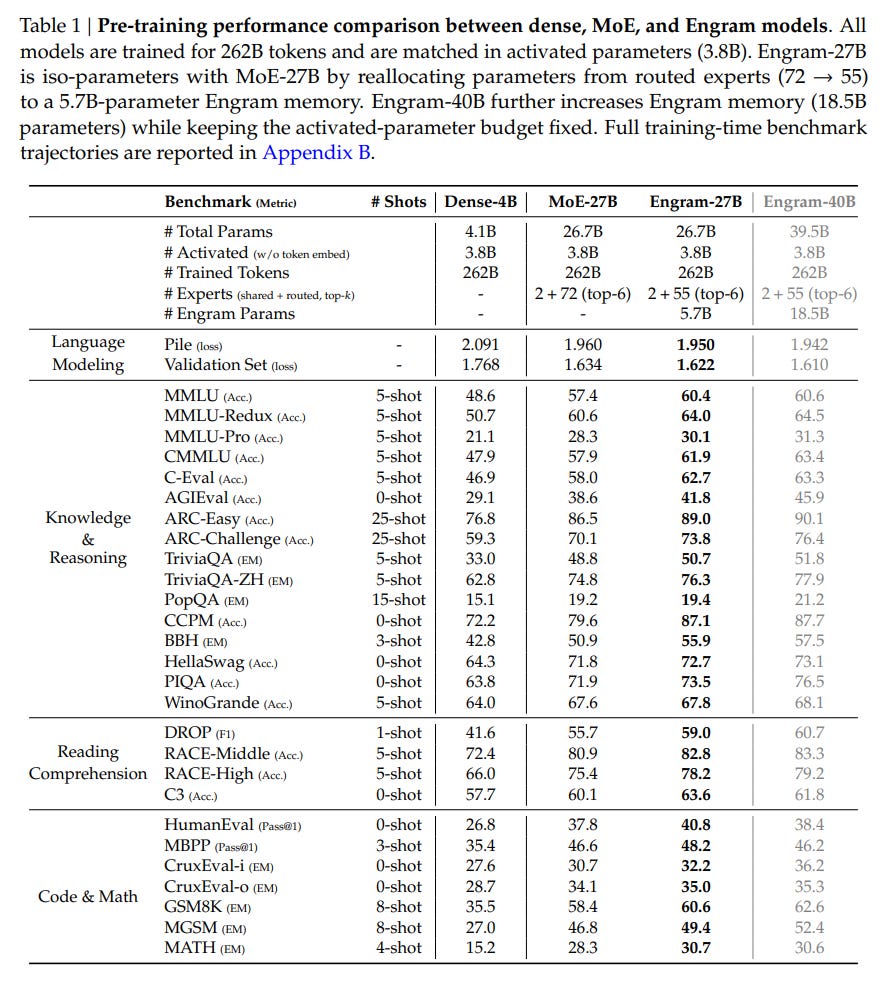
A major contribution of this work is the empirical derivation of the Sparsity Allocation law. The researchers investigated how to divide a fixed budget of “inactive” parameters between MoE experts (conditional computation) and Engram slots (conditional memory). They define the allocation ratio 𝜌 ∈ [0, 1] as the fraction of the inactive parameter budget assigned to MoE expert capacity. Experiments, visualized in Figure 3, revealed a distinct U-shaped curve in validation loss. A pure MoE model (ρ=100%) is suboptimal because it wastes compute on static patterns. Conversely, an Engram-dominated model (ρ→0%) fails because it lacks the dynamic reasoning capacity of neural layers.
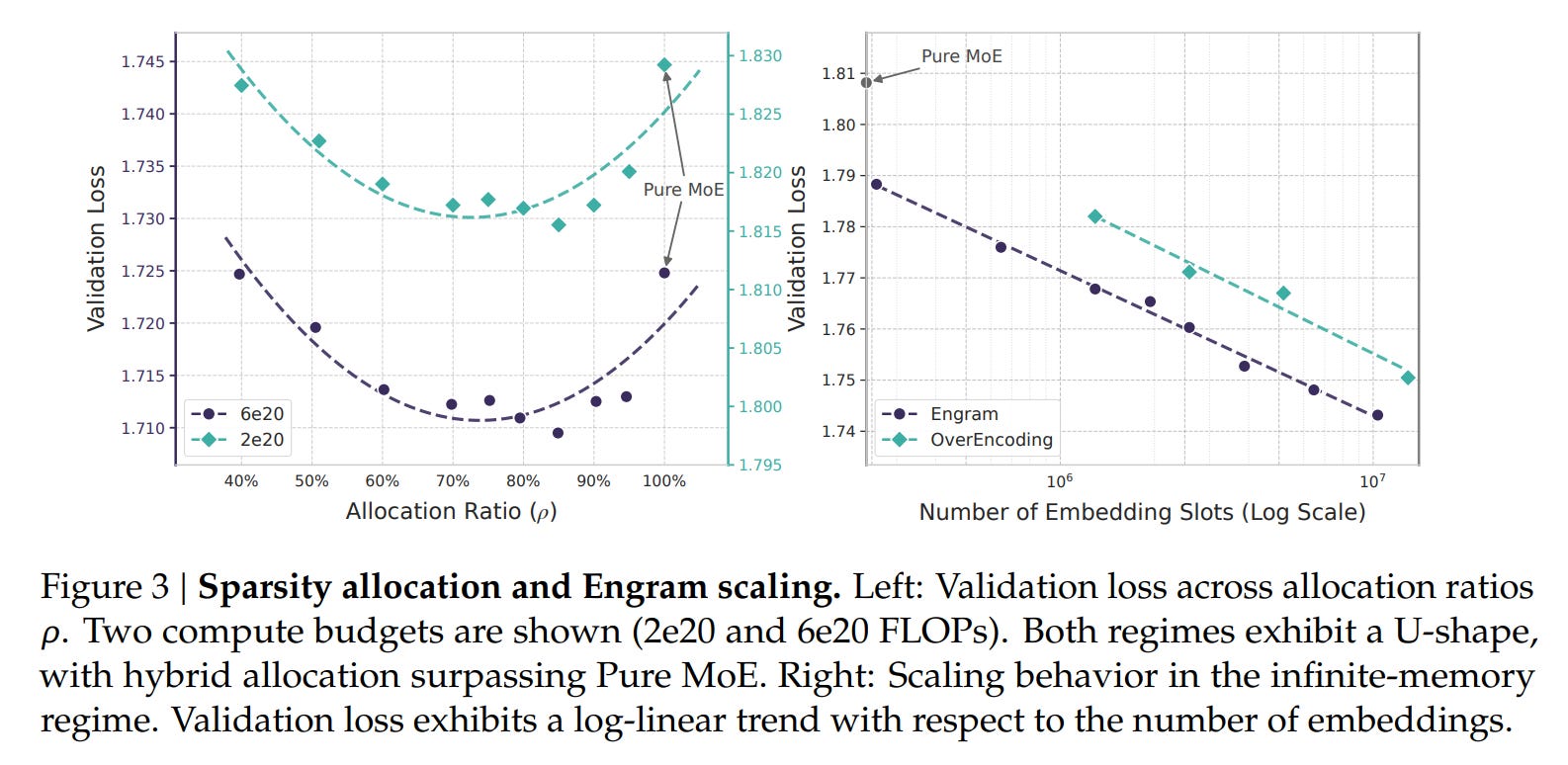
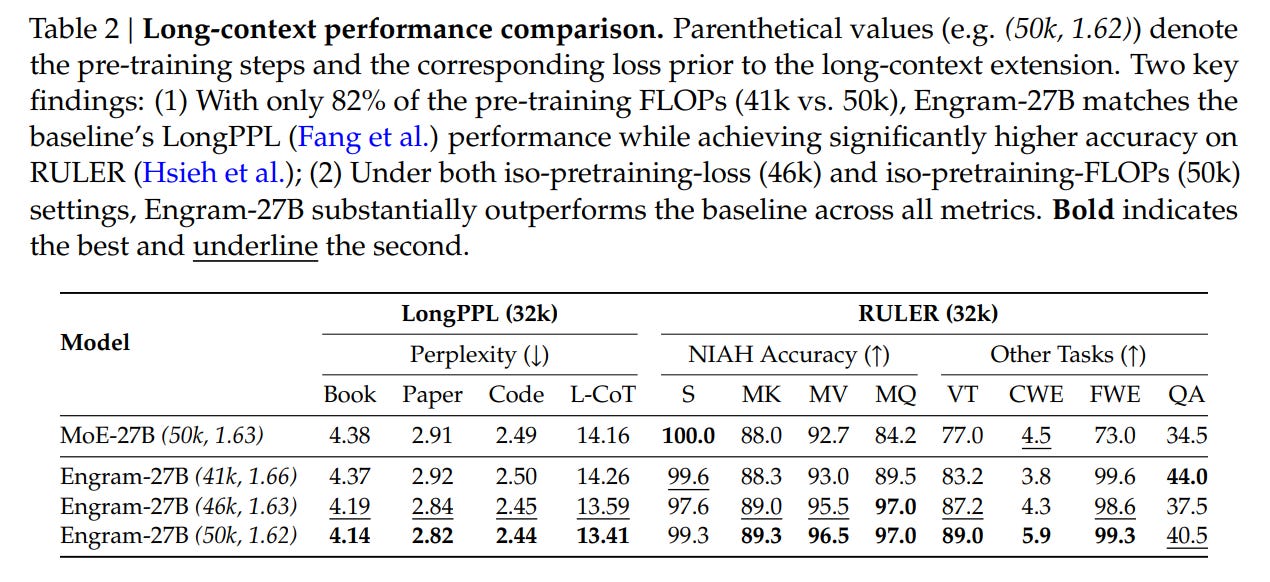
The “sweet spot” appears to be reallocating roughly 20-25% of the sparse parameter budget to Engram. Guided by this law, the authors scaled up to Engram-27B. This model, despite being iso-parameter and iso-FLOPs with a standard MoE-27B baseline, demonstrated superior performance across the board. The implications are non-trivial: adding static memory did not just improve knowledge tasks (MMLU +3.4); it significantly boosted general reasoning (BBH +5.0) and code/math performance (HumanEval +3.0). This suggests that offloading rote memorization to Engram frees up the “neural” capacity of the remaining experts to focus on complex, algorithmic reasoning.
Infrastructure-Aware Efficiency
From a systems engineering perspective, Engram solves a critical bottleneck in deploying massive models: memory bandwidth. In standard MoE, the specific experts required for a token are known only after the gating network computes the route during runtime, making prefetching difficult. In contrast, Engram lookups are deterministic. The indices rely solely on the input token sequence (suffix N-grams), which is known before the forward pass begins.
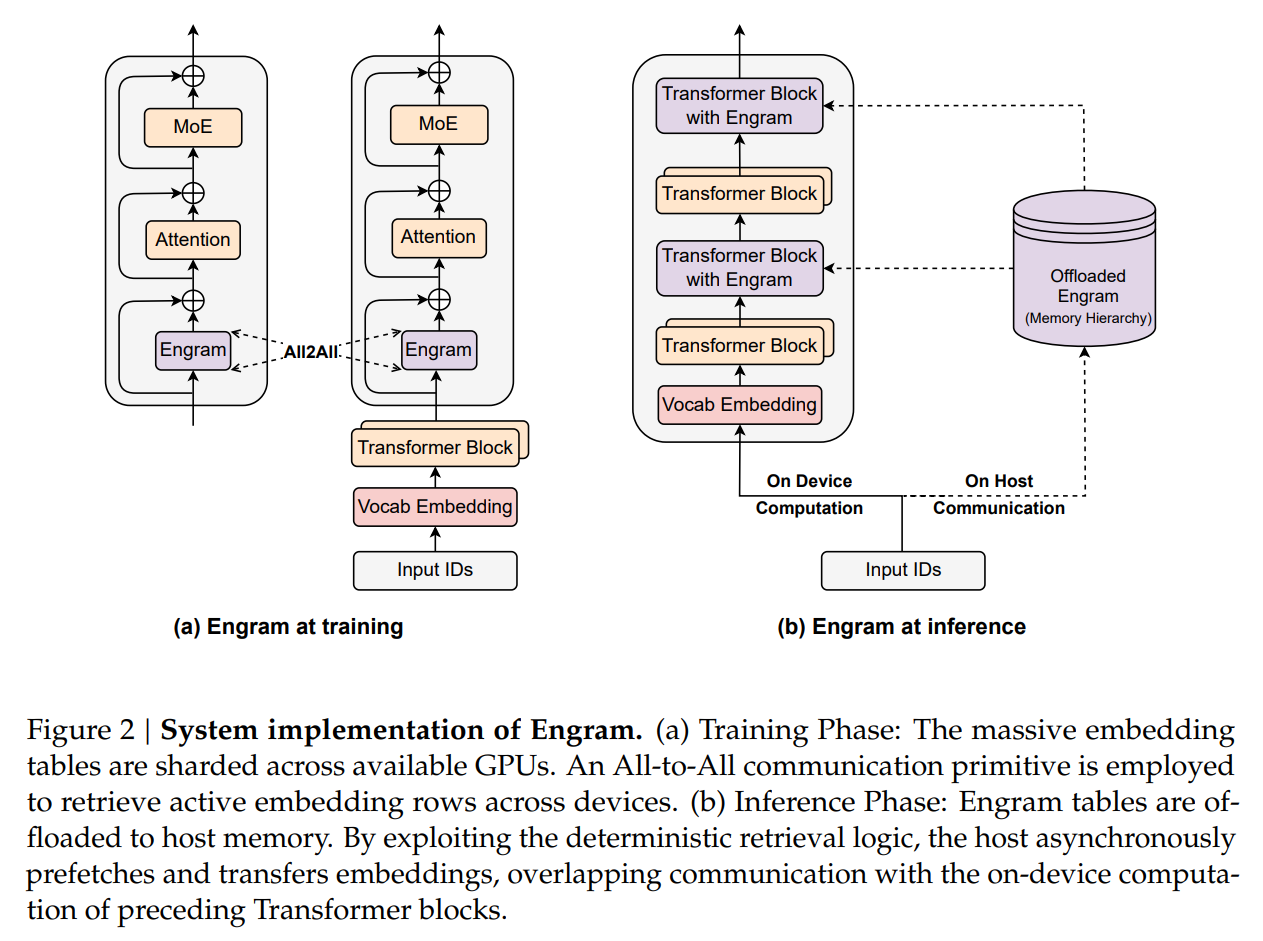
This property enables a Prefetch-and-Overlap strategy. As visualized in Figure 2, the system can prefetch embeddings from Host RAM (CPU memory) via PCIe while the GPU computes the preceding layers. The authors demonstrate that offloading a massive 100B-parameter embedding table to CPU memory incurs negligible inference overhead (<3%). This effectively bypasses the HBM capacity wall, allowing models to scale memory parameters linearly with cheap system RAM rather than expensive GPU clusters.

Analysis: The Source of Performance
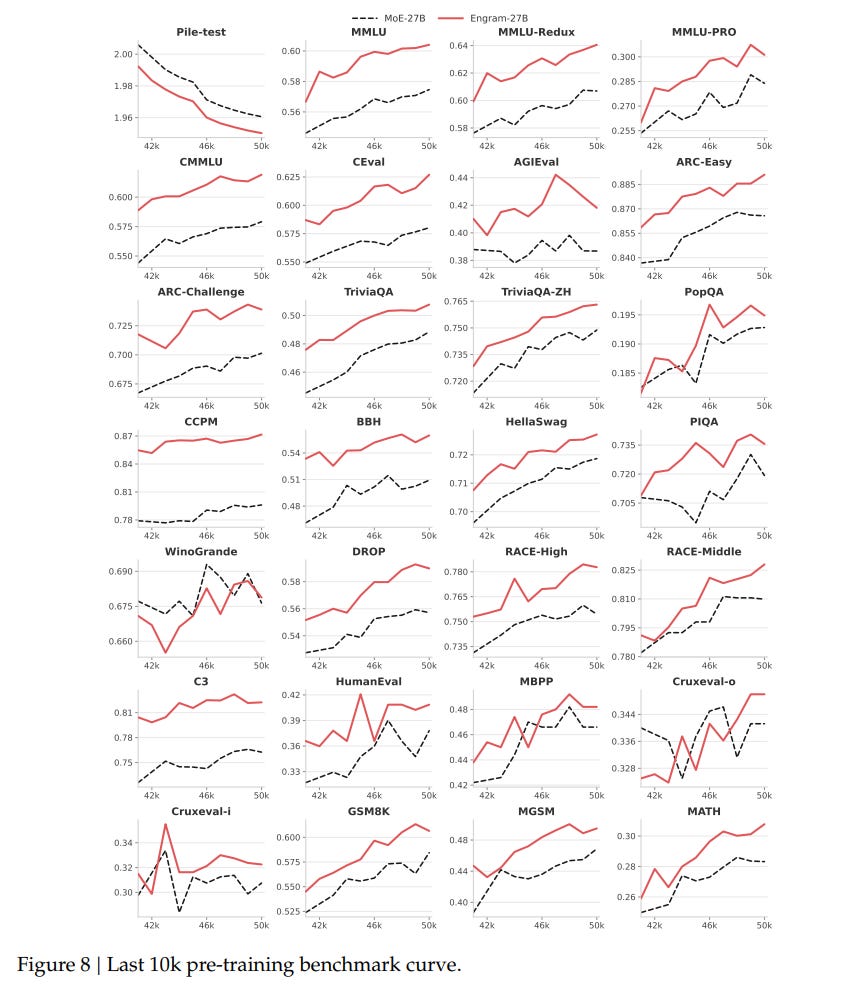
The authors validate the “offloading” hypothesis using LogitLens and Centered Kernel Alignment (CKA). The analysis reveals that Engram layers allow the model to reach “prediction-ready” states much earlier in the network. Effectively, the Engram module acts as a shortcut, relieving the early Transformer layers from the burden of constructing features for static entities. The CKA heatmaps in Figure 4 show that the representations in shallow Engram layers align with much deeper layers of a baseline MoE model.
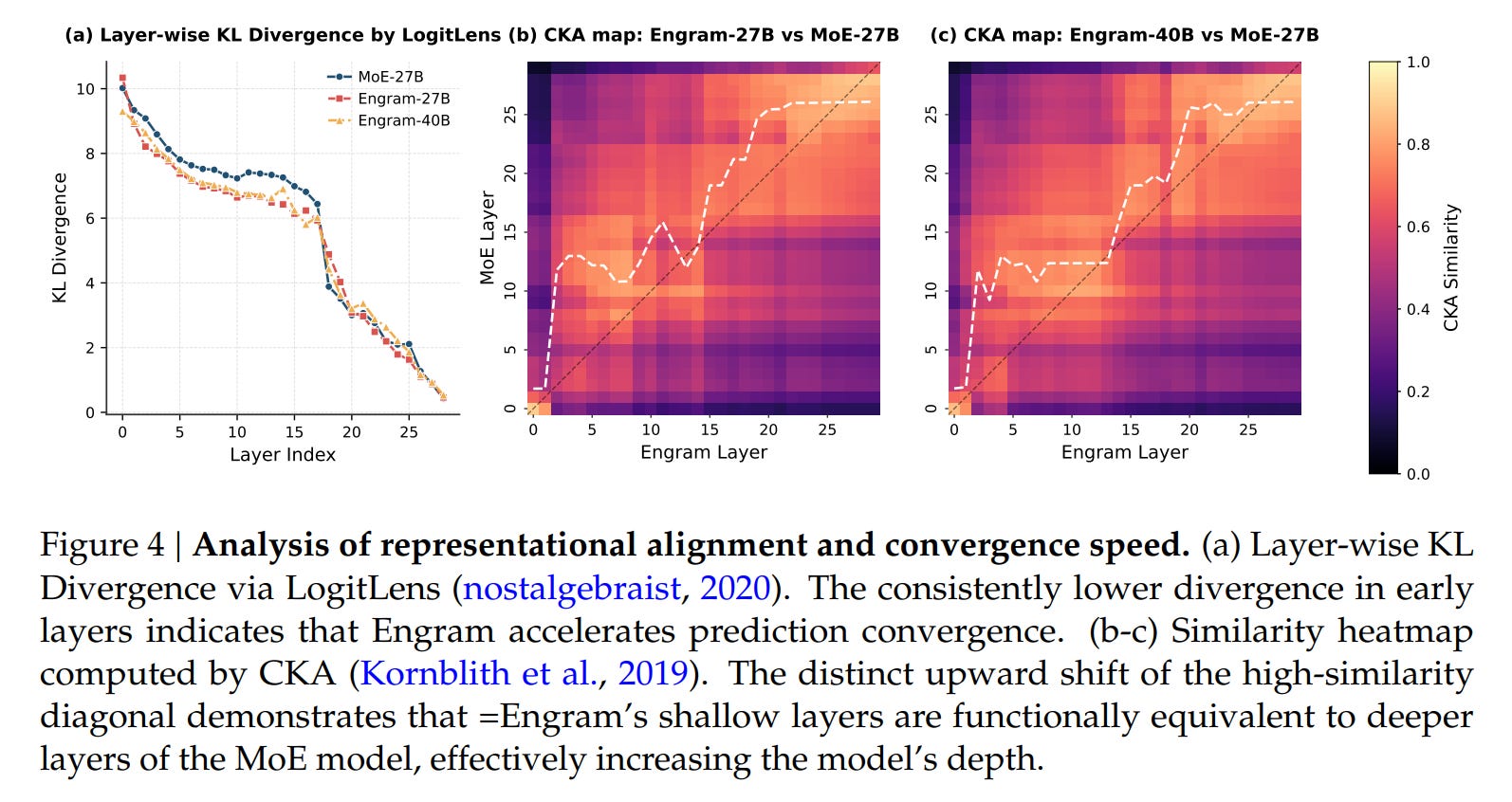
This efficiency dividend is most visible in long-context tasks. By delegating local dependency modeling (e.g., tracking the name “Alexander” appearing near “Great”) to the lookup table, the model’s attention mechanism preserves its capacity for global context. This resulted in drastic improvements in “Needle In A Haystack” benchmarks (Multi-Query NIAH jumping from 84.2 to 97.0), confirming that the architecture successfully separates local pattern matching from global information synthesis.
Limitations
While promising, the Engram approach introduces rigidities inherent to static lookups. The memory is read-only during inference; unlike the working memory in a recurrent state or the dynamic weights of a standard layer, the Engram table cannot adapt to new knowledge without retraining or explicit editing. Furthermore, while the hash-collision noise is mitigated by gating, it introduces a reliance on the model’s ability to filter irrelevant retrievals, which might degrade if the density of collisions increases significantly with table size. The approach also creates a training-inference inconsistency, where the backbone becomes heavily reliant on the presence of the memory module, leading to potential degradation on knowledge tasks if the module acts as a crutch rather than a complement.
Impact & Conclusion
“Conditional Memory via Scalable Lookup” presents a compelling architectural shift, treating memory not as an emergent property of compute, but as a distinct, optimizable primitive. By formalizing the trade-off between MoE experts and static lookups, the authors provide a blueprint for next-generation sparse models that are both smarter (allocating compute to reasoning) and more scalable (allocating memory to host RAM). For researchers at the frontier of scaling, Engram offers a verified method to expand model capacity beyond the physical constraints of GPU clusters.
Really insightful breakdown on decoupling memory from computation. The sparsity allocation curve is fascinating, seems like optimizing that 20% tradeoff between MoE and Engram is where the magic happens. The prefetch strategy for offloading to CPU RAM is clever, makes me think about how we underutilize host memory in modt distributed setups. One question tho, how does this gating mechanism handle adversarial collisions, like if someone deliberately constructs inputs to maximize hash noise?