
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
Authors: Sukjun Hwang, Brandon Wang, Albert Gu
Paper: https://arxiv.org/abs/2507.07955
Code: https://github.com/goombalab/hnet
Model: https://huggingface.co/cartesia-ai
TL;DR
WHAT was done? The authors introduce H-Net, a novel hierarchical network that replaces traditional fixed-vocabulary tokenization with a learned, end-to-end mechanism. If you remember the recent Byte Latent Transformer (BLT), H-Net goes beyond that to being truly end-to-end. At its core is "Dynamic Chunking" (DC), a system that automatically learns to segment raw byte sequences based on content and context. This is achieved through a similarity-based routing module that predicts chunk boundaries and a crucial smoothing module—based on an Exponential Moving Average (EMA)—that makes the discrete chunking process differentiable and stable for training. The architecture is recursive, allowing for multiple stages of hierarchy to learn increasingly complex abstractions.
WHY it matters? This work marks a significant step toward truly end-to-end foundation models, directly addressing a long-standing bottleneck in AI. By learning its own segmentation, H-Net not only outperforms strong BPE-tokenized Transformers on standard benchmarks but also scales more effectively with data (Figure 3). It demonstrates dramatically improved character-level robustness and superior performance on languages (Chinese, code) and modalities (DNA) where handcrafted tokenization struggles (Table 4, Figure 5, Figure 6). This research provides a powerful, generalizable blueprint for future models that learn more with less preprocessing, a tangible validation of the "bitter lesson" in a critical domain.

Details
The End of Handcrafted Tokens?
For years, the deep learning community has grappled with a persistent, handcrafted bottleneck in an otherwise end-to-end world: tokenization. This stands in contrast to one of AI's most enduring insights, the "bitter lesson", which argues that general-purpose methods that leverage computation ultimately win out over specialized, human-designed features. While algorithms like Byte-Pair Encoding (BPE) (https://arxiv.org/abs/1508.07909) have been indispensable for making large language models computationally tractable, they introduce a host of well-documented issues, from poor character-level understanding to systemic biases against certain languages. This paper presents a compelling vision for a future without these constraints. The authors introduce the Hierarchical Network (H-Net), a novel architecture that learns to segment raw data on the fly, effectively replacing the entire tokenization-LM-detokenization pipeline with a single, elegant, end-to-end model.

The H-Net Methodology: Learning to Chunk
The H-Net architecture is inspired by the U-Net (https://arxiv.org/abs/1505.04597) but is designed for autoregressive sequence modeling (another recent application of the U-Net architecture to get rid of tokenization was in the “From Bytes to Ideas: Language Modeling with Autoregressive U-Nets” paper). It processes data through a hierarchical pipeline: a lightweight encoder processes raw bytes, a powerful main network operates on a compressed representation, and a decoder reconstructs the output. This can be recursively nested to create multi-stage hierarchies, allowing the model to build increasingly abstract representations (Figure 1).

The core innovation is the Dynamic Chunking (DC) mechanism, which consists of several key components:
Routing Module: Instead of using fixed rules, this module predicts chunk boundaries by measuring the cosine similarity between adjacent encoder outputs (Equation 4). The intuition is that significant shifts in meaning often mark natural boundaries, and this can be learned directly from data.

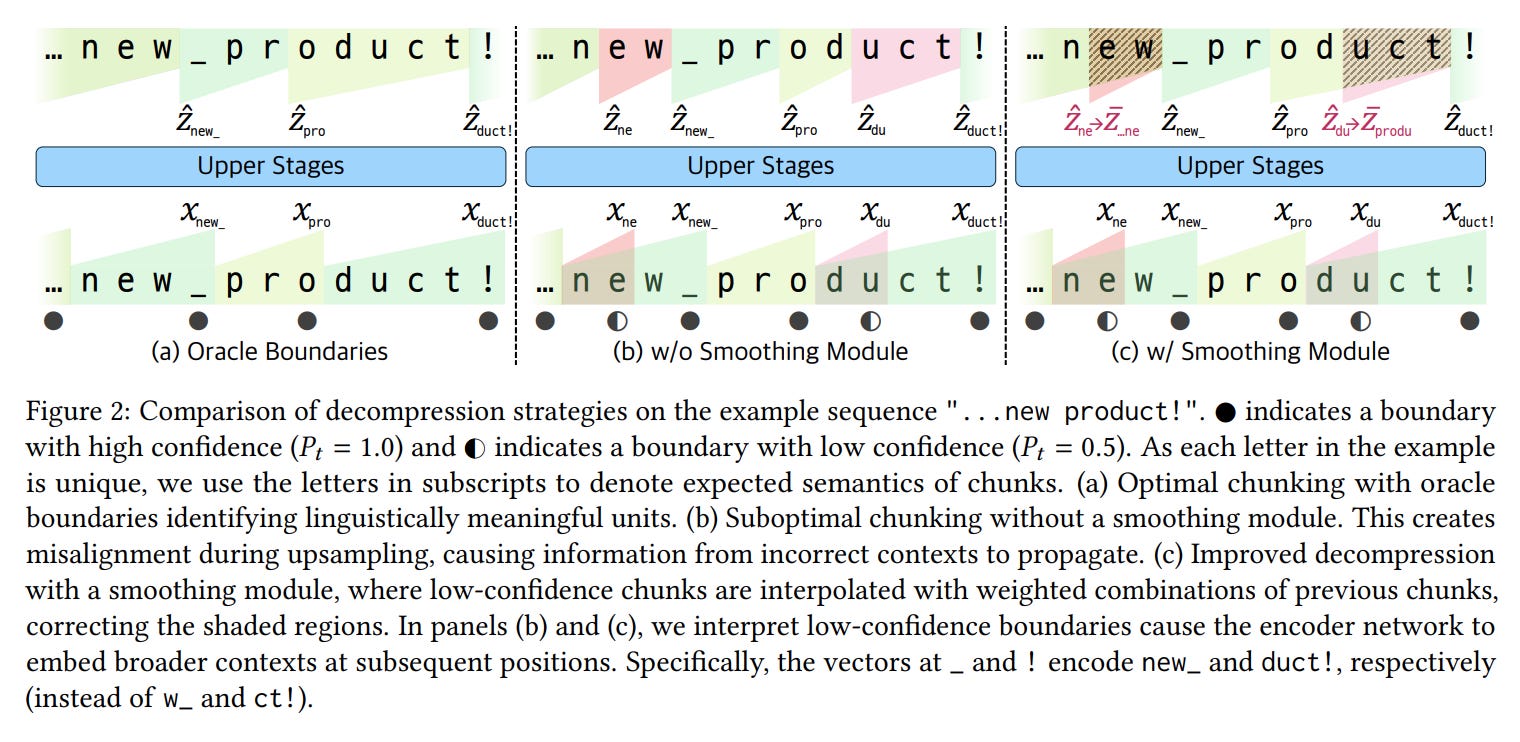
Smoothing Module: This is arguably the most critical technical contribution. Deciding where to place a chunk boundary is a discrete choice, which normally breaks the flow of gradients during backpropagation. The smoothing module transforms this discrete operation into a continuous one by applying a simple but powerful Exponential Moving Average (EMA) to the chunk representations (Equation 5).

This not only enables stable end-to-end training but also allows the model to self-correct: chunks with low-confidence boundaries are automatically "smoothed" by blending them with information from previous chunks, preventing errors from propagating (Figure 2).

Guided Compression: To prevent the model from learning trivial strategies (like chunking every byte or not chunking at all), a novel ratio loss is introduced (Equation 10). This loss function gently guides the model towards a desired compression rate without imposing rigid rules, allowing for content-adaptive compression.

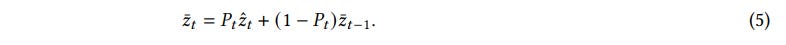

The architectural design is also strategic. The encoder and decoder networks, which handle fine-grained, uncompressed byte sequences, leverage Mamba-2 layers—a type of State Space Model (SSM) (https://arxiv.org/abs/2312.00752) known for its efficiency and strong inductive bias for compression. The main network, which processes the compressed and semantically richer chunks, defaults to a standard Transformer, playing to its strengths.
Scaling, Robustness, and Generalization
The paper's empirical results are thorough and impressive, demonstrating that H-Net is not just a theoretical novelty but a high-performing architecture.

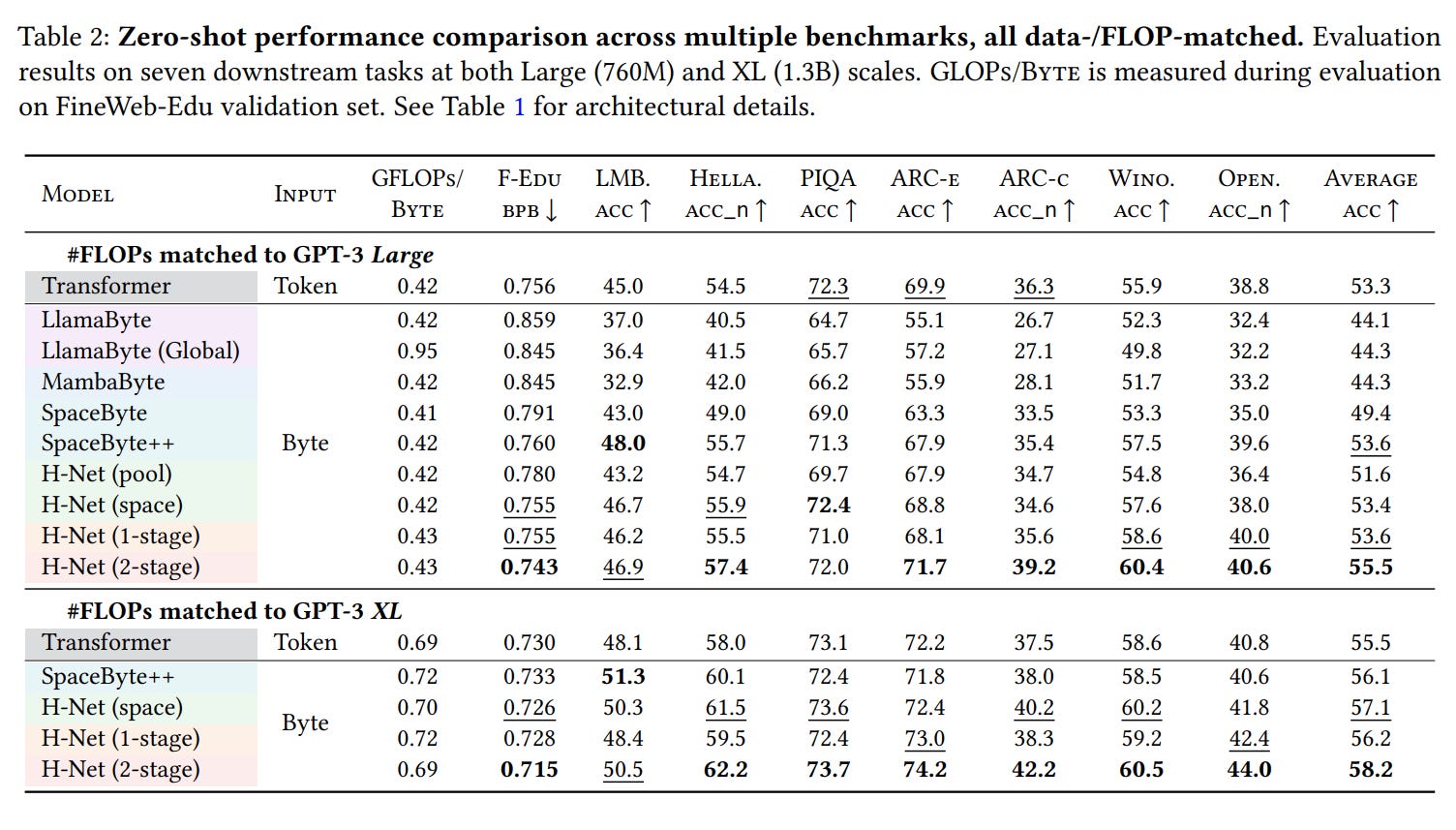
Surpassing Tokenized Models: When matched for compute, a 2-stage H-Net surpasses the performance of a strong BPE-tokenized Transformer after just 30B training bytes, and the performance gap continues to widen with more data. On downstream tasks, the 2-stage XL-sized H-Net outperforms its tokenized counterpart, and the Large model even matches the performance of the XL tokenized Transformer—effectively achieving superior results with half the parameters (Table 2).

Radical Robustness and Generalization: H-Net demonstrates significantly enhanced robustness to character-level noise compared to token-based models (Table 3).

The benefits become even more pronounced in contexts where traditional tokenization is weak.
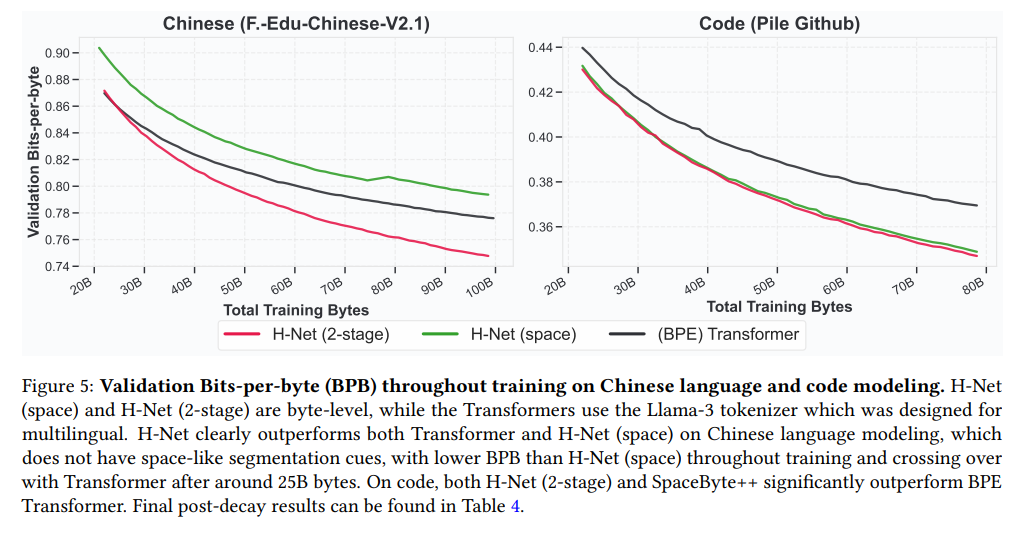
On Chinese text, code, and DNA sequences, H-Net shows substantially better performance and data efficiency—in the case of DNA modeling, it achieves the same perplexity as an isotropic baseline with nearly 4x less data (Figure 6).

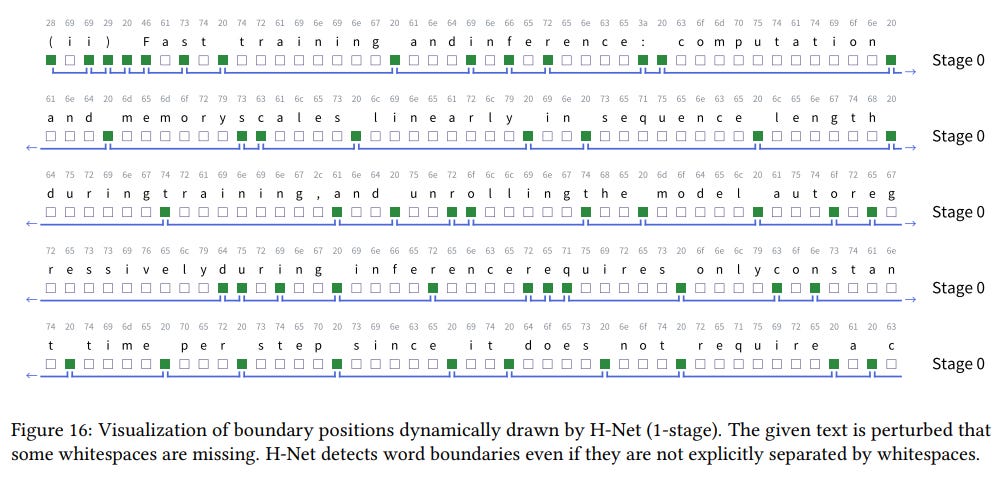
Learning Meaningful Representations: Qualitative visualizations reveal that H-Net learns to identify semantically coherent units without any explicit supervision (Figure 4).

It correctly places boundaries at whitespaces, but can also group multiple words into a single semantic chunk (e.g., "the backbone") or identify word boundaries even when spaces are missing (Figure 16). This provides strong evidence that the model is learning meaningful, context-aware segmentation.





Ablation studies further reinforce the design choices. The smoothing module is shown to be essential for stable training (Figure 7), and the use of Mamba layers in the encoder/decoder is proven to be significantly more effective than Transformers for compressing byte-level data (Figure 8).

Interestingly, a comparison to a Mixture-of-Experts (MoE) model shows that H-Net's approach to sparsity is fundamentally different and more powerful. While MoE provides a form of generic conditional computation, H-Net learns semantically meaningful, data-driven sparsity. It doesn’t just learn to skip computation; it learns what parts of the data are meaningful enough to merit computation, a more sophisticated and effective scaling strategy (Figure 12).

Limitations and Future Horizons
The authors are transparent about the current limitations of their work. The dynamic nature of H-Net makes the current implementation about twice as slow as an isotropic model during training and introduces memory management complexities. While the architecture shows excellent scaling up to the ~1.6B parameter range, its stability and performance at even larger scales remain an open question for future work.
The path forward is clear and exciting. The authors suggest exploring deeper hierarchies, improving distillation techniques, and further refining the architecture. The H-Net framework is not just a model but a new design paradigm, opening up research directions in dynamic state allocation for long-context models and providing a more universal backbone for general-purpose AI.
Conclusion
This paper presents a well-executed and highly significant contribution to the field of sequence modeling. H-Net and its dynamic chunking mechanism offer a powerful and principled solution to the long-standing problem of fixed tokenization. By demonstrating superior performance, scalability, robustness, and generalizability, the work provides a compelling roadmap for a future where foundation models learn truly end-to-end from raw data. This is a must-read for anyone interested in the architectural future of AI.